Cách Cursor lập chỉ mục Codebase nhanh chóng
Cursor, một AI IDE nổi tiếng vừa công bố đạt doanh thu $300M ARR, sử dụng Merkle Tree để lập chỉ mục code nhanh chóng. Bài viết này sẽ đi sâu vào cách họ thực hiện điều đó.
Trước khi đi sâu vào cách Cursor triển khai, hãy cùng tìm hiểu Merkle Tree là gì nhé.
Merkle Tree – Giải thích đơn giản
Merkle Tree là một cấu trúc cây trong đó mỗi nút "lá" (leaf node) được gán nhãn bằng hàm băm mật mã (cryptographic hash) của một khối dữ liệu, và mỗi nút không phải lá (non-leaf node) được gán nhãn bằng hàm băm mật mã của các nhãn từ các nút con của nó. Cấu trúc phân cấp này cho phép phát hiện thay đổi ở bất kỳ cấp độ nào một cách hiệu quả bằng cách so sánh các giá trị hash.
Hãy hình dung Merkle Tree như một hệ thống "lấy dấu vân tay" cho dữ liệu:
- Mỗi phần dữ liệu (ví dụ: một file) sẽ có một "dấu vân tay" (hash) độc nhất.
- Các cặp "dấu vân tay" này được kết hợp lại để tạo ra một "dấu vân tay" mới.
- Quá trình này tiếp diễn cho đến khi bạn chỉ còn một "dấu vân tay" tổng thể duy nhất (gọi là root hash).
Root hash tóm tắt toàn bộ dữ liệu chứa trong từng phần riêng lẻ, đóng vai trò như một cam kết mật mã (cryptographic commitment) cho toàn bộ tập dữ liệu. Vẻ đẹp của phương pháp này nằm ở chỗ, nếu bất kỳ phần dữ liệu nào thay đổi, nó sẽ làm thay đổi tất cả các "dấu vân tay" phía trên nó, và cuối cùng là thay đổi cả root hash.

Cách Cursor sử dụng Merkle Tree để lập chỉ mục Codebase
Cursor sử dụng Merkle Tree làm thành phần cốt lõi cho tính năng lập chỉ mục Codebase của mình. Theo một bài đăng của người sáng lập Cursor và tài liệu bảo mật, đây là cách nó hoạt động:
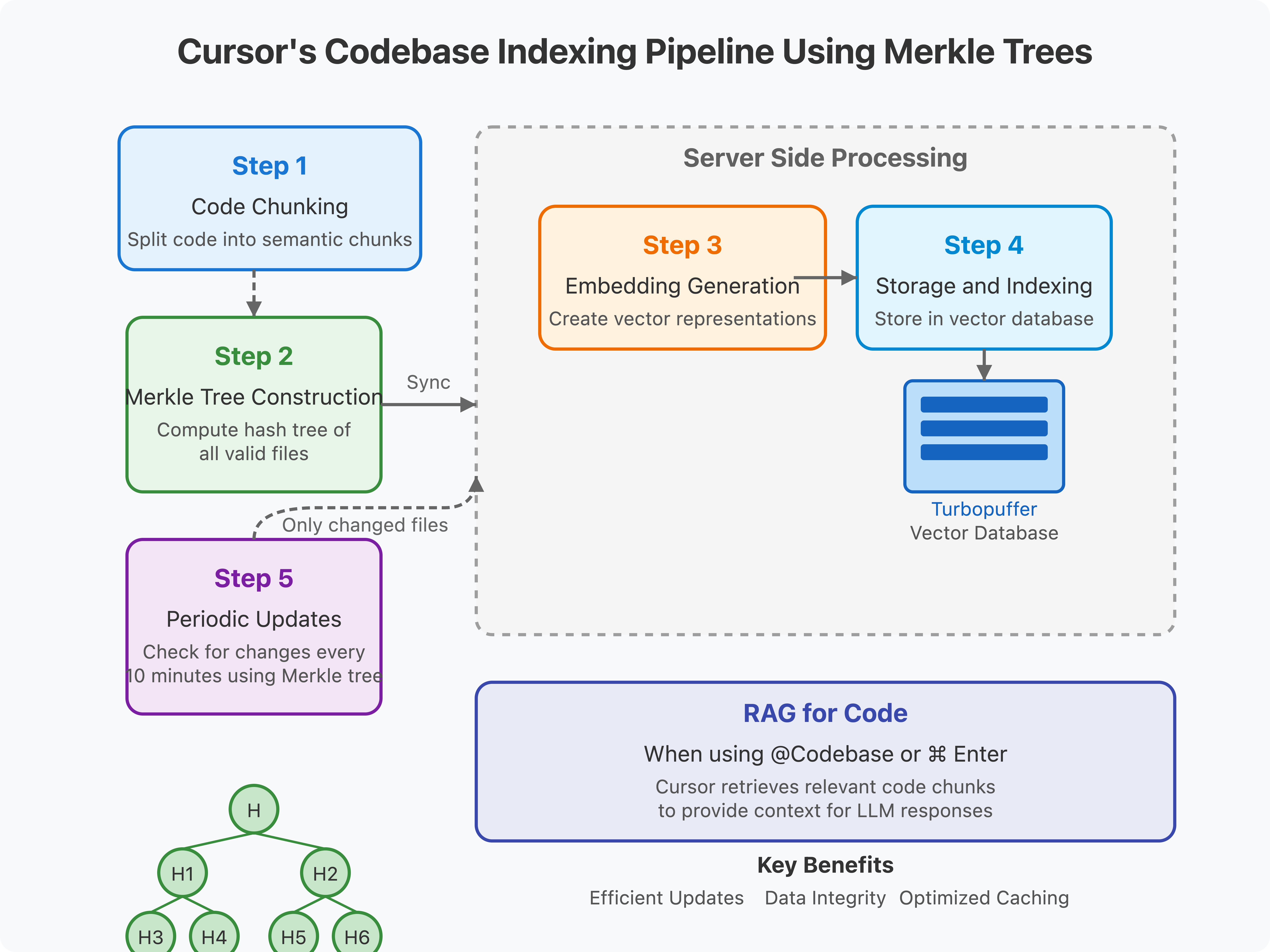
Bước 1: Chia nhỏ Code (Chunking) và xử lý
Cursor trước tiên sẽ chia nhỏ (chunk) các file trong codebase của bạn ngay trên máy tính cục bộ, phân tách code thành các phần có ý nghĩa ngữ nghĩa trước khi bất kỳ quá trình xử lý nào diễn ra.
Bước 2: Xây dựng và đồng bộ hóa Merkle Tree
Khi tính năng lập chỉ mục Codebase được kích hoạt, Cursor sẽ quét thư mục đang mở trong editor và tính toán một Merkle Tree từ các hash của tất cả các file hợp lệ. Merkle Tree này sau đó được đồng bộ hóa với server của Cursor, như đã được mô tả chi tiết trong tài liệu bảo mật của Cursor.
Bước 3: Tạo Embedding
Sau khi các chunk được gửi đến server của Cursor, các embedding sẽ được tạo ra bằng cách sử dụng API embedding của OpenAI hoặc một mô hình embedding tùy chỉnh (tôi chưa thể xác minh điều này). Các biểu diễn vector này sẽ nắm bắt ý nghĩa ngữ nghĩa của các chunk code.
Bước 4: Lưu trữ và lập chỉ mục
Các embedding, cùng với metadata như số dòng bắt đầu/kết thúc và đường dẫn file, được lưu trữ trong một vector database từ xa (Turbopuffer). Để duy trì quyền riêng tư trong khi vẫn cho phép lọc theo đường dẫn, Cursor lưu trữ một đường dẫn file tương đối đã được làm mờ (obfuscated relative file path) cùng với mỗi vector. Quan trọng hơn, theo người sáng lập Cursor, "Không có đoạn code nào của bạn được lưu trữ trong database của chúng tôi. Nó sẽ biến mất sau khi yêu cầu được xử lý xong."
Bước 5: Cập nhật định kỳ bằng Merkle Tree
Cứ mỗi 10 phút, Cursor sẽ kiểm tra các hash không khớp (hash mismatches), sử dụng Merkle Tree để xác định những file nào đã thay đổi. Chỉ những file đã thay đổi mới cần được tải lên, giúp giảm đáng kể mức sử dụng băng thông, như đã giải thích trong tài liệu bảo mật của Cursor. Đây chính là nơi cấu trúc Merkle Tree thể hiện giá trị lớn nhất của nó—cho phép cập nhật gia tăng (incremental updates) hiệu quả.
Các chiến lược chia nhỏ Code (Code Chunking Strategies)
Hiệu quả của việc lập chỉ mục codebase phần lớn phụ thuộc vào cách code được chia nhỏ (chunk). Mặc dù giải thích trước đó của tôi chưa đi sâu vào các phương pháp chunking, nhưng bài blog post này về xây dựng tính năng codebase tương tự Cursor có đưa ra một số thông tin chi tiết thú vị:
Trong khi các phương pháp đơn giản chỉ chia code theo ký tự, từ hoặc dòng, chúng thường bỏ qua các ranh giới ngữ nghĩa—dẫn đến chất lượng embedding bị giảm sút.
- Bạn có thể chia code dựa trên số lượng token cố định, nhưng điều này có thể cắt đứt các khối code như hàm (functions) hoặc lớp (classes) ở giữa chừng.
- Một phương pháp hiệu quả hơn là sử dụng một bộ chia thông minh (intelligent splitter) có khả năng hiểu cấu trúc code, chẳng hạn như các bộ chia văn bản đệ quy (recursive text splitters) sử dụng các dấu phân cách cấp cao (ví dụ: định nghĩa lớp và hàm) để chia tại các ranh giới ngữ nghĩa phù hợp.
- Một giải pháp tinh tế hơn nữa là chia code dựa trên cấu trúc Cây cú pháp trừu tượng (Abstract Syntax Tree - AST) của nó. Bằng cách duyệt AST theo chiều sâu (depth-first), nó sẽ chia code thành các cây con (sub-tree) phù hợp với giới hạn token. Để tránh tạo quá nhiều chunk nhỏ, các nút anh em (sibling nodes) sẽ được gộp vào các chunk lớn hơn miễn là chúng vẫn nằm trong giới hạn token. Các công cụ như tree-sitter có thể được sử dụng cho việc phân tích cú pháp AST này, hỗ trợ nhiều loại ngôn ngữ lập trình.
Cách các Embedding được sử dụng tại thời điểm suy luận (Inference Time)
Sau khi đã tìm hiểu cách Cursor tạo và lưu trữ các code embedding, một câu hỏi tự nhiên sẽ nảy sinh: các embedding này thực sự được sử dụng như thế nào sau khi chúng đã được tạo ra? Phần này sẽ giải thích ứng dụng thực tế của các embedding này trong quá trình sử dụng thông thường.
Tìm kiếm ngữ nghĩa và Truy xuất ngữ cảnh (Semantic Search and Context Retrieval)
Khi bạn tương tác với các tính năng AI của Cursor, chẳng hạn như đặt câu hỏi về codebase của mình (sử dụng @Codebase hoặc ⌘ Enter), quá trình sau sẽ diễn ra:
- Tạo Embedding truy vấn (Query Embedding): Cursor sẽ tính toán một embedding cho câu hỏi của bạn hoặc cho ngữ cảnh code mà bạn đang làm việc.
- Tìm kiếm tương đồng Vector (Vector Similarity Search): Embedding truy vấn này được gửi đến Turbopuffer (vector database của Cursor), nơi thực hiện tìm kiếm hàng xóm gần nhất (nearest-neighbor search) để tìm các chunk code có ý nghĩa ngữ nghĩa tương tự với truy vấn của bạn.
- Truy cập File cục bộ: Client của Cursor nhận kết quả, bao gồm các đường dẫn file đã được làm mờ và phạm vi dòng của các chunk code liên quan nhất. Điều quan trọng là, nội dung code thực tế vẫn nằm trên máy của bạn và được truy xuất cục bộ.
- Tập hợp ngữ cảnh (Context Assembly): Client đọc các chunk code liên quan này từ các file cục bộ của bạn và gửi chúng dưới dạng ngữ cảnh (context) đến server để LLM xử lý cùng với câu hỏi của bạn.
- Phản hồi thông minh: LLM giờ đây đã có ngữ cảnh cần thiết từ codebase của bạn để cung cấp câu trả lời chính xác và phù hợp hơn cho câu hỏi của bạn hoặc để tạo ra các đoạn code hoàn chỉnh thích hợp.
Khả năng truy xuất được hỗ trợ bởi embedding này cho phép:
- Tạo code theo ngữ cảnh (Contextual Code Generation): Khi viết code mới, Cursor có thể tham chiếu các cách triển khai tương tự trong codebase hiện có của bạn, giúp duy trì các mẫu và phong cách nhất quán.
- Hỏi đáp Codebase (Codebase Q&A): Bạn có thể đặt câu hỏi về codebase của mình và nhận được câu trả lời dựa trên code thực tế của bạn, thay vì các phản hồi chung chung.
- Tự động hoàn thành code thông minh (Smart Code Completion): Các tính năng tự động hoàn thành code có thể được nâng cao nhờ khả năng nhận biết các quy ước và mẫu đặc trưng của dự án bạn.
- Tái cấu trúc code thông minh (Intelligent Refactoring): Khi tái cấu trúc code, hệ thống có thể xác định tất cả các phần liên quan trong toàn bộ codebase của bạn có thể cần những thay đổi tương tự.
Tại sao Cursor sử dụng Merkle Tree
Nhiều chi tiết trong số này liên quan đến bảo mật và do đó có thể được tìm thấy trong tài liệu bảo mật của Cursor.
1. Cập nhật gia tăng hiệu quả
Bằng cách sử dụng Merkle Tree, Cursor có thể nhanh chóng xác định chính xác những file nào đã thay đổi kể từ lần đồng bộ hóa cuối cùng. Thay vì tải lại toàn bộ codebase, nó chỉ cần tải lên các file cụ thể đã được sửa đổi. Điều này rất quan trọng đối với các codebase lớn, nơi việc lập chỉ mục lại mọi thứ sẽ tốn kém quá nhiều băng thông và thời gian xử lý.
2. Xác minh tính toàn vẹn dữ liệu
Cấu trúc Merkle Tree cho phép Cursor xác minh hiệu quả rằng các file đang được lập chỉ mục khớp với những gì được lưu trữ trên server. Cấu trúc hash phân cấp giúp dễ dàng phát hiện bất kỳ sự không nhất quán hoặc dữ liệu bị hỏng trong quá trình truyền tải.
3. Tối ưu hóa Cache
Cursor lưu trữ các embedding trong một cache được lập chỉ mục bằng hash của chunk, đảm bảo rằng việc lập chỉ mục cùng một codebase lần thứ hai sẽ nhanh hơn rất nhiều. Điều này rất hữu ích cho các nhóm mà nhiều nhà phát triển có thể đang làm việc với cùng một codebase.
4. Lập chỉ mục bảo vệ quyền riêng tư
Để bảo vệ thông tin nhạy cảm trong đường dẫn file, Cursor triển khai tính năng làm mờ đường dẫn (path obfuscation) bằng cách chia đường dẫn theo các ký tự '/' và '.' và mã hóa từng phân đoạn bằng một khóa bí mật được lưu trữ trên client. Mặc dù điều này vẫn tiết lộ một số thông tin về cấu trúc thư mục, nhưng nó che giấu hầu hết các chi tiết nhạy cảm.
5. Tích hợp lịch sử Git
Khi tính năng lập chỉ mục codebase được bật trong một Git repository, Cursor cũng lập chỉ mục lịch sử Git. Nó lưu trữ các commit SHA, thông tin parent, và các tên file đã được làm mờ. Để cho phép chia sẻ cấu trúc dữ liệu cho những người dùng trong cùng một Git repo và cùng một nhóm, khóa bí mật để làm mờ tên file được lấy từ các hash của nội dung commit gần đây.
Các mô hình Embedding và những lưu ý
Việc lựa chọn mô hình embedding có tác động đáng kể đến chất lượng tìm kiếm và hiểu code. Trong khi một số hệ thống sử dụng các mô hình mã nguồn mở như all-MiniLM-L6-v2, Cursor có thể sử dụng các mô hình embedding của OpenAI hoặc các mô hình embedding tùy chỉnh được tinh chỉnh đặc biệt cho code. Đối với các embedding code chuyên biệt, các mô hình như unixcoder-base của Microsoft hoặc voyage-code-2 của Voyage AI là những lựa chọn tốt cho việc hiểu ngữ nghĩa code chuyên sâu.
Thử thách về embedding trở nên phức tạp hơn vì các mô hình embedding có giới hạn token. Ví dụ, mô hình text-embedding-3-small của OpenAI có giới hạn 8192 token. Việc chia chunk hiệu quả giúp duy trì trong giới hạn token mà vẫn bảo toàn ý nghĩa ngữ nghĩa.
Quy trình "bắt tay" (The Handshake Process)
Một khía cạnh quan trọng trong quá trình triển khai Merkle Tree của Cursor là quy trình "bắt tay" (handshake process) diễn ra trong quá trình đồng bộ hóa. Các bản ghi (logs) từ ứng dụng Cursor tiết lộ rằng khi khởi tạo việc lập chỉ mục codebase, Cursor tạo một "merkle client" và thực hiện "startup handshake" với server. Quá trình bắt tay này bao gồm việc gửi root hash của Merkle Tree đã được tính toán cục bộ đến server, như có thể thấy trong Issue #2209 trên GitHub và Issue #981 trên GitHub.
Quy trình bắt tay cho phép server xác định những phần nào của codebase cần được đồng bộ hóa. Dựa trên các bản ghi handshake, chúng ta có thể thấy rằng Cursor tính toán hash ban đầu của codebase và gửi nó đến server để xác minh, như đã được ghi lại trong Issue #2209 trên GitHub.
Thách thức triển khai kỹ thuật
Mặc dù phương pháp Merkle Tree mang lại nhiều lợi ích, nhưng nó không phải không có những thách thức trong triển khai. Tính năng lập chỉ mục của Cursor thường xuyên phải chịu tải trọng lớn, gây ra việc nhiều yêu cầu bị lỗi. Điều này có thể dẫn đến việc các file cần được tải lên nhiều lần trước khi chúng được lập chỉ mục hoàn toàn. Người dùng có thể nhận thấy lưu lượng mạng đến 'repo42.cursor.sh' cao hơn dự kiến do các cơ chế thử lại này, như đã đề cập trong tài liệu bảo mật của Cursor.
Một thách thức khác liên quan đến bảo mật embedding. Nghiên cứu học thuật đã chỉ ra rằng việc đảo ngược embedding (reversing embeddings) là có thể trong một số trường hợp. Mặc dù các cuộc tấn công hiện tại thường dựa vào việc truy cập mô hình embedding và làm việc với các chuỗi ngắn, nhưng vẫn có rủi ro tiềm ẩn rằng kẻ tấn công có quyền truy cập vào vector database của Cursor có thể trích xuất thông tin về các codebase đã được lập chỉ mục từ các embedding đã lưu trữ.