Hiện nay có rất nhiều công ty cung cấp và tự nghiên cứu các giải pháp để dự đoán bất thường để đưa ra cảnh báo; nhưng với một người System Admin bình thường, tại một công ty bình thường thì để mua giải pháp hoặc nghiên cứu một cách chuyên sâu rất hiếm khi xảy ra.
Tuy nhiên vẫn có một số cách để những người System Admin như mình có thể trải nghiệm một chút "nhận biết sự bất thường" một cách miễn phí, Gitlab đã đưa ra một giải pháp xác định cảnh báo bất thường trên Prometheus và chúng ta sẽ cùng tìm hiểu giải pháp đó trong bài viết này.
Trong giới hạn của bài viết này, mình sẽ chỉ giới hạn sự bất thường bằng các sự kiện không có tính chu kỳ (Seasonality) - thứ gặp khá nhiều trong quá trình vận hành hệ thống.
Lợi ích
Vậy thì chúng ta sẽ có lợi ích gì khi nhận biết được sự bất thường của hệ thống:
Loại bỏ những cảnh báo có tính chu kỳ
Nếu một cảnh báo lặp đi lặp lại mà không gây ảnh hưởng đến hệ thống -> ta sẽ coi như cảnh báo này bị dư thừa và có tính bình thường. Cảnh báo dư thừa có thể khiến kênh cảnh báo của bạn bị spam, nhiễu loạn làm chúng ta lỡ những cảnh báo quan trọng. Nguy hiểm hơn, cảnh báo dư thừa diễn ra vào ban đêm có thể khiến giấc ngủ ngon (một điều rất quý giá) của người vận hành hệ thống bị phá hỏng.
Ví dụ
Hàng đêm bạn setup một job chạy vào 2h đêm cho một nghiệp vụ trên server, hàng đêm 2h chạy job sẽ có cảnh báo Warning ngưỡng CPU, và sau một số ngày theo dõi ta biết CPU sẽ giảm sau thời gian chạy job, không gây ảnh hưởng đến hệ thống. Để xử lý cảnh báo lúc 2h đêm này, nếu bỏ qua cách tăng CPU của server hoặc tối ưu job chạy, thì chỉ có cách tăng ngưỡng cảnh báo = giá trị Max khi chạy job của server. Cách này nhìn chung có thể thực hiện với 1 số server cụ thể, tuy nhiên nếu bài toán xảy ra với số lượng lớn về số lượng server và nhiều loại cảnh báo sẽ khiến người vận hành rất "to tay".
Cải thiện điểm yếu của các cảnh báo cận trên, cận dưới
Khi sử dụng Prometheus, chúng ta thường sẽ đặt các cảnh báo với các mức cận trên hoặc cận dưới. Nhưng có một số loại metrics nếu chỉ dùng cận trên và cận dưới là chưa đủ.
Ví dụ
Bạn có một trang web và thực hiện giám sát số lượng người truy cập vào trang web của bạn. Sau 2 tháng giám sát, ta thấy số lượng người truy cập có tính chu kỳ từ ~2000 người truy cập vào 10-11h sáng hàng ngày. Để tránh hiện tượng DDOS, ta đặt ngưỡng cảnh báo số người truy cập lớn khi số lượng >= 2100. Mọi thứ đều ổn định cho đến một đêm trang web của bạn đã "gone away" sau một trận DDOS trong khi cảnh báo số người truy cập không được cảnh báo. Do buổi đêm số lượng người truy cập ít, nên khi bị DDOS với số lượng thấp hơn ngưỡng cảnh báo (2100) sẽ khiến hệ thống không phát hiện được. Sự kiện số lượng người truy cập vào ban đêm nhiều trong trường hợp này sẽ có tính bất thuờng
Khái niệm Độ lệch chuẩn và Phân phối chuẩn
Độ lệch chuẩn, hay độ lệch tiêu chuẩn là một đại lượng thống kê mô tả dùng để đo mức độ phân tán của một tập dữ liệu đã được lập thành bảng tần số. (trích wikipedia) Phân phối chuẩn, còn gọi là phân phối Gauss hay (Hình chuông Gauss), là một phân phối xác suất cực kì quan trọng trong nhiều lĩnh vực. (trích wikipedia)
Áp dụng công thức Gauss với PromQL
- Bắt tay vào thực hiện, ta có metrics node_load1 dưới dạng PromQL được biểu diễn bằng câu query dưới đây, tạm gọi đây là giá trị thực của metrics:
node_load1{instance="${instance}"}
- Tiếp theo để tìm được phương sai ta sẽ sử dụng hàm stddev_over_time của giá trị thực tính trong một khoảng thời gian mà ta coi như là 1 chu kì:
stddev_over_time(node_load1{instance=~"${instance}"}[khoảng thời gian lấy mẫu]
- Tiếp đến giá trị trung bình khi độ lệch chuẩn bằng 0, sẽ sử dụng hàm avg_over_time cũng với khoảng thời gian mà ta coi như là 1 chu kì:
avg_over_time(node_load1{instance="${instance}"}[khoảng thời gian lấy mẫu]
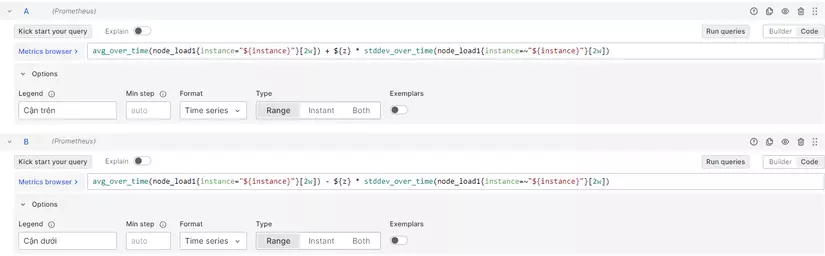
- Cuối cùng sử dụng độ lệch chuẩn để tìm ra cận trên và cận dưới mà ta coi là bình thường.
# Cận trên
avg_over_time(node_load1{instance="${instance}"}[khoảng thời gian lấy mẫu]) + độ lệch chuẩn * stddev_over_time(node_load1{instance=~"${instance}"}[khoảng thời gian lấy mẫu])
# Cận dưới
avg_over_time(node_load1{instance="${instance}"}[khoảng thời gian lấy mẫu]) - độ lệch chuẩn * stddev_over_time(node_load1{instance=~"${instance}"}[khoảng thời gian lấy mẫu])
Hiển thị trên Grafana
Giá trị của độ lệch chuẩn các bạn sẽ lựa chọn sao cho phù hợp nhất với các metrics lấy được trước đó, để trực quan nhất ta sẽ vẽ lên Grafana để xem kết quả.
Đặt biến cho Độ lệch chuẩn
Tuỳ chỉnh Độ lệch chuẩn theo metric hiện tại, ví dụ đang để giá trị là 3
Điền hàm tính cận trên và cận dưới
Tuỳ chỉnh thời gian lấy mẫu, ví dụ đang để giá trị 2 tuần
Điền hàm tính giá trị trung bình
Điền hàm hiển thị data hiện tại
Làm đẹp đồ thị
Vậy ta có thể thấy các metrics nằm ngoài khoảng màu xanh sẽ được coi như có tính bất thường
Kết luận
Vậy là ta đã có một dashboard grafana hiển thị sự bất thường nhưng chỉ với chu kì 1 tuần, vậy với sự bất thường có chu kỳ lớn hơn 1 tuần như các dịp ngày lễ, tết.