Bối cảnh
Với sự gia tăng đột biến trong lượng người dùng và lưu lượng truy cập, duy trì hiệu suất và độ tin cậy của hệ thống trở thành một thách thức ngày càng lớn. Trong tình hình này, việc triển khai một chiến lược scale-out hiệu quả trở nên cực kỳ quan trọng để đảm bảo rằng Viblo có thể đáp ứng nhu cầu ngày càng tăng về khả năng mở rộng và xử lý tải.
Đối mặt với sự gia tăng đột biến trong lượng truy cập, Viblo không chỉ cần xem xét vấn đề về tăng cường phần cứng mà còn cần tập trung vào các giải pháp phần mềm và cơ sở hạ tầng mạng. Việc áp dụng một chiến lược scale-out thông minh không chỉ giúp tăng khả năng chịu tải mà còn đảm bảo sự linh hoạt và hiệu suất cao đối với các ứng dụng và dịch vụ của Viblo. Trong bài viết này, chúng tôi sẽ chia sẻ chi tiết về chiến lược này và cách nó có thể được triển khai một cách hiệu quả để đáp ứng với thách thức ngày càng tăng của lượng truy cập.
Phân tích nhu cầu và dự đoán tăng trưởng
Thu thập dữ liệu: Bắt đầu bằng việc thu thập dữ liệu về hoạt động của hệ thống trong quá khứ, bao gồm lượng truy cập, số lượng người dùng, tải trang, và các chỉ số hiệu suất khác. Dữ liệu này có thể được thu thập từ các logs hệ thống, công cụ giám sát, và các cơ sở dữ liệu.
Phân tích dữ liệu hiện tại: Sử dụng dữ liệu đã thu thập để hiểu rõ hơn về mô hình tăng trưởng hiện tại của hệ thống. Điều này bao gồm việc xác định các mẫu tăng trưởng, các yếu tố ảnh hưởng đến sự tăng trưởng, và các vấn đề hiệu suất hiện tại của hệ thống.
Xác định yếu tố ảnh hưởng: Xác định các yếu tố ngoại lệ và yếu tố ảnh hưởng đến tăng trưởng của hệ thống, bao gồm các sự kiện như sự kiện lớn trong năm của Viblo, sự kiện cộng đồng, và xu hướng công nghệ mới,...
Dự đoán tăng trưởng: Dựa vào dữ liệu và thông tin thu thập được, sử dụng các phương pháp dự đoán như mô hình hồi quy, mạng nơ-ron, hoặc phương pháp thống kê để dự đoán tăng trưởng của hệ thống trong tương lai. Điều này có thể bao gồm việc tạo ra các mô hình dự đoán dựa trên dữ liệu lịch sử và các yếu tố ảnh hưởng.
Xác định ngưỡng bão hòa: Xác định ngưỡng tối đa mà hệ thống có thể chịu được trước khi cần phải mở rộng. Điều này giúp xác định các điểm mốc quan trọng và kế hoạch mở rộng trong tương lai.
Kiểm thử hiệu năng (Performance Testing)
Performance testing là một loại kiểm thử phần mềm được thực hiện để đánh giá hiệu suất của một ứng dụng hoặc hệ thống dưới một tải trọng nhất định. Mục tiêu chính của performance testing là đảm bảo rằng ứng dụng hoặc hệ thống có thể hoạt động với hiệu suất cao và đáp ứng được yêu cầu của người dùng dưới tải tối đa hoặc dưới điều kiện tải đa dạng.
Có rất nhiều testing tools có thể sử dụng:
- K6 (https://k6.io)
- Jmeter
- Autocannon
- Bombardier
- SlowHTTPTest
- Tsung
- Drill
- Cassowary
- H2load
- ...
Tại Viblo, chúng tôi tự phát triển một hệ thống chạy performance testing với việc implement K6 Operator. Một số khái niệm cần nắm rõ trước khi bạn đọc tiếp phần bên dưới:
- REQUEST MADE: tổng số lượng các yêu cầu HTTP đã được gửi đi từ kịch bản thử nghiệm bao gồm cả các yêu cầu thành công và thất bại.
- HTTP FAILURES RATE: tỷ lệ yêu cầu HTTP thất bại trong suốt quá trình thử nghiệm.
- PEAK RPS (Peak Requests Per Second): số lượng yêu cầu tối đa được gửi đến hệ thống trong một giây.
- P95 RESPONSE TIME: 95% các yêu cầu đã hoàn thành dưới một ngưỡng thời gian cụ thể.
- P99 RESPONSE TIME: 99% các yêu cầu đã hoàn thành dưới một ngưỡng thời gian cụ thể.
Ví dụ: Nếu một ứng dụng có P95 response time là 500ms, điều này có nghĩa là 95% các yêu cầu được xử lý trong 500ms hoặc ít hơn. Có thể hiểu rằng P95 response time là một thước đo về hiệu suất của hệ thống trong điều kiện tải trọng cao, và nó thường được sử dụng để đánh giá trải nghiệm người dùng trong thời gian thực.
Việc quyết định sử dụng P95 hoặc P99 phụ thuộc vào các yếu tố như mục tiêu hiệu suất, đặc điểm của ứng dụng hoặc hệ thống, phân phối dữ liệu và yêu cầu của người dùng. Ví dụ: một ứng dụng giao dịch tài chính có thể đặt mục tiêu là P99 phải đảm bảo rằng 99% các giao dịch được xử lý một cách nhanh chóng để đảm bảo trải nghiệm tích cực cho người dùng.
- MAX VUs: số lượng người dùng ảo (virtual users - VUs) tối đa của kịch bản thử nghiệm
Lưu ý các kết quả kiểm thử bên dưới có thể thay đổi tùy thuộc vào hiệu suất của mã nguồn, tài nguyên hệ thống như CPU và bộ nhớ được cung cấp cho ứng dụng. Bên cạnh đó Viblo cũng lấy cơ sở từ lượng traffic thực tế để lựa chọn tùy chỉnh và đánh giá kết quả các bài kiểm tra.
Load Testing
Là một loại kiểm thử phần mềm được thực hiện để đánh giá hiệu suất của một ứng dụng hoặc hệ thống dưới một tải trọng nhất định. Mục tiêu của load testing là đánh giá và xác định khả năng của hệ thống trong việc chịu được tải trọng cao nhất mà vẫn duy trì được hiệu suất ổn định. Điều này giúp phát hiện và giải quyết các vấn đề liên quan đến hiệu suất như giảm tốc độ phản hồi, tăng thời gian phản hồi, hoặc thậm chí là sự sụp đổ của hệ thống trước khi nó ảnh hưởng đến trải nghiệm người dùng.
Trong bài kiểm tra đầu tiên, chúng tôi thực hiện kiểm tra hiệu năng cho trang chủ Viblo, với mục tiêu là đảm bảo rằng P95 response time không vượt quá ngưỡng (threshold) 500ms. Kết quả thu được là PEAK RPS lên đến gần 120 reqs/s.
Chúng tôi cũng đã tiến hành nhiều bài test để xác định lượng PEAK RPS (reqs/s) và số lượng pod với tài nguyên phù hợp để đạt được mục tiêu đề ra. Ví dụ, để đạt được P95 response time dưới 500ms với 120 reqs/s, chúng tôi đã xác định cần khoảng 2 pod (mỗi pod với 1 Virtual CPU và 1 Gi memory). Dựa vào những thông số này, chúng tôi có cơ sở để phát triển chiến lược scale-out như mô tả ở phần bên dưới.
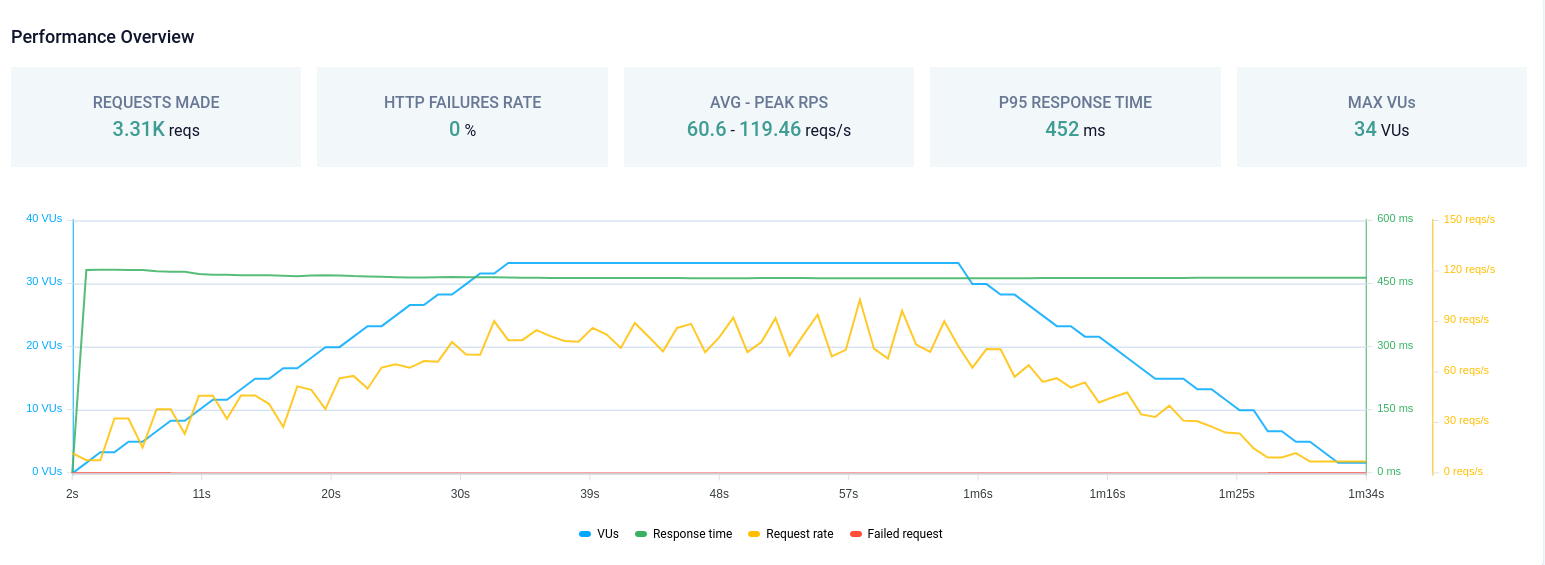
Kiểm thử load testing trang chủ Viblo.
Việc kiểm tra các ngưỡng P95 response time này sẽ giúp chúng tôi biết được rằng để hệ thống luôn đạt được hiệu suất cao, trải nghiệm người dùng luôn tốt thì cần duy trì cấu hình hạ tầng như thế nào.
Stress Testing
Là một loại kiểm thử phần mềm được thực hiện để đánh giá khả năng của một ứng dụng hoặc hệ thống chịu được áp lực cực đoan, vượt quá giới hạn dự kiến của nó. Mục tiêu chính của stress testing là xác định điểm bão hòa hoặc các điểm yếu của hệ thống dưới áp lực cực đoan.
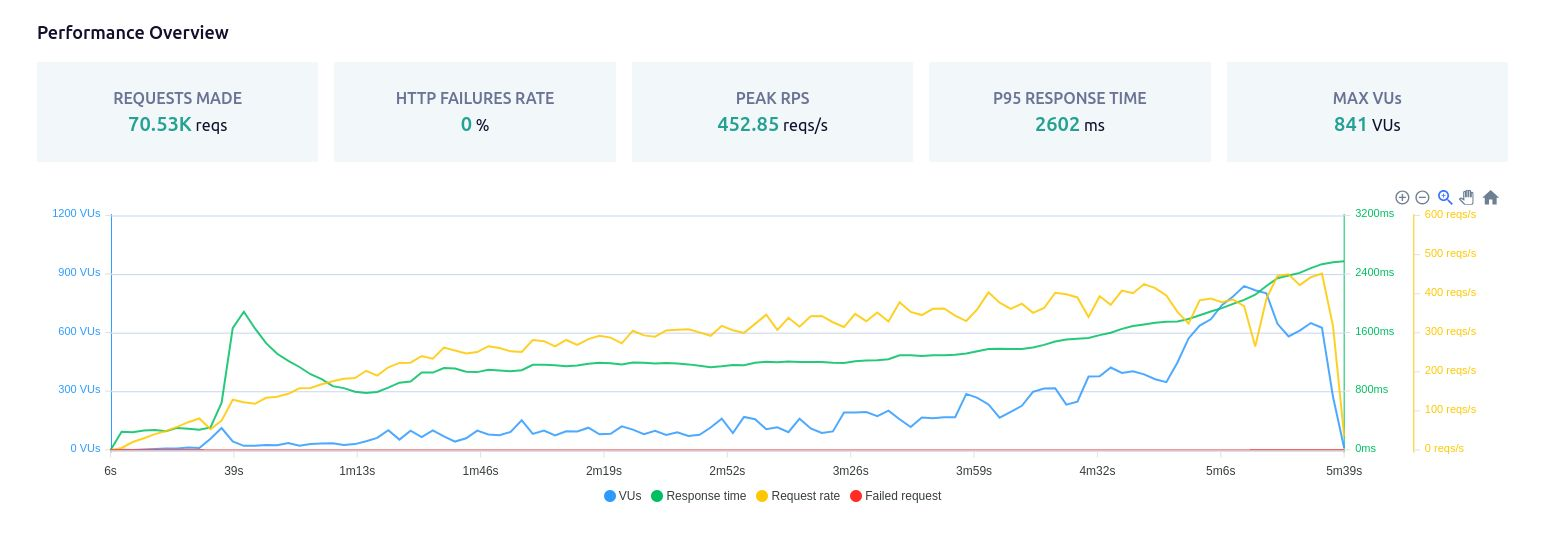
Kiểm thử stress testing trang chủ Viblo.
Spike Testing
Là một loại kiểm thử phần mềm được thực hiện để đánh giá khả năng của một ứng dụng hoặc hệ thống chịu được tải trọng đột ngột tăng cao trong một khoảng thời gian ngắn. Mục tiêu chính của spike testing là đo lường và đánh giá hiệu suất của hệ thống trong điều kiện tải trọng đột ngột (spike) và xem xét phản ứng của nó dưới tải trọng không thường xuyên nhưng có thể xảy ra.
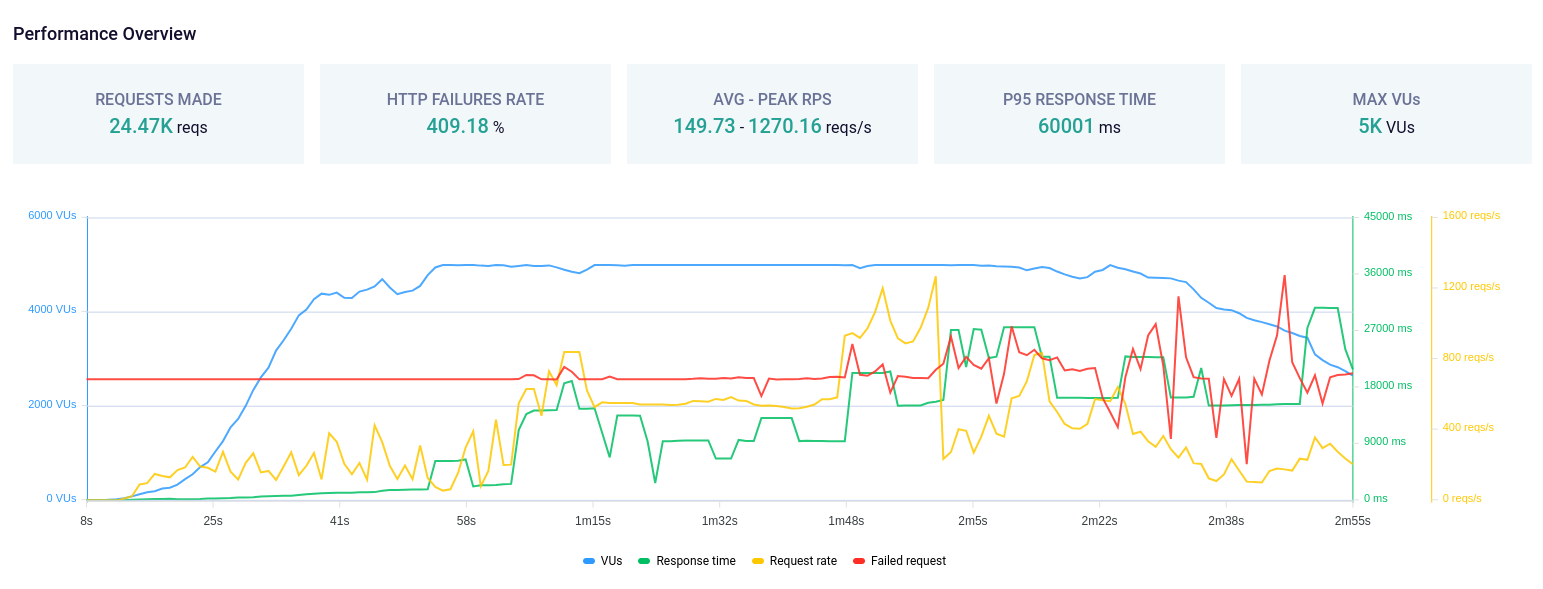
Kiểm thử spike testing trang chủ Viblo.
Việc chạy kiểm thử hiệu năng như trên được Viblo thực hiện định kỳ để đảm bảo rằng việc thêm các dòng mã nguồn mới, kiến trúc mới vẫn đảm bảo hiệu năng dịch vụ và không làm giảm chất lượng của ứng dụng. Các thông số từ kết quả kiểm thử sẽ là căn cứ để hệ thống xác định ngưỡng scale-out và đưa ra quyết định về việc mở rộng cơ sở hạ tầng khi cần thiết.
Thiết kế kiến trúc linh hoạt
Viblo xây dựng một kiến trúc linh hoạt cho hệ thống, cho phép dễ dàng mở rộng khi cần thiết. Sử dụng các công nghệ và khung kiến trúc như microservices, containerization và các dịch vụ đám mây, Viblo dần cải thiện với các thử nghiệm ứng dụng kiến trúc microservices, sẽ có những bài viết chia sẻ đến cộng đồng trong thời gian tới.
Bằng cách phân tách ứng dụng thành các thành phần độc lập và có thể mở rộng, Viblo có khả năng tăng cường và điều chỉnh hệ thống một cách hiệu quả để đáp ứng với nhu cầu người dùng ngày càng tăng. Đồng thời, việc sử dụng containerization và các dịch vụ đám mây giúp hệ thống linh hoạt và có khả năng di chuyển giữa các môi trường một cách dễ dàng, giảm thiểu sự phụ thuộc vào cơ sở hạ tầng cụ thể và tăng tính ổn định của ứng dụng.
Tích hợp giải pháp tự động hóa
Viblo sử dụng các công cụ tự động hóa để quản lý việc triển khai và quản lý hệ thống. Kubernetes có thể giúp tự động hóa việc mở rộng và quản lý cơ sở hạ tầng.
Vertical Scaling
Là việc tăng cường khả năng xử lý của một hệ thống bằng cách tăng cường tài nguyên trên một máy chủ đơn lẻ, thường là tăng dung lượng CPU, bộ nhớ, hoặc tăng tốc độ của ổ đĩa. Điều này giúp hệ thống có thể xử lý được lượng công việc lớn hơn hoặc tải trọng cao hơn.
Cơ chế mở rộng của Vertical Scaling.
Ưu điểm:
- Đơn giản triển khai: Thực hiện vertical scaling thường dễ dàng hơn so với việc phân chia hệ thống thành nhiều máy chủ nhỏ hơn.
- Hiệu suất tăng cường: Bằng cách cung cấp thêm tài nguyên cho máy chủ hiện có, bạn có thể cải thiện hiệu suất của hệ thống mà không cần phải thay đổi kiến trúc hoặc mã nguồn.
- Giảm chi phí quản trị: Chỉ cần quản lý và duy trì một máy chủ lớn hơn thay vì nhiều máy chủ nhỏ, điều này có thể giảm chi phí quản lý hệ thống.
Nhược điểm:
- Giới hạn về mức mở rộng: Khả năng tăng cường tài nguyên của một máy chủ không phải là vô hạn. Có một giới hạn về tài nguyên mà một máy chủ cụ thể có thể hỗ trợ.
- Sự rủi ro khi máy chủ gặp sự cố: Nếu máy chủ chính gặp sự cố, toàn bộ hệ thống có thể bị ảnh hưởng vì không có sự dự phòng hoặc phân tán công việc.
- Chi phí tăng cao: Mua các thành phần tăng cường cho một máy chủ có thể tăng chi phí đáng kể, đặc biệt là so với việc mở rộng bằng cách sử dụng nhiều máy chủ nhỏ hơn.
Horizontal Scaling
Là việc tăng cường khả năng xử lý của một hệ thống bằng cách thêm các máy chủ mới vào hệ thống thay vì tăng cường tài nguyên trên máy chủ hiện có. Điều này thường được thực hiện bằng cách triển khai các bản sao của ứng dụng hoặc dịch vụ trên nhiều máy chủ và sử dụng cơ chế phân phối công việc (load balancing) để phân phối công việc giữa các máy chủ.
Cơ chế mở rộng của Horizontal Scaling.
Ưu điểm:
- Khả năng mở rộng linh hoạt: Bạn có thể dễ dàng thêm máy chủ mới vào hệ thống để đáp ứng nhu cầu tăng cao hoặc giảm đi nhu cầu thấp.
- Khả năng chịu lỗi: Nếu một máy chủ gặp sự cố, hệ thống vẫn có thể tiếp tục hoạt động bằng cách chuyển công việc sang các máy chủ khác.
- Tính linh hoạt và mở rộng: Horizontal scaling có thể giúp phân tán tải trọng công việc, tăng tính ổn định và linh hoạt cho hệ thống.
Nhược điểm:
- Phức tạp hóa triển khai: Việc triển khai và quản lý nhiều máy chủ có thể phức tạp hơn so với việc chỉ quản lý một máy chủ lớn.
- Đòi hỏi cơ sở hạ tầng phần cứng và phần mềm phức tạp: Để triển khai horizontal scaling hiệu quả, bạn cần cơ sở hạ tầng phần cứng và phần mềm hỗ trợ cho việc phân phối công việc và quản lý máy chủ.
- Khó khăn trong việc đồng bộ hóa dữ liệu: Việc đồng bộ hóa dữ liệu giữa các máy chủ có thể là một thách thức đối với hệ thống horizontal scaling.
Cân nhắc giữa ưu và nhược điểm của hai hình thức mở rộng, kèm theo việc áp dụng các kỹ thuật giải quyết các bài toán của Horizontal Scaling, chúng tôi đã quyết định sử dụng Horizontal Scaling cho server và ứng dụng của mình.
Horizontal Pod Autoscaler (HPA)
Là một tính năng của Kubernetes (K8s) được sử dụng để tự động mở rộng hoặc thu hẹp số lượng Pod trong một Deployment, ReplicaSet hoặc StatefulSet dựa trên CPU, memory hoặc các metrics khác.
HPA hoạt động dựa trên các ngưỡng mà bạn thiết lập. Khi tải trên các Pod vượt quá ngưỡng trên, HPA sẽ tự động thêm các Pod mới. Ngược lại, khi tải giảm dưới ngưỡng dưới, HPA có thể thu hẹp số lượng Pod.
Cơ chể mở rộng của HPA.
Để sử dụng HPA, bạn cần cấu hình một số tham số như:
- CPU Utilization: HPA có thể đo lường tải CPU trung bình của các Pod và thực hiện mở rộng hoặc thu hẹp dựa trên ngưỡng CPU bạn thiết lập.
- Memory Utilization: HPA có thể đo lường tải Memory trung bình của các Pod và thực hiện mở rộng hoặc thu hẹp dựa trên ngưỡng Memory bạn thiết lập.
- Custom Metrics: Ngoài CPU, bạn cũng có thể sử dụng các metric tùy chỉnh (ví dụ: số lượng truy cập trong một giây) để điều chỉnh số lượng Pod.
- Tham số mở rộng: Bạn có thể cấu hình HPA để xác định số lượng tối đa và tối thiểu của các Pod, cũng như thời gian chờ trước khi thực hiện điều chỉnh kích thước.
Khi HPA được kích hoạt và cấu hình đúng, nó giúp tự động mở rộng hoặc thu hẹp các tài nguyên của ứng dụng mà không cần can thiệp thủ công từ người quản trị hệ thống. Điều này giúp tối ưu hóa sử dụng tài nguyên và đảm bảo hiệu suất ứng dụng trong môi trường Kubernetes.
Ví dụ: Ứng dụng web của Viblo cần scale từ 1 đến 20 replicas. Với điều kiện scale lên khi trung bình CPU và memory lớn hơn hoặc bằng 70%.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata: name: viblo-web
spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: viblo-web minReplicas: 1 maxReplicas: 20 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 - type: Resource resource: name: memory target: type: Utilization averageUtilization: 70
Web Scaling
Ứng dụng web scale-out theo ngưỡng tài nguyên CPU, memory.
Với việc sử dụng HPA để mở rộng ứng dụng theo tài nguyên sử dụng mặc dù cũng đem đến nhiều hiệu quả. Tuy nhiên thì cũng có một số hạn chế nhất định.
Extending HPA
Trong một số trường hợp, ứng dụng cần mở rộng theo điều kiện khác của hệ thống như số lượng công việc (job) hay số lượng request, traffic thực tế, bởi vì:
-
Phản ứng nhanh với yêu cầu của người dùng: Mở rộng theo lượng traffic thực tế sẽ cho phép hệ thống mở rộng ngay khi có nhu cầu từ người dùng, thay vì phải chờ đợi tải CPU hoặc bộ nhớ tăng lên. Điều này giúp hệ thống phản ứng nhanh hơn với các đợt tăng tải đột ngột.
-
Định lượng tài nguyên cụ thể: Việc scale theo CPU và memory có thể không phản ánh chính xác tốc độ phản hồi yêu cầu đến người dùng thực tế của ứng dụng. Trong khi đó, scale theo lượng traffic thực tế cho phép bạn điều chỉnh kích thước của hệ thống dựa trên yêu cầu cụ thể mà người dùng đang tạo ra, cũng như tốc độ phản hồi mà hệ thống muốn mang lại cho người dùng. Ví dụ: Viblo luôn muốn P95 Response Time không vượt quá 500ms, sẽ tự động scale ứng dụng ở ngưỡng PEAK RPS 120 requests/s chẳng hạn (có thể thông qua kết quả của bước kiểm thử hiệu năng ở trên).
-
Tối ưu hóa sử dụng tài nguyên: Mở rộng theo lượng traffic thực tế giúp tối ưu hóa sử dụng tài nguyên bằng cách chỉ mở rộng khi có nhu cầu thực sự từ người dùng, tránh việc lãng phí tài nguyên khi tải trọng thấp. Ví dụ: Ứng dụng worker xử lý queue-job sẽ tự động tắt khi không có queue-job nào cần thực hiện.
-
Khả năng dự đoán đợt tăng tải: Trong một số trường hợp, như trong các ứng dụng web hoặc dịch vụ trực tuyến, các đợt tăng tải có thể dễ dàng dự đoán được, chẳng hạn như trong các sự kiện tiếp thị hoặc các sự kiện quảng cáo đặc biệt. Scale theo lượng traffic thực tế cho phép bạn dễ dàng chuẩn bị và phản ứng với các đợt tăng tải như vậy một cách linh hoạt và hiệu quả. Ví dụ: Viblo dự đoán được lượng truy cập tại các thời điểm và thay đổi ngưỡng mở rộng dựa trên số lượng requests/s thực tế, đảm bảo trải nghiệm người dùng.
HPA có thể mở rộng theo một số metrics (Prometheus, API, ...). Kubernetes event-driven autoscaler (KEDA) hoạt động với vai trò như một Metric Server biên dịch các metric nhận được từ external server về cấu trúc mà HPA có thể hiểu được để tiến hành mở rộng thông qua HPA. Tìm hiểu thêm: https://keda.sh/.
Để triển khai KEDA cho ứng dụng của Viblo. Đầu tiên chúng tôi cài đặt K8s helm chart keda core: https://kedacore.github.io/charts
helm repo add keda https://kedacore.github.io/charts
Chúng tôi cũng sử dụng helm chart keda redis (opensource): https://github.com/sun-asterisk-research/keda-redis-scaler/tree/master/charts/keda-redis-scaler
KEDA
Luồng hoạt động cơ bản của KEDA.
1, KEDA scale ứng dụng về 0, tức là các ứng dụng sẽ không được chạy khi không có nhu cầu sử dụng. Tuy nhiên, các ứng dụng web, api bắt buộc sẽ chỉ được phép scale về 1 replica (zero downtime), bởi khi có người dùng đầu tiên truy cập ứng dụng chắc chắn phải được chạy sẵn vì khởi động ứng dụng sẽ mất một khoảng thời gian, dù nhanh hay lâu thì cũng sẽ ảnh hưởng đến trải nghiệm người dùng.
2, Thiết lập các metrics và nhận các events này từ ứng dụng.
3, KEDA kiểm tra events liên tục theo cấu hình, 30s, hay 1 phút tùy vào yêu cầu của Viblo.
4, Các events vượt ngưỡng sẽ được KEDA sẽ kích hoạt hành động mở rộng hoặc thu hẹp, HPA thực hiện thêm hoặc xóa ứng dụng.
Event Sources
KEDA hỗ trợ một số event sources.
Scaled Object
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata: name: viblo-web
spec: scaleTargetRef: name: viblo-web minReplicas: 1 maxReplicas: 20 triggers: # Scale up when average requests per second exceeds 60 - type: prometheus metadata: serverAddress: http://prometheus-operated.monitoring.svc.cluster.local:9090 metricName: http_rps threshold: "60" query: round(sum(irate(nginx_ingress_controller_requests{ingress="viblo-web"}[2m])) by (ingress), 0.001)
Thiết lập cấu hình scaledobject cho ứng dụng, định nghĩa các triggers kèm theo ngưỡng mở rộng. Để mở rộng ứng dụng web theo truy cập thực tế, chúng tôi sử dụng event sources là Prometheus. Ở ví dụ trên, ban đầu ứng dụng web sẽ có 1 replica tương ứng với 1 pod. ở kết quả đo được khi kiểm thử hiệu năng ở trên, cùng với phân tích, dự đoán các trang sẽ có nhiều lượng truy cập tùy theo thời điểm, Viblo lựa chọn là tối đa 120 reqs/s sẽ cần 2 pod (1 Virtual CPU, 1 Gi Memory). Như vậy ta có thể dễ dàng tính được, cứ vượt ngưỡng 60 reqs/s thì ứng dụng sẽ được mở rộng thêm 1 pod và số pod lúc đó sẽ là 2.
Web Scaling
Ứng dụng web scale-out theo truy cập thực tế.
Scaling Background Worker
Ứng dụng worker scale out theo lượng công việc (job) sử dụng thực tế.
Node AutoScaler
Các node (server) scale out theo lượng pod được sử dụng.
Các node tự động mở rộng dựa vào các pod sử dụng, tùy thuộc vào cấu hình resources (requests, limits) của pod và resources của node. Dựa vào kiểm thử Spike Testing cũng xác định được mức độ chịu tải của hệ thống từ đó Viblo team cũng lựa chọn được con số Node (server) lớn nhất có thể cung cấp.
Giám sát và điều chỉnh liên tục
Thực hiện việc giám sát hệ thống một cách liên tục để phát hiện và giải quyết các vấn đề hiệu suất kịp thời. Sử dụng các công cụ giám sát như Prometheus, Grafana để theo dõi hiệu suất và sức khỏe của hệ thống.
Công cụ giám sát, đo lường
Grafana: là một giao diện/dashboard theo dõi hệ thống (opensource), hỗ trợ rất nhiều loại dashboard và các loại graph khác nhau để người quản trị dễ dàng theo dõi.
Viblo Team dễ dàng theo dõi tình trạng sử dụng của CPU, Memory trên các Server (Node) của hệ thống.
Dashboard của Viblo trên Grafana.
Hỗ trợ cài đặt trên nhiều hệ điều hành:
Một số hệ điều hành hỗ trợ cài Grafana.
Prometheus Là một hệ thống mã nguồn mở, sử dụng để giám sát dựa trên các số liệu. Nó thu thập dữ liệu từ các service và host. Dữ liệu sau đó được lưu trong cơ sở dữ liệu chuỗi thời gian (time-series database).
Luồng hoạt động của Prometheus.
Một số các metris:
- kube_node_status_allocatable
- kube_pod_status_ready
- kube_pod_container_status_restarts_total
- Nginx_ingress_controller_requests
Ví dụ về PromQL: sum(rate(nginx_ingress_controller_requests[1m])) by (ingress)
Kiểm tra các metrics prometheus tại Grafana.
Kiểm tra các metrics prometheus frontend.
Api clients: Go, Java or Scala, Python, Ruby, Rust https://prometheus.io/docs/instrumenting/clientlibs/
Slack alert: Các vấn đề của hệ thống đều alert tự động để đội ngũ quản trị viên có thể nắm được tình hình hệ thống và có các hành động ngay lập tức.
Cảnh báo truy cập thực tế vượt ngưỡng stress testing.
Thử nghiệm và tối ưu hóa
Thực hiện các bài thử nghiệm mở rộng để đảm bảo rằng chiến lược scale-out hoạt động hiệu quả và đáp ứng được nhu cầu của hệ thống. Dựa vào kết quả của các thử nghiệm này, Viblo Team điều chỉnh và tối ưu hóa chiến lược mở rộng khi cần thiết.
© Tác giả: Serverside Engineer: Quy Nguyen & Phuong Truong