Lời mở đầu
Bài viết đầu tiên của mình trên này, chủ yếu là dịch lại và thêm thắt chút từ hiểu biết, mong mọi người ủng hộ nhe 🥲😁
I. Dagster là gì?

Dagster là một công cụ mã nguồn mở hỗ trợ Orchestrate Task (quản lý, tổ chức, điều phối và kiểm soát các tác vụ và công việc) . Nếu các bạn là Data Engineer hẳn sẽ phải biết Apache Airflow, về cơ bản mục đích sủ dụng của Dagster cũng giống như Airflow vậy (tuy nhiên chúng có nhiều điểm khác nhau, có thể mình sẽ viết một bài So sánh Airflow và Dagster).

II. Ứng dụng và đặc điểm của Dagster
1. Ứng dụng
Dagster là một công cụ mã nguồn mở, tập trung hỗ trợ Task Orchestrator. Dagster được thiết kế để phát triển và duy trì các data assets (ví dụ như Dataframe tables, các data sets, ML models, ...) Các data assets được sử dụng thông qua các function. Bạn khai báo các function và các data assets mà các fucntion đó tạo ra hoặc cập nhật. Sau đó ban sử dụng Dagster để chạy các fucntion đúng thời điểm và đảm bảo các assets luôn được cập nhật.
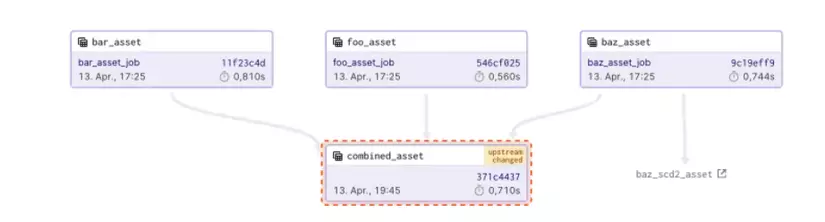
Dagster được sử dụng trong hầu như mọi giai đoạn của của vòng đời data development như local development, unit tests, integration tests, staging environments cho đến giai đoạn đưa lên production.
2. Đặc điểm
Dagster sử dụng Python để hoạt động và có thể được cài đặt dễ dàng với Python pip (lưu ý Python version 3.8 trở lên). Để cài đặt Dagster cơ bản, chạy lênh sau trong terminal:
pip install dagster dagster-webserver
Trong bài này chúng ta sẽ build một project đơn giản. Chúng ta collect dữ liệu từ một trang tổng hợp tin tức (ở đây là Hacker News), làm sạch nó và build một report đơn giản. Ta sẽ dùng Dagster để cập nhật data và report định kì, cái mà Dagster gọi là assets.
Trước hết bạn cần hiểu về một khái niệm cốt lõi của Dagster, đó là Software-defined asset (SDA) . Một asset là một ... đối tượng trong bộ lưu trữ liên tục, cái mà có thể ghi lại một ... cái gì đó 😀😄 (lú vcl ~~ ). Cơ bản thì asset có thể là:
- Một table hoặc view trong database
- Một file (như file trên máy của bạn 😀)
- Một model Machine Learning
Nếu bạn đã có một datap pipeline, bạn đã có những assets. Software-defined assets là một khái niệm cho bạn ghi data pipeline dựa trên các asset.
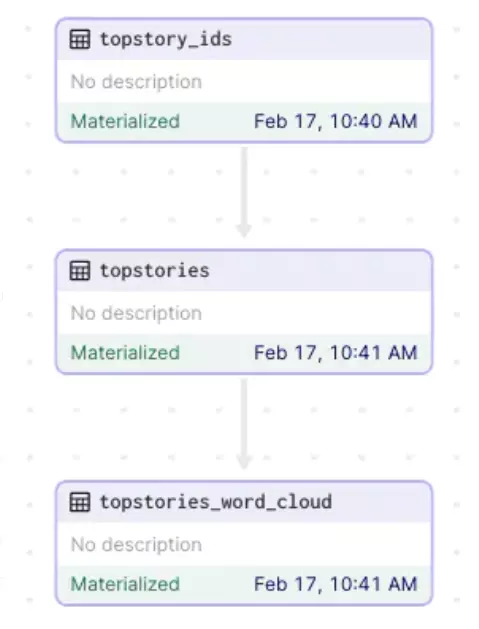
Dưới đây là một ví dụ. Một asset là một dataset tên là topstories, nó phụ thuộc vào một asset khác tên là topstory_ids. topstories lấy ID được tính toán trong topstory_ids, sau đó fetch data cho từng ID đó.
@asset(deps=[topstory_ids])
def topstories() -> None: with open("data/topstory_ids.json", "r") as f: topstory_ids = json.load(f) results = [] for item_id in topstory_ids: item = requests.get( f"https://hacker-news.firebaseio.com/v0/item/{item_id}.json" ).json() results.append(item) if len(results) % 20 == 0: print(f"Got {len(results)} items so far.") df = pd.DataFrame(results) df.to_csv("data/topstories.csv")
Một tập hợp các asset sẽ có dạng một đồ thị DAG (directed acyclic graph) (ai sử dụng Airflow sẽ phải biết cái này). Mỗi cạnh trong DAG tương ứng với sự phụ thuộc data giữa các asset. DAG giúp bạn:
- Hiểu về sự liên quan giữa các asset.
- Giúp làm việc với data pipeline dễ dàng, hiệu quả hơn.
Dagster có hỗ trợ giao diện người dùng (UI) dưới dạng web. Dưới dây là một DAG được biểu diễn trong User Interface:
Lời kết
Trên đây là một số điều có bản các bạn cần biết về Dagster, chưa dài lắm cơ mà ngại viết 🤣, còn rất nhiều thứ về Dagster nhưng mình sẽ viết ở những bài sau (hoặc là không  ))). Bài tiếp theo có thể là một Sample project như đã nói ở trên nhé. Cảm ơn mọi người đã đọc!
))). Bài tiếp theo có thể là một Sample project như đã nói ở trên nhé. Cảm ơn mọi người đã đọc!