Object detection: bài toán phát hiện + nhận diện vật thể. Bước một là đi tìm vị trí của vật thể trong toàn ảnh rồi bao quanh vật thể ấy bằng một khung hình chữ nhật được gọi là bounding box. Bước 2 là phân loại nhãn, gán nhãn cho vật thể ở trong bounding box.
Có nhiều thuật toán phát hiện vật thể như HOG, RNN, fast RNN, faster RNN, hay SSD. Ta sẽ tìm hiểu về YOLOv1, thuật toán one-stage. Gọi YOLO là thuật toán one stage (một khâu) vì quá trình xác định vị trí của vật thể và phân loại vật thể được dự đoán trong cùng một lúc.
1. Top-view of YOLOv1
YOLO có nghĩa là thuật toán chỉ cần nhìn 1 lần là có thể phát hiện ra vật thể.
YOLOv1 được coi như một mô hình hồi quy- regression problem.
Có hai bài toán tiêu biểu mà mình đã được học trong Machine Learning đó là Regression(Hồi quy) và Classification(Phân loại). Với các mô hình nhận diện vật thể, trả về outcome là xác suất của những class mà chúng ta đã dùng các loại Neural Networks để training- đây là bài toán Phân loại. Còn các bài toán trả về những giá trị liên tục như dự đoán giá nhà thì thuộc về bài toán Hồi quy. Vậy tại sao, YOLOv1 cũng là một model Neural Networks mà lại là một bài toán Hồi quy?
=> Bởi output của YOLOv1 là những con số liên tục được dự đoán và không ngừng cập nhật trong quá trình training,bao gồm:
 Hình minh họa bouding box
Hình minh họa bouding box
-
x, y, w, h: Tọa độ tâm của bounding box cùng chiều rộng( width) và chiều dài( height) của bouding box.
-
Object confident score : Độ tự tin bouding box có mang vật thể hay không.
-
Probability classes: Xác suất dự đoán nhãn vật thể trong bouding box dựa trên từng class Linear activation function (Hàm kích hoạt tuyến tính) được sử dụng ở lớp fully connected cuối cùng( lớp dự đoán trực tiếp các giá trị của bounding box) trong khi các layers khác thì sử dụng leaky relu activation:
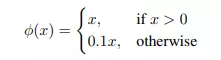
2. Quá trình training YOLOv1
2.1 Pre-trained
- YOLOv1 được đưa qua một mô hình pre-trained sử dụng AlexNet dựa trên bộ dữ liệu ImageNet với độ phân giải của ảnh là 224* 224. Sau khi đi qua Classification model để trích xuất các đặc trưng cần thiết thì ảnh được rescale lại về 448* 448 để thực hiện training qua Detecting model. Tổng quá trình 2 khâu training của YOLOv1 mất 135 epochs.
2.2 Kiến trúc
-
Kiến trúc của YOLOv1 là convolutional neural network được lấy cảm hứng từ GoogleNet.
-
Vậy lý do tại sao lại là GoogleNet mà không phải những loại DNN khác?
Câu trả lời ở đây là vì, GoogleNet có những Inception Block, những khối mà không chỉ có một conv2d làm việc với một input mà nhiều conv2d khác nhau cùng lúc làm việc với một input. Một vấn đề nảy sinh ra với GoogleNet là: khi có nhiều khối có nhiều Convolutional layers khác nhau, nhiều filter size khác nhau như 3* 3, 5* 5 được áp dụng khiến số lượng tham số trở nên vô cùng lớn khiến việc training bị chậm đi. Từ đó, Inception block đã có thêm những 1* 1 convolutional layers để giảm số lượng channel cũng như là khiến thời gian training nhanh hơn.
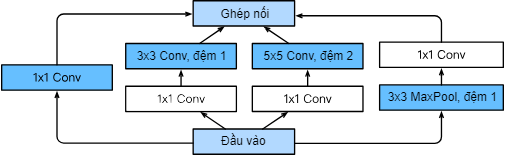
Cụ thể như sau, nếu chúng ta có các lớp Pooling để giảm độ phân giải của feature map thì 1x1 convolved layer có thể tăng hoặc giảm số channel của input. Lấy ví dụ về việc 1x1 làm model nhanh hơn:
input (256 depth) -> 1x1 convolution (64 depth) -> 4x4 convolution (256 depth) input (256 depth) -> 4x4 convolution (256 depth)
Cả hai kiểu mô hình trên đều cho ouput là một feature map như nhau, cùng có số lượng channel là 256 nhưng lại khác nhau ở tốc độ xử lý. Số lượng tham số của mô hình đầu tiên là 256* 64* 1* 1 + 64* 256* 4* 4 = 278528, trong khi đó số lượng tham số của mô hình thứ 2 là 256* 256 * 4* 4 = 1048676. Mô hình không có 1x1 layer chậm hơn khoảng 3.7 lần.
YOLOv1 gồm 24 lớp tích chập và 2 lớp fully connected layers
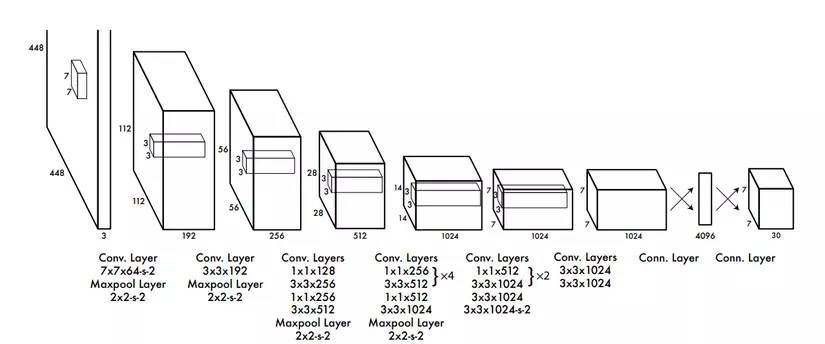 Qua 24 lớp tích chập và 2 lớp FCL với input image 448* 448, ta có được output là một vector với 4096 tham số được resize về 7* 7* 30.
Qua 24 lớp tích chập và 2 lớp FCL với input image 448* 448, ta có được output là một vector với 4096 tham số được resize về 7* 7* 30.
7* 7* 30 : Phương thức dự đoán của YOLOv1
Ảnh đầu vào kích thước 448* 448 và các giá trị pixel value được chuẩn hóa về [0,1] hoặc [-1,1], được chia thành cách ô, thường với YOLOv1 là 7* 7, mỗi ô được gọi là một grid cell. => Size này thường được chọn vì với số lượng grid cell bằng 49 phù hợp với cả độ chính xác của mô hình và chi phí tính toán, ngoài ra, với yolov1, 1 grid cell dự đoán 2 bouding box -> 7* 7* 2 = 98 predicted bounding box - đã phù hợp để xác định được vị trí của các vật thể.
 7 * 7 grid cell trên ảnh 448 * 448
7 * 7 grid cell trên ảnh 448 * 448
- Ý tưởng chia ảnh thành các grid cell để học vị trí của vật thể, nếu tâm của vật thể nằm tại ô nào thì ô đó sẽ đảm nhiệm việc detect ra bounding box cho vật thể ấy.
2.3 Bounding box
Bounding box là các hình chữ nhật bao xung quanh vật thể mang những thông tin về tọa độ và chiều dài chiều rộng của bounding box. Một bouding box sẽ có 5 giá trị thành viên, cụ thể:
- Δx, Δy : Độ lệch giữa tọa độ tâm của bounding box dự đoán và tọa độ điểm bên trái trên cùng của grid cell mà nó thuộc về, giá trị của Δx,Δy vì vậy mà nằm trong khoảng [0,1].
- Δw, Δh : Chiều rộng, chiều dài của bbox được chuẩn hóa theo kích thước của toàn bộ bức ảnh, giá trị của Δw, Δh nhờ vậy cũng bị ràng buộc trong khoảng [0,1]
- c : Xác suất bên trong bouding box có vật thể là bao nhiêu.
❓️Lý do độ lệch Δx, Δy được tính theo grid cell còn Δw, Δh lại được chuẩn hóa độ lớn của cả ảnh:
Vật thể sẽ được xác định vị trí theo grid cell, nghĩa là mô hình chỉ quan tâm việc dự đoán giá trị độ lệch ấy mà không cần quan tâm đến chính xác vị trí tâm vật thể ở đâu ( tọa độ cụ thể). Vị trí tâm của vật thể luôn có ràng buộc đến grid cell mà nó thuộc về, nhưng điều này cũng là một yếu điểm lớn của YOLOv1 vì khi một grid cell xác định một tâm vật thể và chỉ dự đoán xác suất một lần duy nhất dù cho có bao nhiêu bounding box trong grid cell => một grid cell tối đa chỉ dự đoán được một vật thể, cả ảnh tối đa chỉ dự đoán được 7* 7 = 49 vật thể.
Còn về phần w, h được chuẩn hóa theo độ lớn của toàn ảnh vì khi đó giá trị của w, h nhỏ và việc dự đoán chiều rộng và chiều dài sẽ không bị ảnh hưởng bởi độ phân giải của ảnh. Ví dụ ảnh đầu vào có là bao nhiêu thì model cũng chỉ việc dự đoán độ lệch chiều dài, chiều rộng trong khoảng [0,1] rồi về sau scale lại l Ngoài ra giá trị w,h trong khoảng [0,1] còn khiến việc tính loss và cập nhật tham số dễ dàng, nhanh chóng hơn.
Ví dụ với cách chuẩn hóa các giá trị tọa độ của bouding box:
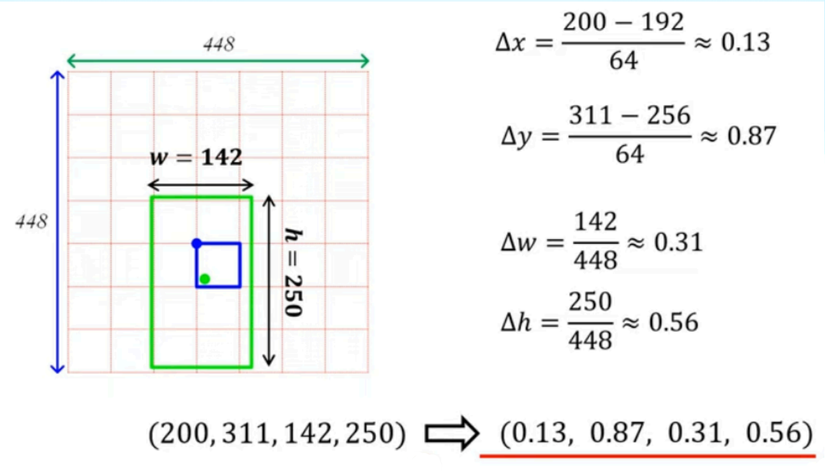
Ta có công thức chuẩn hóa x, y center về [0,1] như sau:
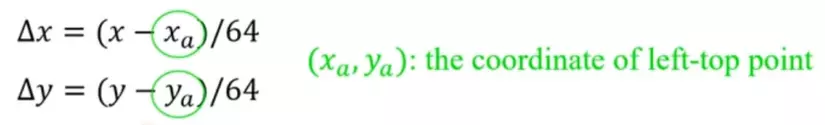 Tọa độ tâm của bounding box (x) trừ đi tọa độ của điểm góc trên cùng bên trái của grid cell, sau đó chia cho chiều rộng của một grid cell( trong ví dụ này là 64) với kích thước toàn ảnh là 448 * 448.
Tọa độ tâm của bounding box (x) trừ đi tọa độ của điểm góc trên cùng bên trái của grid cell, sau đó chia cho chiều rộng của một grid cell( trong ví dụ này là 64) với kích thước toàn ảnh là 448 * 448.
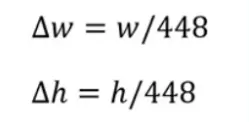
Chuẩn hóa chiều dài chiều rộng của bbox bằng cách chia cho chiều dài, chiều rộng tương ứng của toàn ảnh, với YOLOv1 là 448* 448.
Như vậy sau khi chuẩn hóa bằng công thức trên, với tọa độ tâm của vật thể là (200,311), Tọa độ góc trên cùng bên trái của grid cell chứa vật thể là (192,256), ta có 4 tọa độ của bounding box:

Sau khi có các giá trị tọa độ bounding box thì ta tiến hành label encoding ground truth box chuẩn bị cho quá trình training. Một grid cell sẽ được mã hóa thành một vector với các giá trị (Δx, Δy, Δw, Δh, c, p1, p1, ... ,pn), c là xác suất ground truth bounding box chứa vật thể: 1 nếu chứa vật thể, bằng 0 nếu không có vật thể nào, nếu không có vật thể thì c = 0 kéo theo toàn bộ giá trị còn lại bằng 0. One- hot encoding label (p1,...pn): N là số lượng các loại nhãn mà mô hình phân loại để nhận diện vật thể trong bounding box đó là gì, các p là các xác suất của từng class, ground truth sẽ là class thứ i mà pi =1. Cụ thể như sau: Giả sử ta có 49 grid cell, mỗi grid cell lại được mã hóa thành một vector có độ lớn 5 +N:

Nếu không có vật thể, mọi giá trị của vector bằng 0, nếu có vật thể (A11) với c =1 thì tọa độ ground truth là (0.9,0.7,0.1,0.1), p14 =1 chỉ ra rằng trong trong bbox là class person.
Predicted bounding box
Thường một grid cell trong YOLOv1 sẽ dự đoán ra 2 bouding box, mỗi box có 5 giá trị ( Δx1^, Δy1^, Δw1^, Δh1^, c1^), ( Δx2^, Δy2^, Δw2^, Δh2^, c2^). Như đã biết, các thông số trên là cái độ lệch chứ không phải tọa độ cụ thể. Khác với labeled ground truth bbox, cho dù có 2 hay nhiều bounding box dự đoán trong một grid cell thì các nhãn label cũng chỉ được dự đoán một lần => tối đa một grid cell chỉ dự đoán được một object. Như vậy, giả sử ta có 20 class trong bộ dữ liệu, cộng thêm 10 giá trị đến từ cả hai bounding box => Một grid cell mã hóa ra được một vector có độ lớn 20 + 10 = 30. Với cấu trúc 7* 7 grid cell, ta được output 7* 7* 30 như phân tích ở trên.
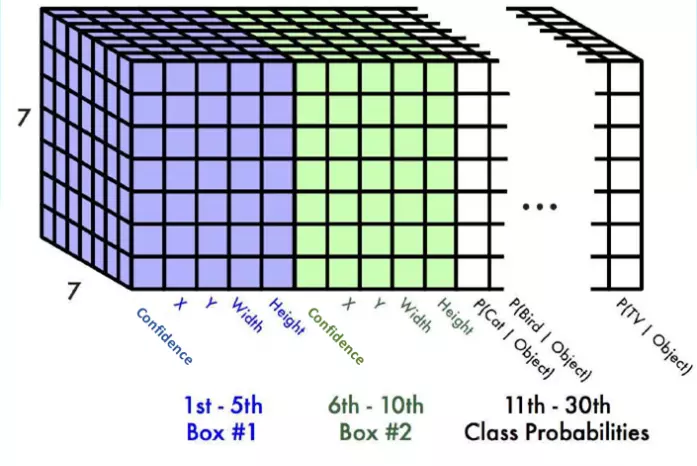
Output 7 * 7 * 30
2.4 Class confidence
c^ : Độ tự tin grid cell có chứa vật thể hay không, được tính bằng công thức
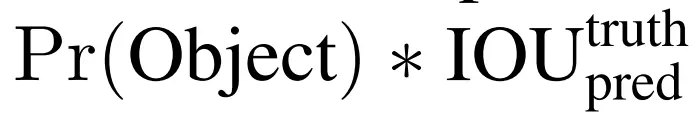
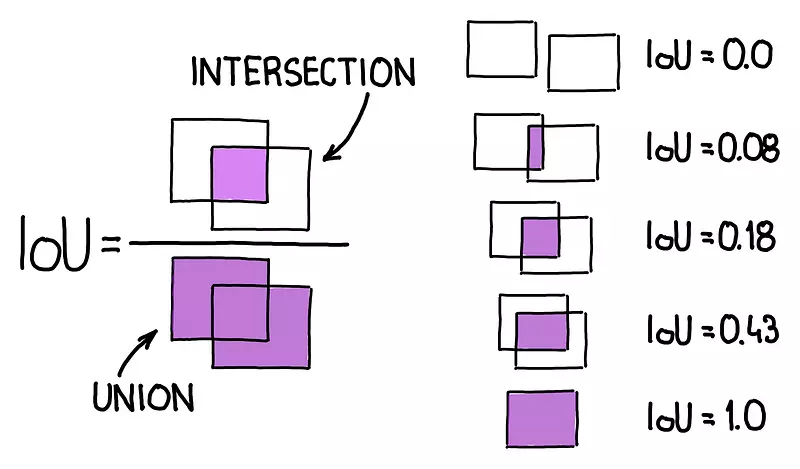
- Pr(Object) là xác suất có vật thể ( 0 hoặc 1) , IoU(intersection over union) là công thức tính xem mức độ trùng nhau của bounding box dự đoán và ground truth box. IoU đi tính tỷ lệ trùng khớp của 2 bounding box, do vậy giá trị của Iou chỉ nằm trong khoảng [0,1], bằng 0 khi 2 box không hề giao nhau, 1 khi 2 box hoàn toàn trùng khớp. Công thức tính IoU:
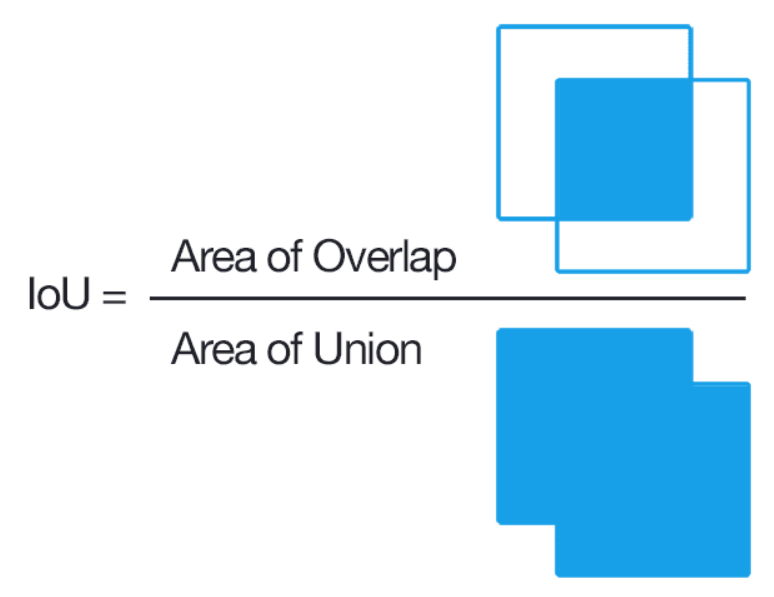
Phần tử là diện tích phần giao nhau của predicted bounding box và ground truth box, phần mẫu là tổng diện tích của 2 box trên hợp lại. Người ta sẽ quy định một Ngưỡng, thường thì IoU score >= 0.5 có nghĩa là predicted bouding box có độ tương đồng cao với ground truth box.
- Từ công thức tính trên ta thấy objectness confidence chính là IoU của box đó với bất kỳ ground truth box nào rồi từ đó chọn ra kết quả có IoU cao nhất để làm objectness confidence cho bbox. Do YOLOv1 thường sẽ dự doạn 2 box cho một ô, nghĩa là không quan tâm ô đó có vật thể hay không thì model vẫn sẽ dự đoán ra 2 bouding box, khi ấy một ngưỡng IoU được người dùng đặt ra ( thường là 0.5), nếu ngưỡng IoU của predicted bounding box nào nhỏ hơn 0.5 thì sẽ bị loại bỏ.
2.5 Confidence score
- Còn độ tự tin của từng class trong bouding box ( xác suất box đó chứa loại vật thể gì) được tính bằng công thức :
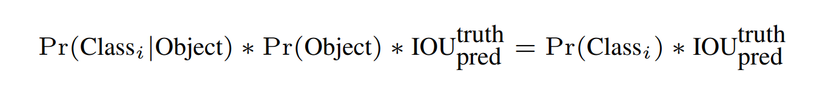
p(0,...,i,...n) được tính bằng xác suất có điều kiện giữa việc có vật thể thì nhãn của vật thể đó là gì, nhân với objectness confidence vừa tính ở trên. Khi có object, Pr(Object) = 1, Pr(Class(i)|Object) = Pr(Class(i)) nên ta có công thức tính xác suất của từng nhãn ở phía bên phải.
=> Confident score vừa thể hiện mức độ tương đồng của predicted bounding box và xác suất của nhãn được gán cho box là bao nhiêu.
2.6 The loss
- Sau khi dự đoán offset của các bounding box, hàm loss của YOLOv1 sẽ được tính bằng mean squared loss. Hàm Loss bên dưới là tổng hàm mất mát của Objectness Loss + Classification Loss + Box Regression Loss. Hàm loss này là tổng loss của tất cả các grid cell trong ảnh, riêng đối với với những ô không có vật thể, không có ground truth box để tham chiếu điếu, ta bỏ qua 2 phần loss còn lại mà chỉ tính loss của Objectness Score. Thêm vào đó, hàm loss có thêm các tham số để giảm độ quan trọng của phần loss của những ô không có object. Cụ thể như sau:
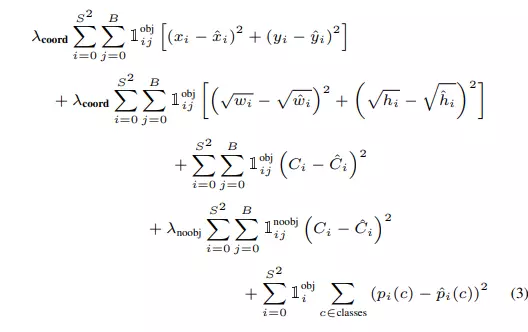
Hàm loss của YOLOv1
- Thành phần l(i,obj) đứng trước loss của các offsets có giá trị bằng 1 nếu grid cell đó có object, ngược lại không có vật thể sẽ có giá trị bằng 0 => Chỉ tính loss các offsets khi trong grid cell đó có vật thể.
- Thành phần l(i,no_obj) đứng trước loss của Objectness score có giá trị bằng 1 khi grid cell đó không có object nhằm tính loss objectness của những ô không có object.
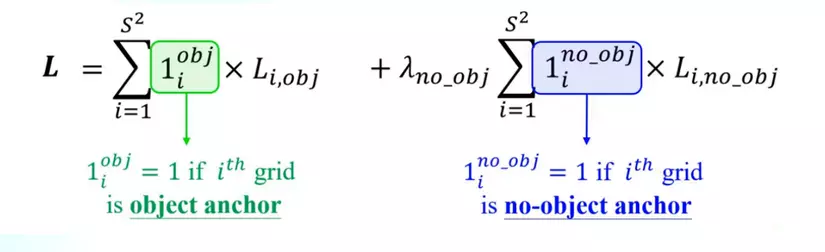
Tham số λcoord có giá trị = 5 được thêm vào trước hàm mất mát của các offset predicted bounding box và ground truth box.
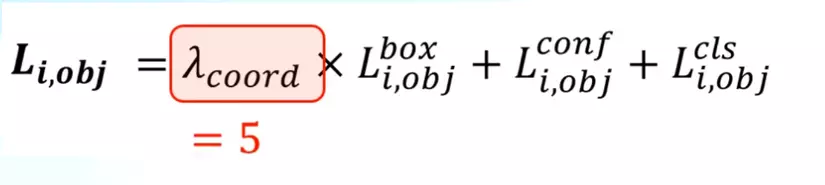
Ngược lại để giảm độ lớn phần loss của objectness score trong những grid cell không có vật thể, người ta nhân thêm λno_obj = 0.5,
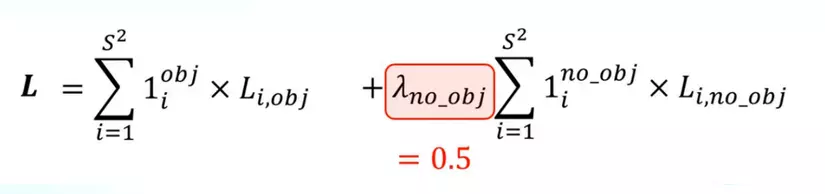
- Box Regression Loss
- Ngoài nhân với λobj = 5 thì Box regression Loss tính loss của các tọa độ thực( không phải offsets) như hình dưới:

-
Ta lấy hiểu bậc hai giữa các thành phần tọa độ của ground truth box và predicted box mà có tỷ lệ IoU cao nhất so với ground truth box trong grid cell đó. Điều đó cũng có nghĩa là, trên một grid cell, chỉ có một bounding box được chọn ra để tính box regression loss. Thông thường 1 ô có 2 hình bao dự đoán, nhưng chỉ có hình bao khớp với ground truth box nhất được đem ra để tính loss. ? Tại sao?
-
Ngoài ra, các tham số x, y , w, h là tọa độ thực của các bounding box và ground truth box vì khi đó, khác với việc dự đoán bounding box, ta biết rõ được vị trí vật thể ở đâu và kích thước của box so với toàn ảnh -> dễ dàng trong việc model học các vị trí trực tiếp.
-
Còn MSE của 2 giá trị w và h lại lấy hiệu các căn trước, điều này diễn ra là vì khi chúng ta sử dụng tọa độ thực sẽ xảy ra một vấn đề : ví dụ chiều rộng box dự đoán là 200, ground truth box là 205, nếu làm như thông thường, MSE cho cell này sẽ bằng 25. Nhưng với 1 box khác, chiều rộng box dự đoán là 20, ground truth box là 25, ta cũng có MSE cho cell này là 25. Vấn đề là, với các box nhỏ thì việc chênh lệch 5 là vô cùng lớp trong khi đó, với những bounding box lớn, việc chênh lệch 5 lại là không đáng kể. Điều này dẫn đến sự không cần bằng, không chính xác trong quá trình training => lấy căn hay thành phần này để cân bằng cả 2 trường hợp này. Tính 2 trường hợp trên theo công thức loss, ta được lần lượt 0.031 và 0.277 phản ánh đúng mức độ chênh lệnh và kích thước box.
- Objectness Score
- Loss của độ tự tin có object thì grid cell nào cũng được tính, bằng cách tính bình phương hiệu 2 score.
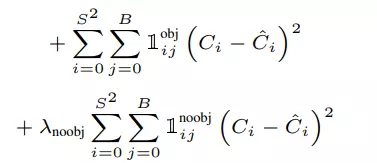
- Classification Loss
- Ta tính tổng bình phương các hiệu của xác suất từng class tương ứng:
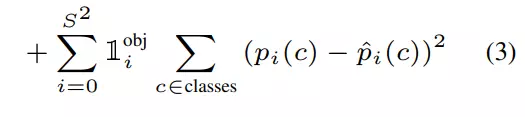
- Lấy ví dụ, ta có 20 class tất thảy thì sẽ được tính như sau :
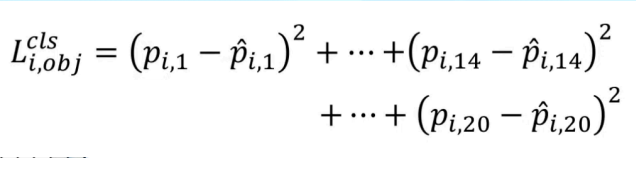
Giả dụ ta có các giá trị như sau và class ground truth là class thứ 14, với nhãn dán là person thì:
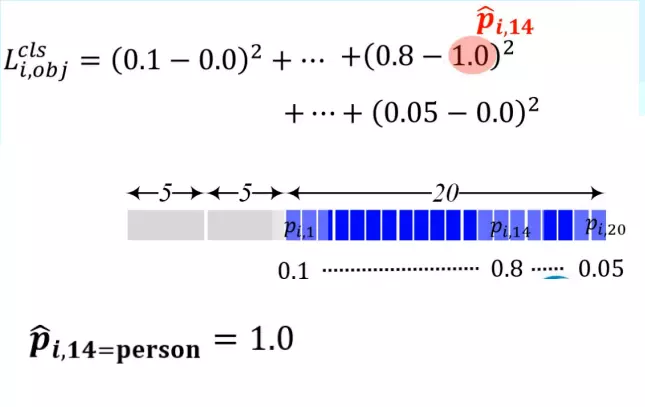
- Còn với grid cell không có object, đơn giản là mọi p xác suất từ ground truth box được one hot tất cả đều bằng 0! Lấy ví dụ :
Trong những epoch training đầu, YOLOv1 sử dụng learning rate từ 10^-3 đến 10^-2, tiếp tục 10^-2 cho 75 epochs, 10^-3 cho 30 epochs và 10^-4 cho 30 epochs cuối. Để tránh overfitting. YOLOv1 sử dụng dropout và data augmentation.
2.7 Non maximum suppression
Sau quá trình predicted bounding box của model, vẫn còn nhiều bounding box trùng lặp lên nhau với ngưỡng IoU với ground truth box cao. Vậy làm thế nào để ta có thể loại bỏ đi những box dự đoán cùng một vật thể, chỉ giữ lại 1 box với độ chính xác cao nhất cho một vật thể. Câu trả lời là sử dụng thuật toán Non maximum Suppression. Thuật toán như sau:
Bước 1: Ta có một list các bounding box còn lại gọi là P(box1, box2, box3,....) được sắp xếp theo thứ tự giảm dần về objeccness score. Những box đầu có độ tự tin cao sẽ được ưu tiên trước. Tiếp theo ta tạo một danh sách S gồm các box chuẩn đầu ra cuối cùng.
Bước 2: Lấy box đầu tiên từ tập P bỏ vào tập S, xóa box đó khỏi tập P sau đó tính tỷ lệ IoU với từng box còn lại trong tập P, nếu box nào trong tập 3 có tỷ lệ IoU so với box đang lấy làm chuẩn nhỏ hơn ngưỡng đặt ra (thường là 0,5) sẽ bị xóa khỏi tập P.
IoU lớn nghĩa là mức độ trùng lặp của 2 box lớn -> loại bỏ
Bước 3: Nếu tập P vẫn còn phần tử thì tiếp tục lặp lại bước 2 cho đến khi P không còn phần tử nào nữa. Kết quả ta được tập S gồm các box phân biệt nhau cho từng vật thể.
2.8 Output
- Output cuối cùng là các bounding box phân biệt lẫn nhau về đối tượng mà chúng detect, kèm theo confidence score và class của chúng mà model nhận diện được.
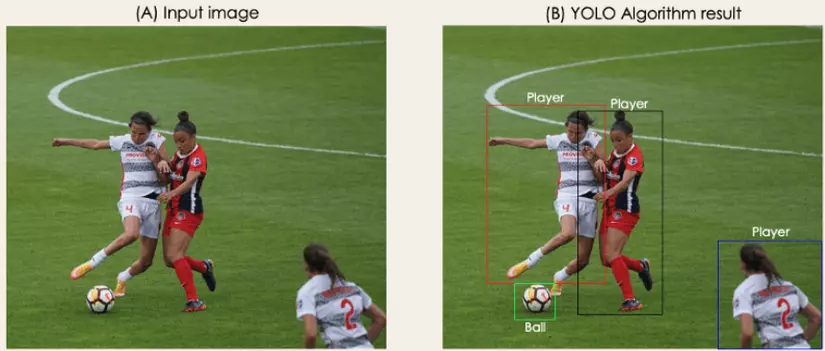
3. Hạn chế của YOLOv1
- Yolov1 tối đa chỉ có thể detect được 49 vật thể, mỗi grid cell chỉ có thể dự đoán hình bao cho một vật thể duy nhất.
- Khó khăn trong việc phát hiện những vật thể nhỏ vì lượng bounding box trên toàn ảnh ít, grid cell ít.
4. Thanks for reading
- Hãy bổ sung cho mình nếu còn thiếu hay sai sót ở đâu ạ!!!