Lời dẫn đầu
Xử lý dữ liệu time series đang là một chủ đề khá hot hiện nay, vì bản thân dữ liệu time series đang chiếm một vai trò và số lượng cực kì lớn trong các công ty, doanh nghiệp và nhu cầu xã hội. Do đó, kỹ thuật xử lý và phân tích lượng data này sẽ rất cần thiết và thực tế cho cuộc sống. Và phần đầu tiên, mình muốn chia sẻ cho các bạn là phần xử lý liên quan đến time reshampling. Mình xin phép chia sẻ một số tìm hiểu của mình về chủ đề này bằng một bài tập phân tích dữ liệu trên khóa học mà mình đã tham gia. Và ok, bài sharing của hôm nay bắt đầu thôi nào!!! 😄
Nội dung
Một số từ khóa
- Time series
- Time Resampling
- Exploratory Data Analysis
Source
- Dataset của bài sharing hôm nay sẽ là dữ liệu stock của hãng cà phê nổi tiếng Starbucks.
Link tải dataset mình để ở đây nhé! 👉️ Data source
Bộ dữ liệu này là dữ liệu cổ phiếu của Starbucks từ năm 2015 đến năm 2018, bao gồm giá bán hàng ngày và số lượng giao dịch.
Các bước tiến hành phân tích
Cài đặt thư viện và đọc dữ liệu
Cài đặt thư viện
Mình sẽ sử dụng một "người anh em" rất thân thuộc Pandas và một số lệnh thiết lập để hiển thị kết quả.
import pandas as pd from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
Đọc dữ liệu (Import data)
File dữ liệu là file có extension là .csv nên mình sử dụng lệnh read_csv để đọc file dữ liệu đồng thời chọn cột Date là cột index và chuyển đổi thành dạng datetime.
df = pd.read_csv('../Data/starbucks.csv', index_col='Date', parse_dates=True)
Hình ảnh sau khi thực hiện câu lệnh thành công:
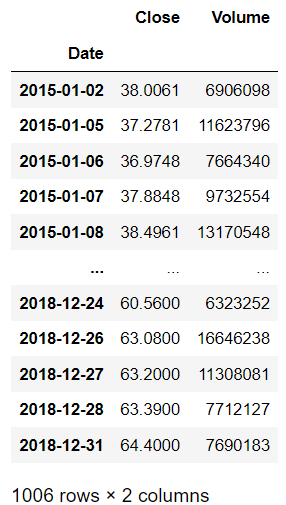
Anh em có thể thực hiện một số phân tích khác cho bộ data bằng những câu lệnh khác như head() tail() describe() info() plot(). Tất cả đều được hỗ trợ bởi thư viện Pandas.
Câu lệnh resample()
Câu lệnh thực hiện những phân tích xử lý thống kế trên bộ dữ liệu. Và nó dựa trên chỉ mục index của bộ data. Anh em có thể tham khảo kỹ hơn về câu lệnh này tại Pandas Pandas.resample().
Lệnh .resample() được gọi như hình dưới đây:
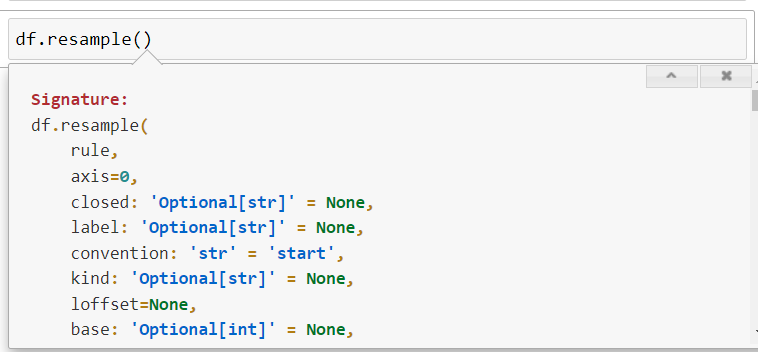
Khi gọi lệnh .resample(), anh em cần chú ý đến tham số rule, đây là tham số quan trọng và giá trị của nó được liệt kê ở bảng phía dưới. Lưu ý rằng, khoảng tần suất của giá trị tham số này sẽ được "gửi mẫu" đến aggregation function xử lý.
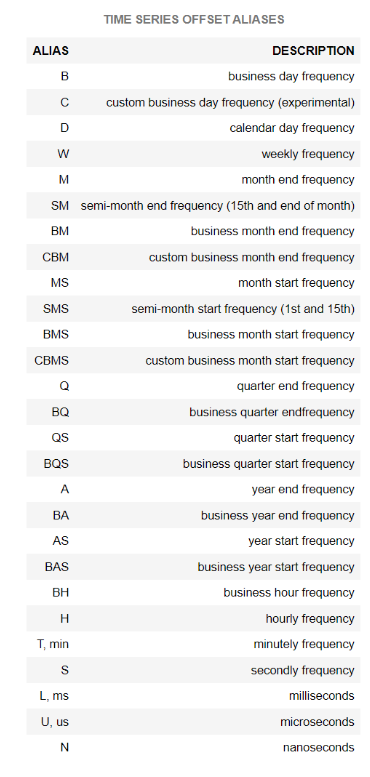
Tham số rule cho biết khoảng tần suất áp dụng các hàm tổng hợp (aggregation function). Các khoảng tần suất có thể là mỗi ngày (daily), mỗi tháng (monthly) hoặc mỗi năm (yearly)... Còn aggregation function là hàm được xây dựng sẵn dựa trên một số quy tắc toán học để xử lý dữ liệu theo các trường hợp đơn giản như mean, sum, count...
Một số ví dụ
- Tính giá trị trung bình của các cột trong dữ liệu theo tần suất năm (Yearly Mean)
df.resample(rule = 'A').mean()
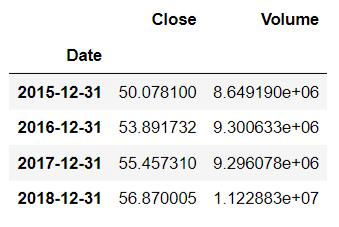
Quy tắc resampling với
rule=Alấy lại mẫu theo từng năm và áp dụng hàm aggregation (trong trường hợp trên thì aggregation là hàm tính trung bình mean). Và kết quả được ghi nhận vào ngày cuối mỗi năm.
Tuyệt vời quá nhỉ! Vậy muốn ghi nhận vào những ngày đầu năm thì làm thế nào?🤔
Áp dụng
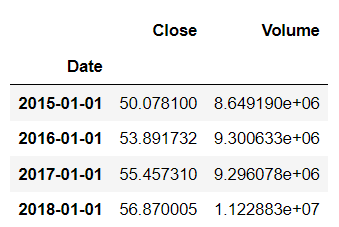
rule=AS
df.resample(rule = 'AS').mean()
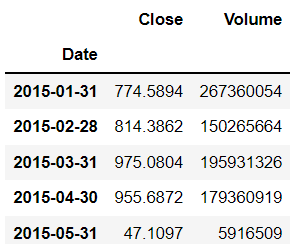
- Tính tổng giá trị của các cột trong bảng dữ liệu theo từng tháng trong 5 tháng đầu năm 2015 (Monthly Sum)
df_split_month = df['2015-01-02':'2015-05-02']
df_split_month.resample(rule='M').sum()
Custom hàm Resampling
Anh em hoàn toàn có thể tự custom hàm aggregation. Không có giới hạn nào, chỉ có giới hạn do tư duy mình tự đặt ra 😂 và anh em có thể tự xây dựng aggregation function made in yourself.
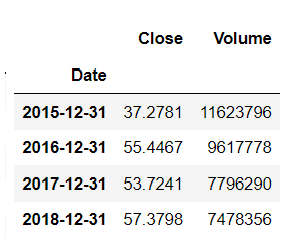
- Lấy giá trị Close và Volume trong ngày thứ hai trong một năm
def get_second_day(entries): """ Input: entry Output: giá trị Close và Volume ở ngày thứ hai """ if len(entries): return entries[1] Áp dụng phương thức apply() để áp dụng hàm aggregation cho các mẫu được lấy
df.resample(rule='A').apply(get_sencond_day)
Lời cảm ơn
Hy vọng một ít sharing trên về resampling có thể mang đến cho anh em một số điều thú vị và hay ho đến từ nhà Pandas đầy sức mạnh này. Anh em có thể phân tích thêm và áp dụng một số kỹ thuật mở rộng để hiểu rõ hơn về bộ data này nhé.