Mở đầu:
Crawl data sẽ giúp bạn thu thập dữ liệu từ các trang web khác. Hôm nay mình sẽ hướng dẫn các bạn crawl data từ 1 trang web sử dụng Laravel bằng cách đơn giản nhất
1. Cài đặt laravel
Các bạn có thể cài đặt laravel bằng câu lệnh sau:
composer create-project laravel/laravel crawl-data-app
Sau khi cài đặt xong các bạn vào thư mục của project vừa tạo chạy lệnh:
php artisan serve
Bây giờ project đã được start với port mặc định là 8000, nếu các máy các bạn đang sử dụng port 8000, các bạn có thể đổi sang port khác bằng cách thêm option --port vào cuối câu lệnh ví dụ bạn muốn dùng port 8080 bạn sẽ chạy lệnh sau:
php artisan serve --port=8080
Tiếp theo các bạn tạo 1 file Controller để xử lý logic. Để tạo file controller bạn sử dụng câu lệnh sau và nó có tên là CrawlDataController
php artisan make:controller CrawlDataController
Sau khi tạo xong file CrawlDataController.php sẽ nằm trong thư mục app/Http/Controllers
2. Bắt đầu crawl data
Các bạn vào trong file web.php nằm trong folder router import file CrawlDataController của chúng ta vừa tạo
use App\Http\Controllers\CrawlDataController;
Tiếp theo chúng ta tạo 1 route là crawl-data và sử dụng CrawlDataController để thực hiện logic
Route::get('crawl-data', [CrawlDataController::class, 'index']);
Với index là tên function chúng ta sẽ định nghĩa trong file app/Http/Controllers/CrawlDataController.php
Bây giờ chúng ta vào CrawlDataController.php tạo 1 function có tên là index
Mình sẽ lấy trang https://www.newsweek.com/world để thực hiện 1 demo
Trong function index vừa tạo các bạn thêm cho mình 1 đoạn code sau:
public function index() { //Truy cập đến trang web https://www.newsweek.com/world bằng phương thức get $response = \Http::get('https://www.newsweek.com/world'); //Sử dụng DOMDocument để lấy body của trang web ở đây là mình sẽ lấy tất cả HTML text của trang https://www.newsweek.com/world //Sau đó convert text về UTF-8 để tránh vì lỗi font chữ $dom = new \DOMDocument(); @$dom->loadHTML(mb_convert_encoding((string) $response->body(), 'HTML-ENTITIES', 'UTF-8')); //Xem dữ liệu nhận được dd(@$dom); }
Bạn có thể sử dụng dd() trong laravel để xem chúng ta đã lấy được gì mình sẽ sử dụng dd(@$dom) kiểm tra biến @$dom
Bây giờ các bạn truy cập vào đường link http://localhost:8000/crawl-data và thấy nội dung sau:
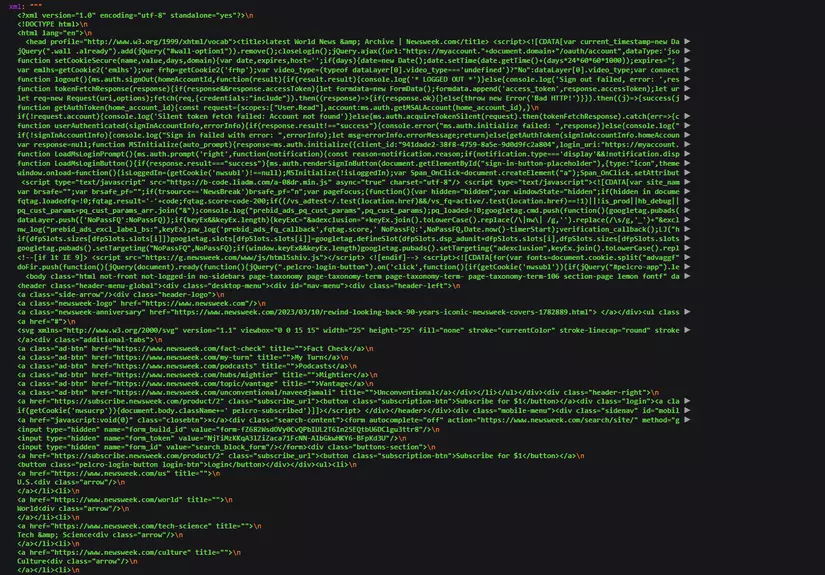
OK đến bước này chúng ta đã lấy thành công được HTML text
3. Lấy dữ liệu
Bây giờ chúng ta sẽ lấy 1 danh sách tin tức trên trang https://www.newsweek.com/world
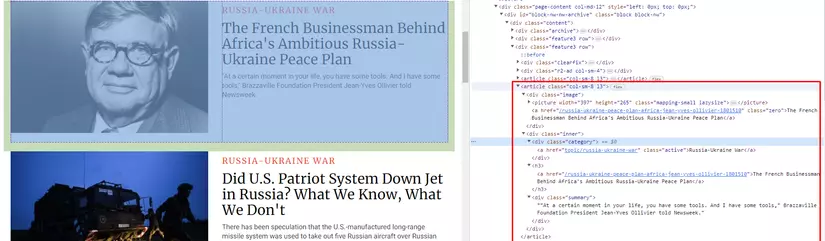
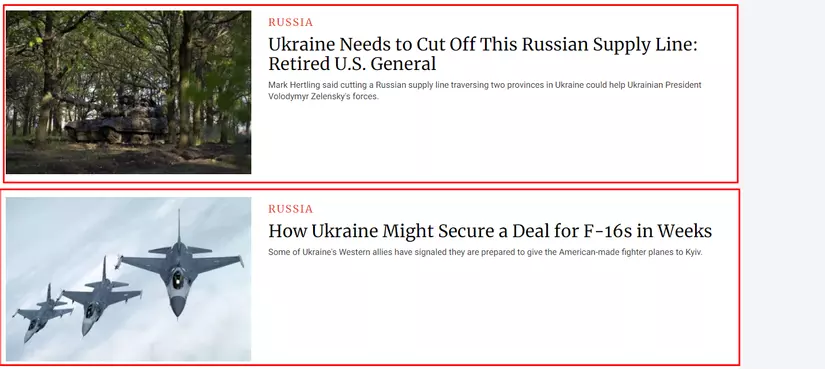
Trong ảnh trên phần khoanh đỏ là toàn bộ nội dung của 1 layout tin tức trên trang web https://www.newsweek.com/world. và tất cả các layout tin tức đều có chung 1 tag là article
Tiếp theo chúng ta sẽ tiến hành lấy text, hình ảnh, link của những tin tức có tag là article
Tiếp đến chúng ta sẽ tiến hành lấy ảnh, các bạn thêm đoạn code dưới đây vào trong function index:
public function index() { //Truy cập đến trang web https://www.newsweek.com/world bằng phương thức get $response = \Http::get('https://www.newsweek.com/world'); //Sử dụng DOMDocument để lấy body của trang web ở đây là mình sẽ lấy tất cả HTML text của trang https://www.newsweek.com/world //Sau đó convert text về UTF-8 để tránh vì lỗi font chữ $dom = new \DOMDocument(); @$dom->loadHTML(mb_convert_encoding((string) $response->body(), 'HTML-ENTITIES', 'UTF-8')); //Xem dữ liệu nhận được // dd(@$dom); //Dùng để query tag, class, id của 1 thẻ HTML $xpath = new \DOMXPath($dom); $images_query = $xpath->query('.//article //div[contains(@class, "image")] //picture //img'); $titles = $xpath->query('.//article //div[contains(@class, "inner")] //h3 //a'); foreach ($images_query as $key => $image) { $data[] = ['image' => $image->getAttribute("data-src"), 'link' => $titles[$key] ? $titles[$key]->getAttribute("href") : '', 'text' => $titles[$key] ? $titles[$key]->textContent : '', ]; } dd($data); }
Mình giải thích 1 chút trong đoạn code này
$xpath->query('.//article //div[contains(@class, "image")] //picture //img')
Mình đã sử dụng DOMXPath để query đến nơi thuộc tính ảnh để

Các bạn có thể thấy trong article tag là div có class='name' và bên trong có picture tag và img như vậy mình sẽ gọi lần lượt đến từng thẻ một như đoạn code trên là
.//article //div[contains(@class, "image")] //picture //img
Sau khi query xong nó sẽ trả cho mình 1 array với tất cả các thẻ img, mình sẽ dùng foreach để lấy ra từng phần tử img và lấy link của nó bằng cách gọi function getAttribute(),

Các bạn có thể thấy thẻ img có thuộc tính là data-src chưa link hình ảnh, để lấy được mình chỉ cần gọi $image->getAttribute("data-src") rồi push nó vào 1 mảng có tên là $data giống như trong đoạn code trên
Với title và link cũng tương tự như vậy img
Sau đó chúng ta sử dụng dd($data) chúng ta truy cập vào http://localhost:8000/crawl-data để kiểm tra thành quả thôi nào:
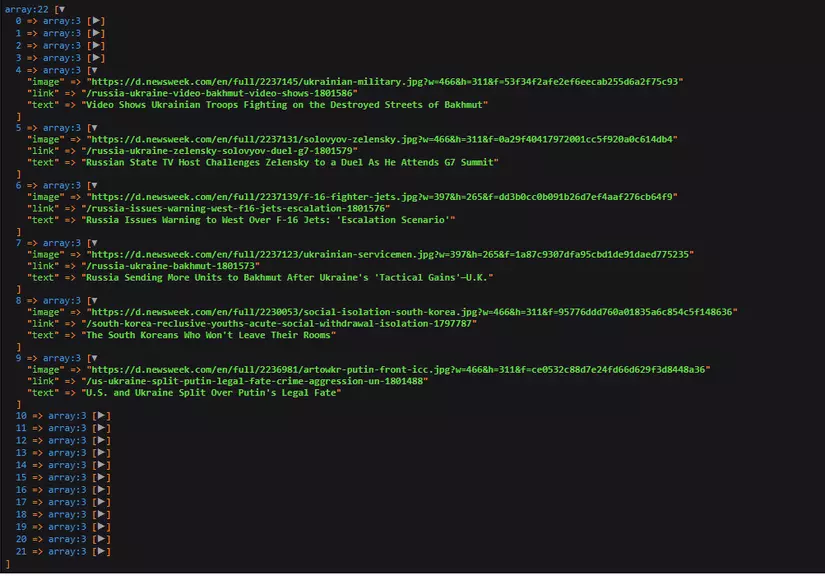
Mỗi mảng sẽ tương ứng với 1 bài mà mình khoanh đỏ trong hình dưới đây:
Wow cuối cùng cũng đã xong, bây giờ dữ liệu trang web khác đã là của bạn, bạn có thể lưu nó vào trong Database;
Kết luận:
Bài này mình cũng đã giới thiệu cách lấy data từ 1 trang web khác, nó cũng không quá kho khăn đúng không mọi người, nếu có thì cần bổ sung mọi xin mọi người cho ý kiến ở dưới bình luận, và mọi người nhớ follow để theo dõi mình những bài viết khác của mình nhé, mình cảm ơn mọi người