Chắc hẳn với mọi người khi làm về AI thì việc Mất cân bằng dữ liệu (Imbalance data) là điều thường gặp, và việc xử lý chúng là việc làm hết sức quan trọng trong việc train một model AI thuộc dạng bài toán Supervised Classifications. Dữ liệu bị mất cân bằng hiểu nôm na là sự phân bổ các mẫu trên các class - label chêch lệch quá lớn dẫn tới việc mô hình tập trung chỉ học những đặc trưng của class có nhiều data, không khái quát được toàn bộ mẫu. Dẫn đến việc model dự đoán tốt trên các class có nhiều data và dự đoán kém với class có ít data. Vì thế sau khi tìm hiểu thì mình viết bài này vừa là note lại cho bản thân vừa chia sẻ cho mọi người cách xử lý case như thế này. Trong bài có chỗ nào sai hay chưa đúng thì các bạn comment để mình cùng trao đổi, sửa chữa.
Data Example
Trong bài viết này mìn sẽ sử dụng data mẫu tại đây. Việc đầu tiên là dùng pandas để đọc thử xem file data có những gì.
import pandas as pd df = pd.read_csv('glass.csv')
df.head()
Kết quả file csv bao gồm 214 samples và 7 classes.
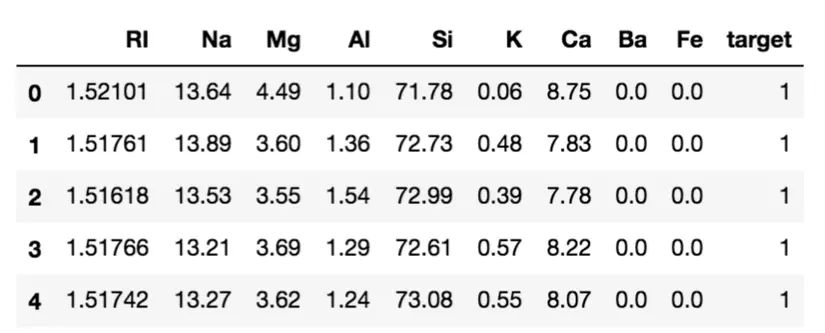
Quan sát thì ta thấy là các feature là gồm RI, Na, Mg, Al, Si, K, Ca, Ba, Fe và label - target từ 1 --> 7. Ta sẽ split thử.
features = []
for feature in df.columns: if feature != 'target': features.append(feature)
X = df[features]
y = df['target']
Mình sẽ dùng sklearn để chia train,test.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)
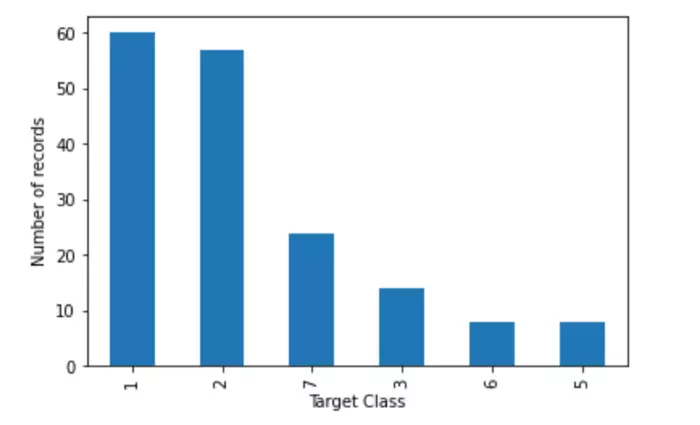
Sau khia chia xong ta sẽ dùng matplotlib để plot xem số lượng data được phân bổ như thế nào.
import matplotlib.pyplot as plt
count = y_train.value_counts()
count.plot.bar()
plt.ylabel('Number of records')
plt.xlabel('Target Class')
plt.show()
Và đây là kết quả. Ta thấy được lượng data thuộc class 1,2 đang gấp ~ 3 lần class 7 và gấp 6 lần class 6, 5.
Và bây giờ mình sẽ sử dụng Random Oversampling và Undersampling để tăng, giảm lượng data ở các class.
Random Oversampling and Undersampling
Trong đây đề cập đến hai từ là minority class và majority classes, nếu Vietsub thì thành Lớp thiểu số, Lớp đa số, nôm na là lượng data của class chiếm nhiều, ít trong tập mẫu. Chúng ta sẽ cố gắng cho tập dữ liệu của các class là tương đương nhau.
Về kỹ thuật Oversampling ở đây đơn giản là tăng số lượng mẫu ở Lớp thiểu số, giả sử class A có 100 mẫu, class B có 1000 mẫu ta sẽ tăng số lượng mẫu của class A bằng cách Random vị trí từ tập dữa liệu có trong mẫu và đưa vào training set, ví dụ như hình dưới.
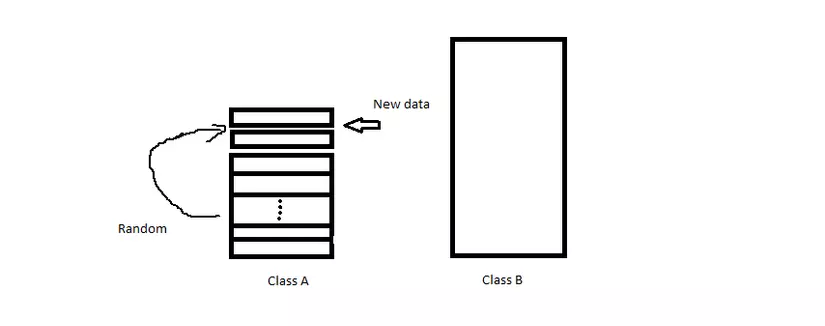
Đi cùng với oversampling thì là Undersampling. Ý tưởng tương tự như Over nhưng thay vì tăng thì sẽ là giảm data ở Lớp đa số cũng bằng cách Random như trên và delete dữ liệu đó đi.

SMOTE
Cụ thể ở đây sử dụng kỹ thuật SMOTE (Synthetic Minority Oversampling TEchnique), các bạn có thể đọc thêm tại link.
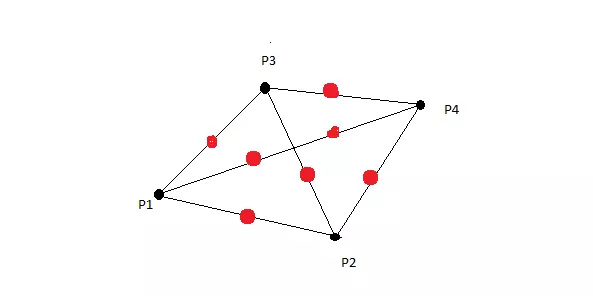
Như hình dưới đây là plot sự phân bổ của 2 class (tạm gọi là ô vuông, hình tròn) qua quan sát thì thấy rằng lượng mẫu hình tròn đang rất ít và việc ta làm là tăng lượng mẫu nó lên bằng phương pháp SMOTE.

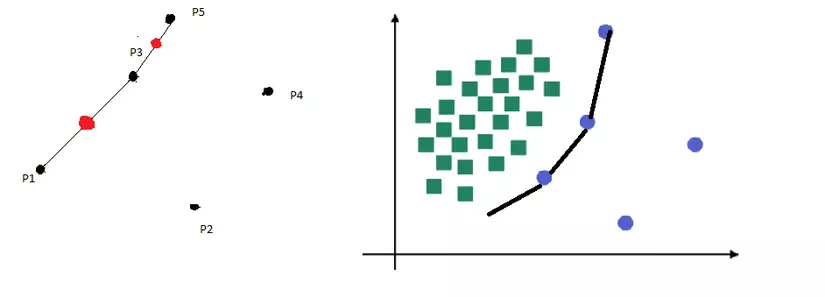
Ý tưởng chung của SMOTE là tạo ra dữ liệu tổng hợp giữa mỗi mẫu của lớp thiểu số và “k” hàng xóm gần nhất của nó. Có nghĩa là, đối với mỗi một trong các mẫu của lớp thiểu số, “k” các láng giềng gần nhất của nó được chọn (theo mặc định là k = 5). Sau đó giữa các cặp điểm được tạo bởi mẫu và từng láng giềng của nó thì ta sẽ có được data mới. Ví dụ như hình bên dưới, với P1 là dữ liệu mẫu với k=3 --> P2, 3, 4 ta sẽ ramdom giá trị giữa từng khoảng cách từ P2, 3, 4 đến P. Và cũng từ P2, 3, 4 làm tương tự như thế.
Nhược điểm của phương pháp SMOTE trên là với sự phân bổ mẫu không riêng biệt (có thể trộn lẫn vào nhau) nếu random như thế sẽ tạo ra rất nhiều mẫu bị trùng (or nhiễu) với lớp khác như thế thì ảnh hưởng đến kết quả model (hình minh họa).

Tuy nhiên sau này người ta phát triển lên là Borderline-SMOTE. Điểm cải tiến ở phương pháp này là thay vì lấy k toàn bộ của dữ liệu xung quang P2, 3, 4 thì lấy k ở tiếp 1 cạch (xem hình bên dưới), các cạnh này nằm ở đường phân chia giữa lớp (ô vuông và tròn), còn những điểm bị lẫn như ở ví dụ trên sẽ bỏ qua.
Lý thuyết thì tạm như thế đã. Và để làm được thì mình sẽ sử dụng thư viện Imbalanced-Learn hỗ trợ cho việc này.
pip install imbalanced-learn
Code minh họa như dưới đây :
import numpy as np
from imblearn.under_sampling import ClusterCentroids
from imblearn.over_sampling import SMOTE
from imblearn.over_sampling import BorderlineSMOTE n_samples = count.median().astype(np.int64) # Giảm mẫu def sampling_strategy(X,y,n_samples, t='majority'): target_classes = '' if t == 'majority': target_classes = y.value_counts() > n_samples elif t == 'minority': target_classes = y.value_counts() < n_samples tc = target_classes[target_classes == True].index #target_classes_all = y.value_counts().index sampling_strategy = {} for target in tc: sampling_strategy[target] = n_samples return sampling_strategy under_sampler = ClusterCentroids(sampling_strategy=sampling_strategy(X_train,y_train,n_samples,t='majority'))
X_under, y_under = under_sampler.fit_resample(X_train, y_train) # Tăng mẫu
# SMOTE - BorderlineSMOTE
def smote(x, y): k_neighbors = math.ceil(sum(y) * 0.01) smote = SMOTE(sampling_strategy=1, k_neighbors=k_neighbors) x, y = smote.fit_resample(x, y) return x, y def bordersmote(x, y): k_neighbors = math.ceil(sum(y) * 0.01) m_neighbors = math.ceil(sum(y) * 0.01) bordersmote = BorderlineSMOTE(sampling_strategy=1, k_neighbors=k_neighbors, m_neighbors=m_neighbors) x, y = bordersmote.fit_resample(x, y) return x, y
Và kết quả sau khi qua toàn bộ các bước trên :

Done !!!