Một trong những điểm thú vị khi ta code bằng cuda là chúng ta có thể tùy ý sử dụng bộ nhớ nào mà ta thích (tức là khi khởi tạo 1 giá trị, 1 biến bất kì ta có thể chỉ định nó được lưu vào bộ nhớ nào 1 cách tùy ý ) chứ không phải là để máy tính tự quyết định bộ nhớ nào sẽ được dùng và nhờ vào việc đó chúng ta có thể tận dụng triệt để các bộ nhớ để tối ưu chương trình.
Ở bài này mình sẽ giới thiệu các bộ nhớ thuộc GPU cũng như công dụng của từng cái một và xin lưu ý là bài này sẽ liên quan đến bài bonus 2 vì vậy nếu các bạn chưa đọc bài bonus 2 thì nên đọc trước khi đọc bài này.
Xin lưu ý là bài này mình đi thuần về lý thuyết còn về cách sử dụng mình sẽ để ở bài sau
Các bộ nhớ trong GPU
trước khi đi qua các bộ nhớ trong GPU thì chúng ta cần biết là khi nói về bộ nhớ, ta thường chia thành hai loại chính: bộ nhớ vật lí (physical memory) và bộ nhớ logic (logical memory).
Bộ nhớ vật lí (Physical Memory): Đây là bộ nhớ thực sự trên phần cứng của máy tính. Nó bao gồm các thanh RAM và các thiết bị lưu trữ như ổ cứng (HDD/SSD). Bộ nhớ vật lí là nơi dữ liệu và chương trình được lưu trữ trực tiếp và có thể truy cập nhanh chóng từ bộ xử lý.
Bộ nhớ logic (Logical Memory - hay còn có cái tên quen thuộc là virtual memory): Đây là không gian địa chỉ mà hệ điều hành và các chương trình có thể truy cập. Bộ nhớ logic không nhất thiết phải tương ứng với bộ nhớ vật lí một cách trực tiếp. Hệ điều hành thường quản lý việc ánh xạ (mapping) giữa địa chỉ logic và địa chỉ vật lí. Nó giúp quản lý việc cấp phát và quản lý bộ nhớ cho các chương trình chạy trên hệ thống.
Có thể hiểu 1 cách đơn giản là khi ta code thì chúng ta sẽ tương tác với logical memory, và khi code xong các dữ liệu đang nằm trên logical memory sẽ được mapping qua physical memory (tức là máy tính sẽ hoạt động ở physical memory) .
Góc nhìn Logical
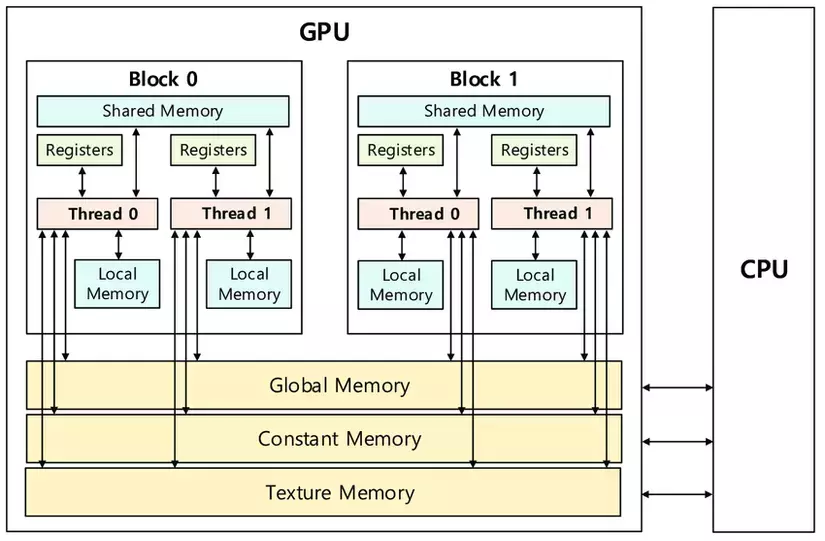
Như mình đã đề cập thì Block,Thread là logical và vì là cơ chế SIMT nên chúng ta cần phải biết các Thread,BLock được phân bố như thế nào trong các bộ nhớ của GPU ( logical memory )
Ở đây chúng ta sẽ có 1 khái niệm khá thân thuộc là scope ( phạm vi truy cập ): đóng một vai trò quan trọng trong việc hiểu cách các tài nguyên như Thread và Block được phân bố và quản lý trong bộ nhớ logic của GPU.
Local Memory: Mỗi Thread có thể sử dụng local memory riêng, nơi mà nó có thể lưu trữ các biến tạm thời. Đây là phạm vi truy cập có phạm vi nhỏ nhất và chỉ dành riêng cho mỗi Thread.
Shared Memory: Các Thread trong cùng một Block có thể chia sẻ dữ liệu thông qua shared memory. Điều này cho phép các Thread trong cùng một Block giao tiếp và truy cập dữ liệu nhanh hơn so với việc truy cập global memory.
Global Memory: Đây là bộ nhớ lớn nhất trong GPU và có thể truy cập bởi tất cả các Thread trên mọi Block. Tuy nhiên, truy cập vào global memory thường chậm hơn so với các loại bộ nhớ khác, do đó cần phải tối ưu để tránh hiệu năng bị giảm.
Texture Memory và Constant Memory: Đây là các loại bộ nhớ đặc biệt trên GPU, được tối ưu cho việc truy xuất các loại dữ liệu cụ thể như hình ảnh (texture)hoặc các giá trị hằng số. Các memory này có thể truy cập bởi tất cả các Thread trên mọi Block
Góc nhìn Physical
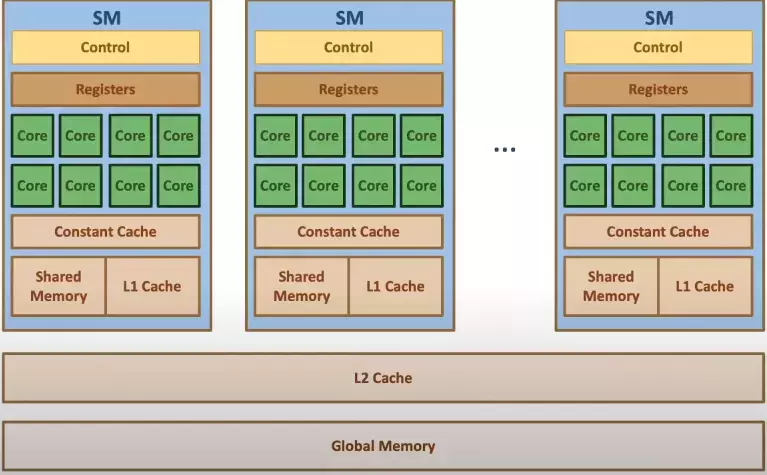 Nó cũng khá giống với Block và Thread nhưng ở đây là SM và SP.
Mỗi SM sẽ sở hữu riêng cho mình các shared/Cache/Constant/Register memory. Và các SM sẽ dùng chung 1 global memory.
Nó cũng khá giống với Block và Thread nhưng ở đây là SM và SP.
Mỗi SM sẽ sở hữu riêng cho mình các shared/Cache/Constant/Register memory. Và các SM sẽ dùng chung 1 global memory.
Tiếp đến chúng ta sẽ xem tốc độ truy cập dữ liệu của các bộ nhớ này
Bandwidth of memory
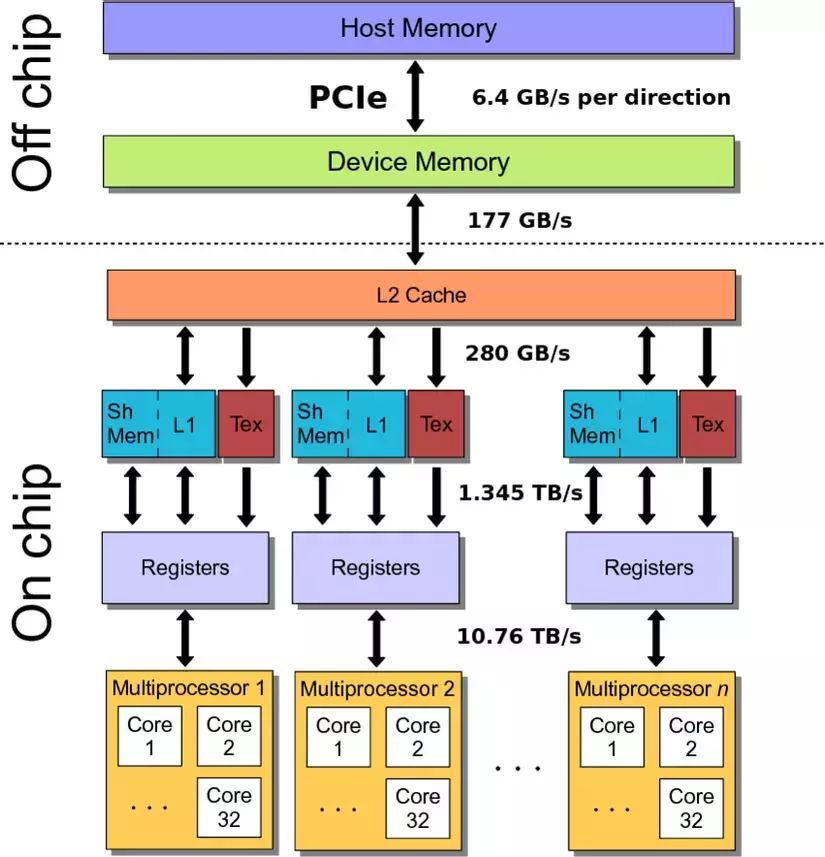
PCIe
Như mình đã đề cập thì CPU( host ) và GPU ( device ) là 2 thành phần riêng biệt nên vì vậy chúng sở hữu các memory riêng biệt và không thể truy cập trực tiếp mà phải copy data qua lại thông qua PCIe (hay còn gọi với cái tên quen thuộc là bus )
Một trong những yếu tố chính để quyết định là liệu chúng ta có nên đưa data từ CPU về GPU để tính toán hay không là do PCIe vì như trong hình ta có thể thấy PCIe sở hữu tốc độ transfer data chậm nhất.
Để giải quyết vấn đề khi copy 1 lượng lớn data từ CPU về GPU thì NVIDIA đã đưa ra 3 phương pháp:
- Sử dụng Unified memory
- Sử dụng Pinned memory
- Phương pháp streaming ( hay còn gọi là hidden latency )
Các phương pháp này mình sẽ nói ở các bài sau nhưng nếu các bạn tò mò thì có thể đọc thử trước các bài viết của NVIDIA: How to Optimize Data Transfers in CUDA C/C++
Global memory
Global memory ( hay còn gọi là device memory ) là memory sở hữu bộ nhớ lớn nhất nằm trong GPU và vì là lớn nhất nên cũng là bộ nhớ có tốc độ truy cập chậm nhất chỉ sau PCIe
Làm sao để khắc phục vấn đề này, ở bài sau về code mình sẽ hướng dẫn 1 kĩ thuật trong lập trình song song giúp cải thiện tốc độ khi truy cập ở mức global memory và yên tâm là nó sẽ dễ 1 cách bất ngờ
Global memory cũng giống như RAM ở CPU vậy, khi chúng ta khởi tạo 1 giá trị bất kì nào đó ở GPU mà không chỉ định nó sẽ được lưu trữ vào bộ nhớ nào thì sẽ mặc định lưu vào Global memory
Từ đây có thể thấy mục đích chính của global memory là dùng để lưu trữ dữ liệu lớn
Shared/Cache memory
Shared memory hoặc là Cache là các bộ nhớ có tốc độ truy xuất nhanh nhưng bù lại bộ nhớ không lớn bằng global memory.
Nhưng vì sở hữu tốc độ nhanh nên cũng khó kiểm soát các dữ liệu hơn ở global memory, và 1 trong các vấn đề làm ảnh hưởng nghiêm trọng đến tốc độ truy xuất là bank conflict. Vậy bank conflict là gì thì cũng sẽ là ở các bài sau nha
Vì shared/cache memory sở hữu tốc độ truy xuất nhanh nên ta sẽ dùng nó để lưu trữ các dữ liệu khi tính toán. Tức là đầu tiên ta sẽ copy toàn bộ dữ liệu từ CPU về GPU và lưu ở global memory, sau đó chúng ta sẽ copy từng phần ( theo các chunk ) đẩy lên shared memory để tính toán và khi tính toán xong sẽ đẩy về lại global memory.
Texture Memory và Constant Memory
Như đã đề cập phía trên, Texture Memory và Constant Memory là các loại bộ nhớ đặc biệt trên GPU, được tối ưu cho việc truy xuất các loại dữ liệu cụ thể như hình ảnh (texture) hoặc các giá trị hằng số. Và tốc độ truy xuất của 2 loại memory này cũng khá nhanh ( có thể bằng shared memory )
Vì vậy mục đích sử dụng Texture Memory và Constant Memory là để tối ưu hóa việc truy cập dữ liệu và giảm tải các dữ liệu cần tính toán khi sử dụng shared memory. Tức là thay vì chỉ đẩy dữ liệu lên hết shared memory thì chúng ta có thể chia bớt 1 phần qua cho Texture Memory và Constant Memory
Một chút thú vị
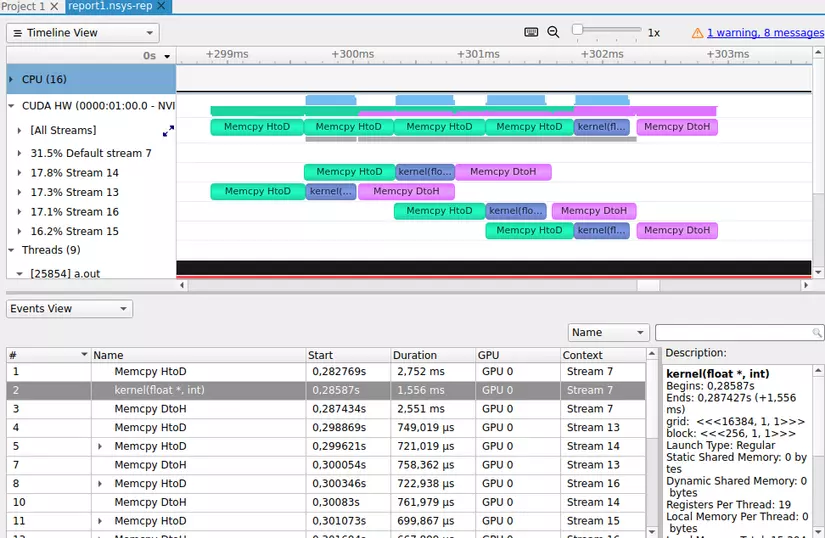
1 lưu ý nhỏ là các thông số về bandwidth trên hình chỉ là các con số minh họa, để xem cụ thể bandwidth của từng memory của từng máy như thế nào thì NVIDIA đã tạo ra 2 công cụ cực kì hữu ích và rất tiện lợi trong việc optimize cũng như debug là Nsight system và Nsight compute. Và mình sẽ nói về cách sử dụng của 2 công cụ này ở các bài sau, và các bạn yên tâm là nếu máy tính không có GPU thì cũng sẽ dùng được. Và đây là 1 số minh họa khi phân tích chương trình của chúng ta bằng 2 công cụ trên
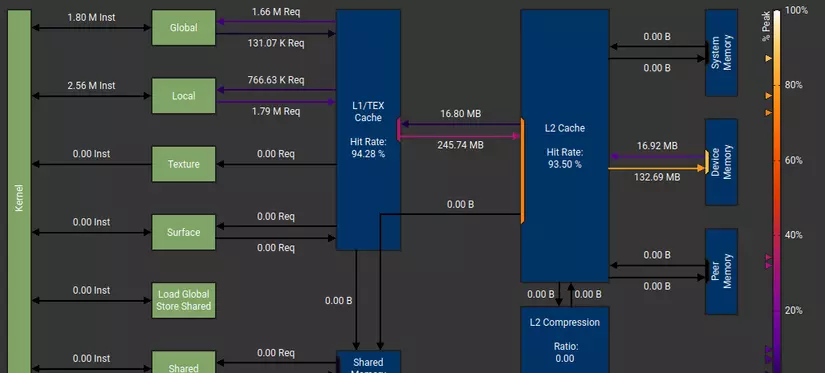
Bài tập
- Như trong hình thì tại sao shared memory và L1 cache lại được ghép chung thành 1 memory chứ không phải là 2 memory riêng biệt?
- Tại sao phạm vi truy cập của L1 là các Thread trong cùng 1 block nhưng của L2 lại là toàn bộ các Thread