Để trả lời cho câu hỏi của bài 6 thì chúng ta phải đi qua 2 khái niệm synchronize và asynchronize
Xin lưu ý là 2 khái niệm này rất quan trọng và chúng ta luôn luôn gặp trong quá trình code cuda-C vì vậy mọi người hãy đọc thật kĩ.
Synchronization - Asynchronization
trước khi giải thích 2 khái niệm này thì mình sẽ đi qua 1 ví dụ giúp các bạn dễ hình dung hơn.
Ví dụ:
Trong 1 ngôi trường: chúng ta N bài tập , K lớp học , mỗi lớp học có J học sinh ( N > K * J hoặc N = K*J ) và nhiệm vụ là phân chia N bài tập này cho j học sinh. Ở đây mình sẽ lấy các con số cụ thể cho các bạn dễ hình dung.
Nên bài toán sẽ trở thành: 2048 bài tập , 32 lớp học, 32 bạn học sinh mỗi lớp. Nhiệm vụ của chúng ta sẽ phân chia 2048 bài tập này cho các bạn học sinh giải quyết. Thì ở đây chúng ta sẽ chia mỗi lớp xử lí 64 bài tập ( 32 * 64 = 2048 ), tức là mỗi bạn học sinh sẽ xử lí 2 bài tập.
Vì mỗi bạn học sinh sẽ có tốc độ giải bài tập khác nhau dẫn đến tốc độ hoàn thành của mỗi lớp là khác nhau. Nhưng 1 điểm thú vị ở đây là sự đồng bộ giữa các bạn học sinh trong cùng 1 lớp tức là khi hoàn thành xong 1 bài tập thì các bạn sẽ đợi cho đến khi người cuối cùng ( người chậm nhất ) giải xong 1 bài tập đó thì các bạn học sinh mới bắt đầu chuyển qua làm bài thứ 2
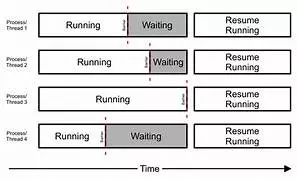
Thì ở đây các bạn học sinh là các thread và lớp học là block, N bài tập là data. Giống như ví dụ đã đề cập thì các block sẽ có tốc độ hoàn thành công việc khác nhau ( chứ không tuần tự ) và các thread trong cùng 1 block cũng có tốc độ hoàn thành công việc khác nhau nhưng sẽ được đồng bộ tức là giống như bức hình trên ( chỉ thực hiện công việc kế tiếp khi và chỉ khi thread chậm nhất hoàn thành )
Lý do tại sao đồng bộ là vì cơ chế warp mỗi lần chỉ lấy 32 công việc cho 32 thread ( này mình đã giải thích ở mục Warp trong bài viết này)
Và để tránh trường hợp chỉ vì đợi 1 người mà dẫn đến ảnh hưởng chung cho mọi người nên chúng ta có thêm khái niệm Latency Hiding.
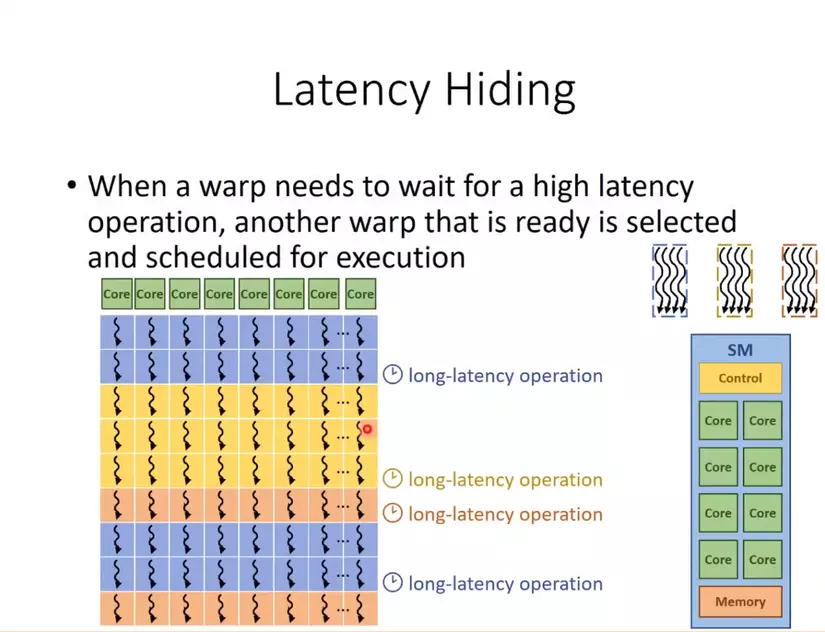
Như trong hình, khi 1 warp được thực thi nhưng nếu thời gian tốn quá lâu ( có thể do đợi 1 số thread chậm chạp) thì chúng ta có 1 cơ chế tự động là thay vì đợi thì 1 warp khác sẽ tự động được thay thế để thực hiện ( tức là sẽ có 32 bài tập mới cho 32 bạn xử lí)
Nhờ có điều này mà các thread luôn bận rộn hay nói cách khác là chúng ta nên always keep thread busy.
Và vì cơ chế đồng bộ nên chúng ta sẽ gặp hiện tưởng gọi là thread divergence( hiện tượng này khá là ảnh hưởng đến performance của chúng ta )
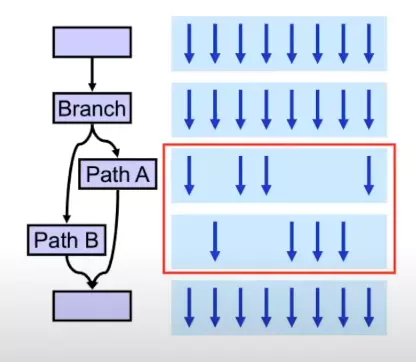
Thread divergence là hiện tượng xảy ra khi các thread thực hiện các phép tính khác nhau hoặc khi gặp điều kiện rẽ nhánh (branching) thì vì cơ chế đồng bộ nên chúng sẽ phải đợi lẫn nhau.
Tức là thay vì xử lí song song Path A và Path B thì ở đây phải tuần tự, tức là các thread thỏa mãn Path A thì làm còn các thread thỏa mãn Path B phải đợi cho đến khi xong Path A thì mới làm.
Tóm tắt
Các thread trong cùng 1 block thì synchronize nhưng chỉ khi qua công việc tiếp theo chứ trong cùng 1 công việc thì vẫn là asynchronize ( giống như tốc độ giải bài tập của các bạn học sinh mà mình đã ví dụ), các block ( hay còn gọi là các thread khác block ) thì sẽ là asynchronize
Qua bài viết này thì các bạn có lẽ đã hình dung lý do tại sao chúng ta lại có output như vậy
Nếu các bạn thấy bài viết này hay thì xin hãy cho mình 1 star ở github