Mục tiêu: tạo một mạng nơ-ron động cho phép thêm một layer ẩn mới hoặc một unit tại một layer ẩn trong Tensorflow sử dụng phương pháp Net2Net.
Note:
- Mình xin phép sử dụng Dynamic Neural network (DNN) thay cho Mạng nơ-ron động.
- Code và các tài liệu tham khảo ở cuối bài
Giới thiệu
Hầu hết các mạng neural hiện tại đều tĩnh (static neural network) vì ta cần phải xác định số lượng các layer ẩn và các unit cho mỗi layer ẩn. Thông thường, sau khi đã tạo model thì sẽ khó có thể chỉnh sửa model vì sẽ ảnh hưởng tới các trọng số đã được huấn luyện trước đó. Chỉnh sửa ở đây là ta muốn thêm một vài layer hoặc (và) thêm một vài unit vô model đã được tạo ra.
Ví dụ: một model có 3 layer lần lượt là layer_1 (4 units) -> layer_2 (5 units) -> layer_3 ( 2 units).
Ta muốn thêm layer_4 (7 units) vào giữa layer_2 và layer_3. Lúc này ta được : layer_1 (4 units) -> layer_2 (5 units) -> layer_4 (7 units) -> layer_3 ( 2 units).
Nhưng trong thực tế, các đặc trưng của dữ liệu có thể phát triển hay tăng cường một cách nhanh chóng so với dữ liệu ban đầu. Ví dụ như ban đầu chỉ cần detect 1 loại chó Alaska nên ta sẽ huấn luyện một model tối ưu với loại chó này. Nhưng sau đó, ta cần detect loại chó khác là Husky và Pug cũng với dữ liệu ảnh có cả chó Alaska. Vì vậy ta có thể sử dụng lại model đã huấn luyện trên Alaska để train tiếp cho Husky và Pug. Vấn đề ở đây là model đã được gọi là tối ưu với số lượng layer và các số node (=units) tại mỗi layer nên các đặc trưng mới của chó Husky và Pug khó mà detect tốt được thông qua sự giới hạn kích thước của model. Tương tự cho các bài toán âm thanh, ban đầu chỉ có âm thanh của 1 người rồi tới 2 người, 3 người. Hay với đồ thị mạng xã hội ban đầu chỉ có 100 đỉnh (100 người tham gia mạng xã hội ) sau đó một thời gian đã có thêm 50 người nữa đăng ký. Nhìn chung, đặc trưng của dữ liệu có thể tăng theo thời gian vì vậy các model với kích thức cũ khó mà đáp ứng và học được hết những thứ mới được thêm vào.
Một giải pháp cho vấn đề này là ta cần một model mới với kích thước mới để thích hợp với bộ dữ liệu đã phát triển mà vẫn đầy đủ các đặc trưng từ model đã được huấn luyện. Đây là một dạng transfer learning với kích thước model có thể chỉnh sửa thay vì chỉ huấn luyện thêm các đặc tính phát sinh với kích thước model đã cố định. Ta sẽ xác định một vài yêu cầu cần thực hiện như sau: Một model được tạo ra từ model cũ với có khả năng
- Thêm một layer ẩn mới vào model.
- Thêm một số units vào một layer ẩn
- Vẫn giữ nguyên được các đặc trưng đã học
Từ đó ta chỉ cần tiếp tục huấn luyện model mới này để học thêm các đặc trưng mới.
Net2Net dựa trên tư tưởng này, cho phép ta có thể đáp ứng được các yêu cầu trên như thêm layer ẩn hoặc thêm units vào layer để tăng kích thước của model ban đầu. Đây là một kỹ thuật để chuyển thông thông tin trong một neural network sang một neural network khác một cách nhanh chong. Muc tiêu chính là tăng tốc huấn luyện đặc biệc trên các neural network lớn. Trong quy trình thực tế, ta thường thiết kế rất nhiều các model cho các thử nghiệm rồi chọn model tốt nhất. Điều này sẽ rất tốn thời gian nếu luôn phải huấn luyện lại từ đầu. Chính vì vậy, _Net2Net sẽ giúp tăng tốc quy trình thử nghiệm bằng cách chuyển đổi thông tin ngay lập tức từ một mạng cũ sang một mạng mới sâu hơn (deeper) và rộng hơn (wider).
Net2Net chia thành 2 phần chính là Net2Deeper và Net2Wider. Với
- Net2Deeper: dùng để thêm một layer ẩn vào một ví trí cụ thể. Cho phép model sâu hơn với mong muốn học được các thuộc tính phức tạp hơn
- Net2Wider: dùng để thêm units vào một layer ẩn. Tức là làm cho kích thước của một layer ẩn nhiều hơn. Ví dụ layer từ 3 units thành layer có 5 units. Phương pháp này còn mở rộng cho cả Convolutional Neural network (CNN). Nhưng do mình không biết về CNN nên chỉ tập trung mà một model fully connected (FC).
Phương pháp
Giả sử một neural network cũ được đại diện bởi một hàm trong đó là đầu vào, là kết quả đầu ra và là trọng số của mạng . Mục tiêu của ta là chọn ra một tập hợp các trọng số cho neural network mới sao cho $$ \forall x, f(x;\theta) = g(x, \theta ') $$. Một layer được biểu diễn , trong đó là kích hoạt của hidden layer , là ma trận trọng số của layer và là một hàm kích hoạt. Cách khởi tạo bộ trọng số mà vẫn bảo toàn các tính chất ban đầu mang một vài lợi thế hơn các các tiếp cân khác trên network: - Mạng mới với kích thước lớn hơn lập tức thể hiện tốt như mạng gốc, thay vì tốn thời gian để huấn luyện vượt qua khoảng thời gian có kết quả thấp. - Bất kì thay đổi nào của network sau khi khởi tạo chắc chắn là một bước cải tiến, miễn là mỗi bước cực tiểu địa phương là một cải tiến. - Luôn luôn là an toànđể tối ưu hóa tất cả các tham số trong mạng. Không bao giờ có một giai đoạn mà một số layer ảnh hưởng xấu đến gradient và không được thay đổi.
1. Net2DeeperNet
 Hàm biến đổi Net2DeeperNet cho phép biến đổi một mạng cũ thành mạng mới sâu hơn. Hàm này thay layer thành layer sau đây: . Ma trận mới được khởi tạo là một ma trận đơn vị. Hàm này chỉ thích hợp khi được chọn sao cho cho tất cả các vector . Một ví dụ của là hàm ReLU.
** 2. Net2WiderNet**
Hàm biến đổi Net2DeeperNet cho phép biến đổi một mạng cũ thành mạng mới sâu hơn. Hàm này thay layer thành layer sau đây: . Ma trận mới được khởi tạo là một ma trận đơn vị. Hàm này chỉ thích hợp khi được chọn sao cho cho tất cả các vector . Một ví dụ của là hàm ReLU.
** 2. Net2WiderNet** 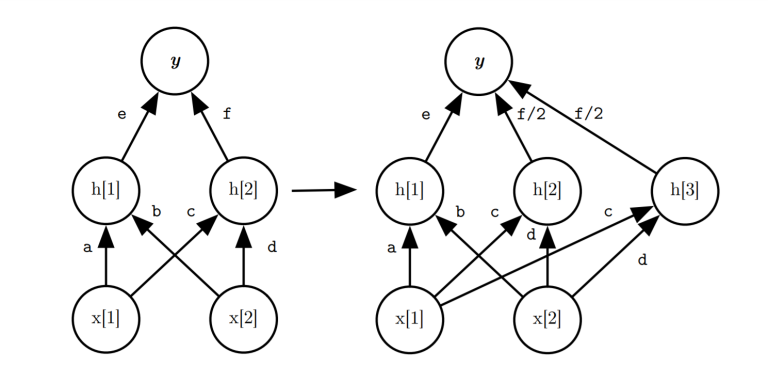
Hàm chuyển đổi Net2WiderNet dùng để thay thế bằng một layer có kích thước lớn hơn, nghĩa là layer đó có nhiều hidden units hơn. Ta có layer và layer là kết nối đầy đủ (fully connected) với nhau. Để mở rộng kích thước của layer , ta thay thế và bằng một layer có đầu ra kích thước với .
Tác giả giới thiệu một ma trận trọng số mới và để đại diện cho mạng mới như sau:
$$ U_{k,j}^{(i)} = W_{k,g(j)}^{(i)}, U_{j,h}^{(i+1)} =\frac{1}{|{x|g(x) = g(j)}|}W_{g(j),h}^{(i+1)}$$
Trong đó, là một hàm ánh xạ ngẫu nhiên thỏa mãn $$ g(j) = \begin{cases} j & \quad j \leq n \ \text{ngẫu nhiên trong} {1,2,…,n} & \quad j > n \end{cases} $$ cột đầu tiên của ma trận được sao chép trực tiếp sang , cột từ tới được tạo từ hàm . Đối với trọng số của , ta phải đếm số lần đã sử dụng để chia đều theo công thức , như vậy tất cả các units có chính xác giá trị như unit của mạng gốc ban đầu. - - - - -
Cài đặt
Phần này ta sẽ hiện thực lại ý tưởng Net2Net sử dụng Tensorflow để tạo model và numpy để sử lý các trọng số cho model mới. Đồng thời cho ta nhìn một cách tổng quan một Dynamic Neural Network sẽ linh động hơn trong việc thiết kế model.
1. Net2Deeper
def net2deeper(weights): _, out = weights.shape new_weights = np.array(np.eye(out)) new_bias = np.zeros((out,)) return new_weights, new_bias
Đầu vào là ma trận , chính là layer mà ta muốn thêm vào một layer nữa tại vị trí trong một dãy các layer của model. np.eye cho ra một ma trận đơn vị có chiều là kích thước của layer thứ .
2. Net2Wider
def net2wider(weights1, bias1, weights2, added_size): ''' Wider layer i. Making layer i has more units :param weights1: weight matrix of layer i :param bias1: bias matrix of layer i :param weights2: weight matrix of layer i + 1. Next layer of layer i :param added_size: the added number of units for layer i :return: new weight, bias for layer i, and new weight for layer i + 1 after wider layer i ''' # random index array whose values from [0, current_size_layer] with size = added_size. rand_idx = np.random.randint(weights1.shape[1], size=added_size) # count how many index is repeated in rand_idx array (histogram of array.) replication_factor = np.bincount(rand_idx) new_weights1 = weights1.copy() new_bias1 = bias1.copy() new_weights2 = weights2.copy() for i in range(len(rand_idx)): unit_index = rand_idx[i] # update wider layer (called layer K) new_unit = weights1[:, unit_index] new_unit = new_unit[:, np.newaxis] new_weights1 = np.concatenate((new_weights1, new_unit), axis=1) new_bias1 = np.append(new_bias1, bias1[unit_index]) # update next wider layer (called layer K+1) factor = replication_factor[unit_index] + 1 new_unit = weights2[unit_index, :] * (1. / factor) new_unit = new_unit[np.newaxis, :] new_weights2 = np.concatenate((new_weights2, new_unit), axis=0) new_weights2[unit_index, :] = new_unit return new_weights1, new_bias1, new_weights2
Đầu vào của hàm này gồm ma trận trọng số của layer i và layer kế tiếp của layer i là layer i+1. Trong code biểu diễn layer i là weights1, layer i+1 là weights2. weights có kích thước là số units của layer đằng trước nó liên kết tới số units tại layer hiện tại. Ví dụ, layer i có weights.shape = (3, 4) tức là số units của layer i-1 có 3 units và số units của layer i là 4. Ta có rand_idx là một mảng chỉ số ngẫu nhiên được chọn trong khoảng từ [1, n], với n là số unit của layer trước khi ta mở rộng. replication_factor là một mảng dùng để lưu lại số lần một unit được sử dụng. factor là số lần sử dụng lại (sao chép trọng số) của một unit cho các unit mở rộng.
2. Tạo model
Ta tạo một class gọi là Layers để lưu lại tất cả các layer của model. Kích thước mỗi layer được quản lý bởi mảng hidden_dims.
class Layers(Layer): def __init__(self, hidden_dims=None): super(Layers, self).__init__() self.layers = [] for i, dim in enumerate(hidden_dims): layer = Dense( units=dim, activation=tf.nn.relu, ) self.layers.append(layer) def call(self, inputs): z = inputs for layer in self.layers: z = layer(z) return z
Tiếp đến, ta tạo một model.
class MyModel(Model): def __init__(self, hidden_dims=None, v1=0.01, v2=0.01): super(MyModel, self).__init__() if hidden_dims is None: hidden_dims = [256, 512] self.custom_layers = Layers(hidden_dims=hidden_dims) def call(self, inputs): return self.custom_layers(inputs)
3. Mở rộng kích thước model
Ta chỉ cần thêm vào class Layers các hàm Wider và Deeper với mục đích thêm các units vào layer và thêm một layer có cùng kích thước vào model. Ví dụ: 1 model đang có 2 hidden layers với layer cuối cùng là layer đầu ra, nếu tính cả đầu vào thì ta có thêm 1 layer input.  Giả sử tất cả đều là fully connected. Ta muốn mở rộng layer 1 (layer input là layer 0, tính hidden layer đầu tiên là 1) từ 2 units thành 3 units như hình bên phải. Vậy để mở rộng, ta chỉ cần lấy được ma trận và để xử lý các trọng số thành ma trận và $W_{1 \times 3}. Việc này đồng nghĩa với việc ta thêm một unit vào layer 1 từ hiện tại 2 units thành 3 units. Trong tensorfow, một layer ta chỉ cần gọi hàm
Giả sử tất cả đều là fully connected. Ta muốn mở rộng layer 1 (layer input là layer 0, tính hidden layer đầu tiên là 1) từ 2 units thành 3 units như hình bên phải. Vậy để mở rộng, ta chỉ cần lấy được ma trận và để xử lý các trọng số thành ma trận và $W_{1 \times 3}. Việc này đồng nghĩa với việc ta thêm một unit vào layer 1 từ hiện tại 2 units thành 3 units. Trong tensorfow, một layer ta chỉ cần gọi hàm get_weights và hàm set_weights để thực hiện 2 mục đích trên. Sau đây là code cho phần wider, còn deeper thì chỉ cần thêm hẳn 1 layer mới vào một mảng layer đang có sẵn.
def wider(self, added_size=1, pos_layer=None): layers_size = len(self.layers) if layers_size < 2: raise ValueError("Number of layer must be greater than 2.") if pos_layer is None: pos_layer = max(layers_size - 2, 0) elif pos_layer >= layers_size - 1 or pos_layer < 0: raise ValueError(f"pos_layer is expected less than length of layers (pos_layer in [0, layers_size-2])") weights, bias = self.layers[pos_layer].get_weights() weights_next_layer, bias_next_layer = self.layers[pos_layer + 1].get_weights() new_weights, new_bias, new_weights_next_layer = net2wider(weights, bias, weights_next_layer, added_size) src_units, des_units = weights.shape[0], weights.shape[1] + added_size next_des_units = weights_next_layer.shape[1] wider_layer = Dense( units=des_units, activation=tf.nn.relu, ) # input_shape = (batch_size, input_features). # input_features = number of units in layer = length(layer) = output of previous layer wider_layer.build(input_shape=(1, src_units)) wider_layer.set_weights([new_weights, new_bias]) next_layer = Dense( units=next_des_units, activation=tf.nn.relu, ) next_layer.build(input_shape=(1, des_units)) next_layer.set_weights([new_weights_next_layer, bias_next_layer]) self.layers[pos_layer] = wider_layer self.layers[pos_layer + 1] = next_layer
Chú ý với mỗi layer được tạo ra, ta cần phải biết số units mà layer đó có và số units layer đằng trước nó sẽ được kết nối. Ta thấy, với mỗi Dense là một layer fully connected, tham số units là số units layer có. Gọi hàm build để biết kích thước đầu vào của layer, tức là số lượng units của layer nằm kề trước.