Ở phần 1 mình đã giới thiệu occupancy thì ở phần 2 mình sẽ đi sâu hơn về occupancy trong việc cải thiện achieved occupancy
Trước khi đi vào bài học mình xin giải thích 2 khái niệm khá quan trọng trong bài viết này:
- Tail effect: nếu tổng số thread không chia hết cho warp(32) thì lúc này sẽ xuất hiện tail effect, tail effect là số thread còn lại được chạy cuối cùng trong warp, số thread còn lại càng bé thì tail effect càng ảnh hưởng lớn ==> dẫn đến chương trình chậm
- Ví dụ: ta có data với N =80 và số thread là 40 ==> ta sẽ cần 2 warp để asign 40 thread thì wap thứ 2 chỉ sử dụng 8 thread ==> phí tài nguyên và vì N=80 tức là sẽ sử dụng 4 warp trong khi chúng ta chỉ cần 3 warp là đủ
- waves: là 1 tên khác để gọi warp
Achieved Occupancy
Theoretical occupancy cho chúng ta biết giới hạn trên ( upper - bound ) của các active warps trên 1 SM. Tuy nhiên, trong thực tế, các thread trong các block có thể thực thi với tốc độ khác nhau và có thể kết thúc các phần thực thi của chúng ở các thời điểm khác nhau. Do đó, số lượng warp thực tế hoạt động trên mỗi SM sẽ biến động theo thời gian, phụ thuộc vào cách thức thực thi của các thread trong các block.
Vì vậy chúng ta mới có thêm khái niệm mới - Achieved occupancy để giải quyết vấn đề này: Achieved occupancy sẽ xem xét trên warp schedulers và sử dụng Hardware performance counters để mà xác định các active warp mỗi clock cycle.
Các bạn có thể xem bài warp schedulers để hiểu rõ hơn
Những nguyên nhân khiến Low Achieved occupancy
Chúng ta sẽ kiểm tra xem Achieved có gần với gTheoretical không. Achieved sẽ thấp hơn Theoretical khi số lượng active warp không được duy trì suốt thời gian SM hoạt động. Điều này có thể xảy ra khi không đủ thread cho các warp hoặc khi sự chia sẻ tài nguyên không hiệu quả dẫn đến stall active warp khi thực thi kernel trên GPU.
Achieved occupancy không thể vượt qua Theoretical occupancy, do đó trước hết chúng ta sẽ dùng thread config để đạt 100% Theoretical occupancy. Sau đó kiểm tra xem sự chênh lệch giữa Achieved - Theoretical, nếu có sự chênh lệch lớn thì sẽ do những nguyên nhân sau đây:
Unbalanced workload within blocks
Nếu các warp trong 1 block không thực thi cùng 1 lúc thì chúng ta đã gặp vấn đề Unbalanced trong block ( Có thể hiểu là số lượng thread trong 1 block quá nhiều dẫn đến 1 vài warp bị stalled, vì mỗi thread sẽ có 1 số lượng register nhất định ) và khi chúng ta sử dụng nhiều thread trong 1 block ==> less utilization ở các warp cuối ==> xuất hiện tail effect
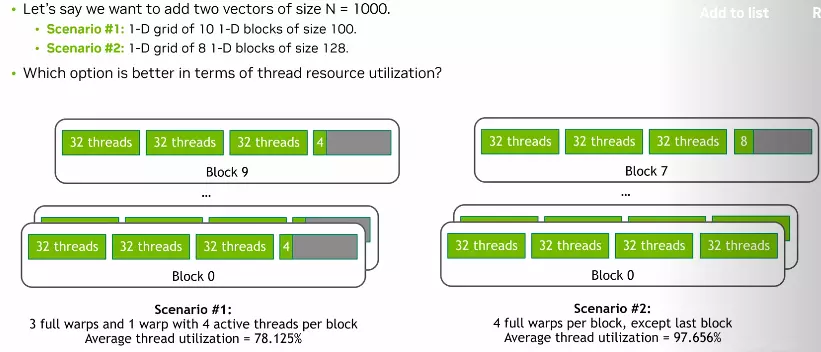 Thay vì sử dụng tối đa thread trong 1 block (1024 thread) thì hãy cân nhắc và lựa chọn cho phù hợp với data
Thay vì sử dụng tối đa thread trong 1 block (1024 thread) thì hãy cân nhắc và lựa chọn cho phù hợp với data
Unbalanced workload across blocks
Nếu các block không thực thi cùng 1 lúc trong mỗi SM thì chúng ta cũng gặp vấn đề Unbalanced trong grid ( Có thể hiểu là số lượng block trong mỗi SM quá nhiều dẫn đến stall) chúng ta có thể khắc phục bằng cách thay đổi số block trong grid hoặc là sử dụng stream để chạy các kernel 1 cách đồng thời
Các bạn có thể xem lại bài streaming để hiểu rõ hơn. Và để trả lời câu hỏi chia bao nhiêu stream là thích hợp thì hãy chia sao mà hạn chế tail effect của mỗi thread trong block
Too few blocks launched
Chúng ta không sử dụng tối đa SM ( số lượng block sử dụng ít hơn số lượng block có thể chạy cùng 1 lúc trong SM ). Hiện tượng full waves - full warps xảy ra khi tổng số SM * tổng số active warp trong mỗi SM
Ví dụ: ta có 15 SM và 100% theoretical occupancy với 4 blocks mỗi SM ==> full waves là 60 blocks, nếu chỉ dùng 45 blocks ==> chỉ đạt được 75% achieved occupancy