Đóng góp của bài báo
Bài báo đề xuất một mô hình transformer thuần có tên là ViViT sử dụng cho bài toán video classification. Thao tác chính vẫn là sử dụng self attention cho chuỗi các spatio-temporal (không gian-thời gian) token được trích xuất từ video đầu vào 😀 Để xử lý hiệu quả một lượng lớn các spatio-temporal token có thể gặp trong video, nhóm tác giả đề xuất một số phương pháp phân tích mô hình theo chiều spatial và temporal nhằm tăng độ hiệu quả và khả năng mở rộng. Ngoài ra, để train model hiệu quả trên tập dữ liệu nhỏ, nhóm tác giả thực hiện reguliarise model trong suốt quá trình training và tất nhiên sẽ tận dụng thêm các pretrained image model nữa 😀 Tổng quan mô hình trong hình dưới đây:
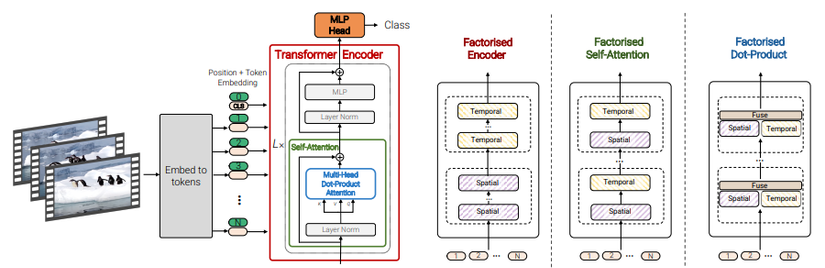
Mô hình đạt kết quả SOTA trên các benchmark cho bài toán video classification như Kinetics 400, Kinetics 600, Epic Kitchens 100, Something-Something v2 và Moments in Time.
Phương pháp
Tổng quan về Vision Transformer
Để hiểu về mô hình Transformer dùng cho video, ta sẽ ngó lại chút xem mô hình Transformer dùng cho hình ảnh (model ViT) như nào 😀
Mô hình ViT nhận đầu vào là patch ảnh không chồng nhau, kí hiệu là . Các patch ảnh này sẽ đi qua một trainable linear projection, đầu ra sẽ là các patch embedding. Các patch embedding này được concat thành các token . Cụ thể được xác định như sau:
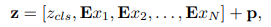
là learnable token được thêm vào chuỗi các embedded patch. Ngoài ra, chuỗi các embedded patch được cộng với learned positional embedding với mục tiêu duy trì thông tin vị trí.
Các token tiếp tục được đưa vào một encoder bao gồm một chuỗi các transformer layer. Mỗi layer chữa các thành phần Multi-Headed Self-Attention, layer normalisation (LN) và các MLP block như sau:
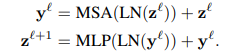
MLP bao gồm 2 lớp linear projection, ở giữa 2 lớp này là một hàm activation phi tuyến tính GELU. Chiều của các token là được giữ cố định qua các layer.
Embedding video clips
Bài toán bây giờ đặt ra là làm cách nào để có thể embed được video và đưa vào mô hình😀
Dựa vào ý tưởng cơ bản từ mô hình ViT, nhóm tác giả thực hiện nghiên cứu 2 method để map từ một video sang chuỗi các token . Sau đó ta sẽ cộng thêm positional embedding và reshape thành để thu được và sẽ là đầu vào của transformer.
Cách đầu tiên là Uniform frame sampling được mô tả trong hình dưới:
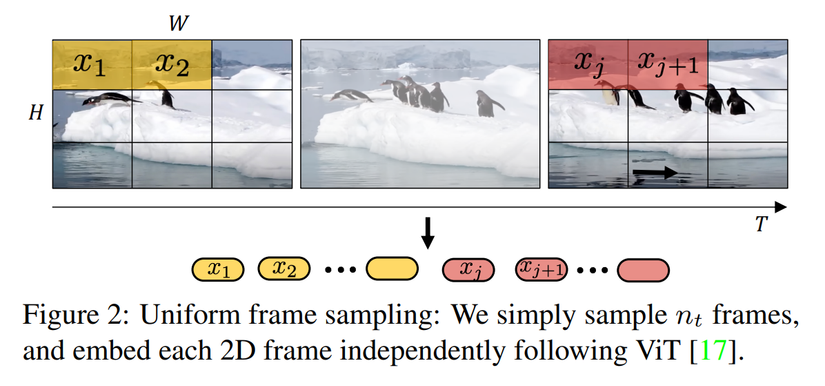 Đây là cách làm khá đơn giản và tường minh, ta thực hiện lấy mẫu frame, sau đó thực hiện embed các frame này như trong mô hình ViT và sau đó concat các token lại với nhau. Theo cách này, ta sẽ có tổng cộng token được đưa vào transformer encoder.
Đây là cách làm khá đơn giản và tường minh, ta thực hiện lấy mẫu frame, sau đó thực hiện embed các frame này như trong mô hình ViT và sau đó concat các token lại với nhau. Theo cách này, ta sẽ có tổng cộng token được đưa vào transformer encoder.
Cách embed 2D patch được cài đặt sử dụng Jax như sau:
def embed_2d_patch(x, patches, embedding_dim): """Standard ViT method of embedding input patches.""" n, h, w, c = x.shape assert patches.get('size') is not None, ('patches.size is now the only way' 'to define the patches') fh, fw = patches.size gh, gw = h // fh, w // fw if embedding_dim: x = nn.Conv( embedding_dim, (fh, fw), strides=(fh, fw), padding='VALID', name='embedding')(x) else: # This path often results in excessive padding: b/165788633 x = jnp.reshape(x, [n, gh, fh, gw, fw, c]) x = jnp.transpose(x, [0, 1, 3, 2, 4, 5]) x = jnp.reshape(x, [n, gh, gw, -1]) return x
Cách thứ 2 là Tubelet embedding được mô tả trong hình dưới:
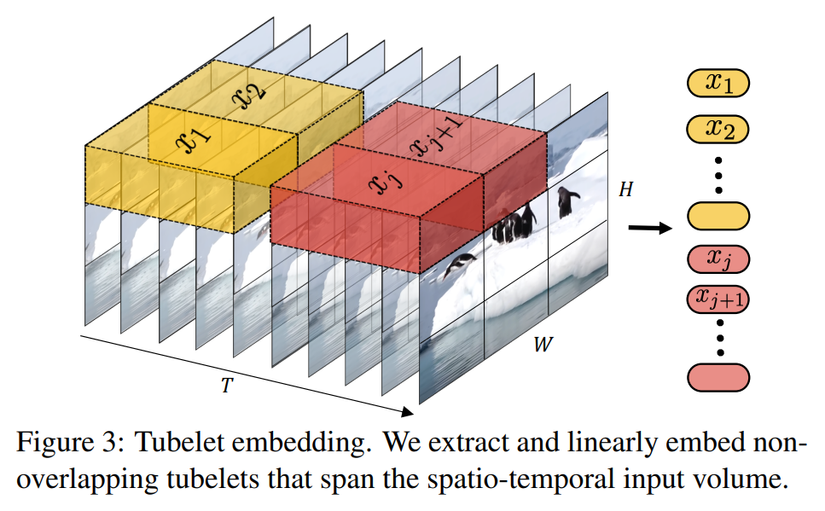
Thay vì trích xuất các frame riêng lẻ, ta sẽ trích xuất các "ống" (tube) spatio-temporal từ input và sau đó đi qua lớp linear projection để chuyển về chiều . Đây chính là phiên bản mở rộng của ViT embedding lên 3D và do đó sẽ sử dụng 3D convolution. Một tube sẽ có 3 chiều là , mỗi token được trích xuất theo chiều temporal, height và width tương ứng như sau . Chiều của các tube càng nhỏ thì càng nhiều token và làm tăng chi phí tính toán. Cách embedding video này khác với cách đầu tiên ở chỗ, cách Uniform frame sampling là lấy các frame rời rạc và tổng hợp thông tin temporal trong transformer encoder còn cách Tubelet embedding sẽ tổng hợp được luôn thông tin spatio-temporal 😀
Cách cài đặt 3D patch sử dụng Jax như sau:
def embed_3d_patch(x, patches, embedding_dim, kernel_init_method, name='embedding'): """Embed 3D input patches into tokens.""" assert patches.get('size') is not None, 'patches.size must be defined' assert len(patches.size) == 3, 'patches.size must have 3 elements' assert embedding_dim, 'embedding_dim must be specified' fh, fw, ft = patches.size x = nn.Conv( embedding_dim, (ft, fh, fw), strides=(ft, fh, fw), padding='VALID', name=name, kernel_init=kernel_initializer)( x) return x
Mô hình Transformer cho video
Nhóm tác giả đề xuất các kiến trúc transformer-based cho video bao gồm 4 model.
Model 1: Spatio-temporal attention
Đầu tiên ta thực hiện tokenize video sử dụng Tubelet embedding như đã trình bày ở phần trước. Sau khi tokenize, ta thực hiện cộng các patch embedding với positional embedding. Cuối cùng, các spatio-temporal token được truyền vào transformer encoder. Mỗi lớp transformer sẽ mô hình hóa tất cả tương tác giữa các spatio-temporal token và do đó sẽ mô hình được các tương tác dài hạn trong video. Tuy nhiên, Multi-Headed Self Attention (MSA) có độ phức tạp bậc 2 tương ứng với số lượng token. Vấn đề này đặc biệt khoai đối với dữ liệu đầu vào là video. Khi số frame trong video tăng thì độ phức tạp cũng ngày càng lớn hơn 😀
Một encoder block cơ bản được cài đặt như sau:
class EncoderBlock(nn.Module): """Transformer encoder block. Attributes: mlp_dim: Dimension of the mlp on top of attention block. num_heads: Number of heads. attention_axis: Axis over which we run attention. dropout_rate: Dropout rate. attention_dropout_rate: Dropout for attention heads. droplayer_p: Probability of dropping a layer. attention_kernel_initializer: Initializer to use for attention layers. deterministic: Deterministic or not (to apply dropout). attention_fn: dot_product_attention or compatible function. Accepts query, key, value, and returns output of shape `[bs, dim1, dim2, ..., dimN,, num_heads, value_channels]`` dtype: The dtype of the computation (default: float32). Returns: Output after transformer encoder block. """ mlp_dim: int num_heads: int dtype: jnp.dtype = jnp.float32 dropout_rate: float = 0.1 attention_dropout_rate: float = 0.1 attention_kernel_initializer: Initializer = nn.initializers.xavier_uniform() attention_fn: Any = nn.dot_product_attention droplayer_p: float = 0.0 def get_drop_pattern(self, x, deterministic): if not deterministic and self.droplayer_p: shape = (x.shape[0],) + (1,) * (x.ndim - 1) return jax.random.bernoulli( self.make_rng('dropout'), self.droplayer_p, shape).astype('float32') else: return 0.0 @nn.compact def __call__(self, inputs: jnp.ndarray, deterministic: bool) -> jnp.ndarray: """Applies Encoder1DBlock module.""" # Attention block. x = nn.LayerNorm(dtype=self.dtype)(inputs) x = nn.MultiHeadDotProductAttention( num_heads=self.num_heads, kernel_init=self.attention_kernel_initializer, broadcast_dropout=False, dropout_rate=self.attention_dropout_rate, attention_fn=self.attention_fn, dtype=self.dtype)( x, x, deterministic=deterministic) x = nn.Dropout(rate=self.dropout_rate)(x, deterministic) drop_pattern = self.get_drop_pattern(x, deterministic) x = x * (1.0 - drop_pattern) + inputs # MLP block. y = nn.LayerNorm(dtype=self.dtype)(x) y = attention_layers.MlpBlock( mlp_dim=self.mlp_dim, dtype=self.dtype, dropout_rate=self.dropout_rate, activation_fn=nn.gelu, kernel_init=nn.initializers.xavier_uniform(), bias_init=nn.initializers.normal(stddev=1e-6))( y, deterministic=deterministic) drop_pattern = self.get_drop_pattern(x, deterministic) return y * (1.0 - drop_pattern) + x
Model 2: Factorised encoder
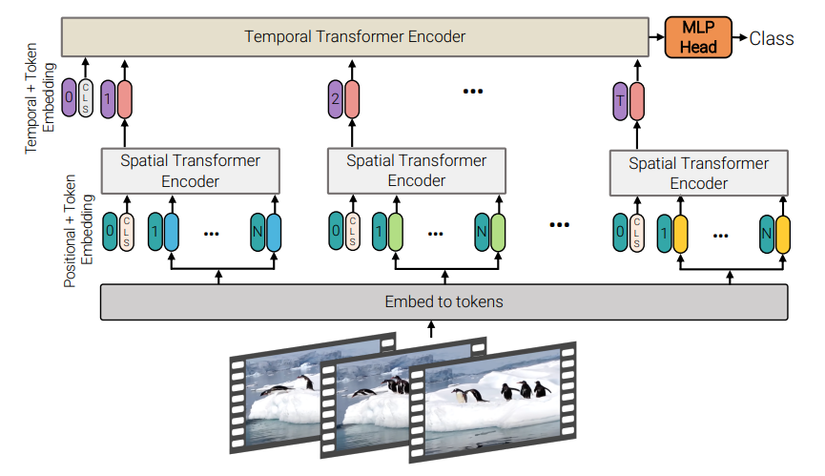
Như trong hình trên, mô hình gồm 2 loại transformer encoder phân biệt. Sở dĩ mô hình được gọi là Factorised encoder bởi vì ta không dùng cùng 1 encoder cho tất cả các token trong video, thay vào đó ta tách ra làm 2 encoder phân biệt.
Transformer encoder đầu tiên là spatial encoder có cấu trúc khá tương tự như một Transformers encoder chuẩn thông thường. Spatial encoder có nhiệm vụ chỉ mô hình hóa tương tác giữa các token được trích xuất từ cùng temporal index (cùng temporal index và khác spatial index). Cụ thể, video được chia thành các clip. Mỗi clip được chia thành các tube và mỗi tube sẽ như là một token. Ta sẽ đưa các tube và token CLS vào spatial transformer. Đầu ra của spatial encoder là global average pooling từ các encoded token hoặc chỉ là CLS token được trích xuất từ clip (nếu như token CLS được thêm vào input ban đầu).
Các biểu diễn này sau đó được concat và đưa vào temporal encoder bao gồm lớp transformer để mô hình hóa tương tác giữa các token từ các temporal index khác nhau. Temporal encoder cũng giống như một Transformers encoder chuẩn. Đầu ra của temporal encoder được đưa vào một MLP head và trả về label cho video.
Mặc dù mô hình này có nhiều lớp transformer hơn Model 1 (và tất nhiên sẽ nhiều tham số hơn) nhưng nó yêu cầu ít FLOP hơn vì 2 khối transformer có độ phức tạp tổng là , tốt hơn nhiều so với của model 1.
Code cài đặt như sau:
class SpaceTimeViViT(nn.Module): """ViT model for Video with factorized space-time attention.""" spatial_mlp_dim: int spatial_num_layers: int spatial_num_heads: int temporal_mlp_dim: int temporal_num_layers: int temporal_num_heads: int num_classes: int patches: ml_collections.ConfigDict hidden_size: int temporal_encoding_config: ml_collections.ConfigDict attention_config: ml_collections.ConfigDict representation_size: Optional[int] = None dropout_rate: float = 0.1 attention_dropout_rate: float = 0.1 stochastic_droplayer_rate: float = 0. classifier: str = 'gap' return_prelogits: bool = False dtype: jnp.dtype = jnp.float32 @nn.compact def __call__(self, x: jnp.ndarray, *, train: bool, debug: bool = False): del debug x, _ = temporal_encode( x, self.temporal_encoding_config, self.patches, self.hidden_size, return_1d=False) bs, t, h, w, c = x.shape x = x.reshape(bs, t, h * w, c) def vit_body(x, mlp_dim, num_layers, num_heads, encoder_name='Transformer'): # If we want to add a class token, add it here. if self.classifier in ['token']: n, _, c = x.shape cls = self.param(f'cls_{encoder_name}', nn.initializers.zeros, (1, 1, c), x.dtype) cls = jnp.tile(cls, [n, 1, 1]) x = jnp.concatenate([cls, x], axis=1) x = Encoder( temporal_dims=None, # This is unused for Factorised-Encoder mlp_dim=mlp_dim, num_layers=num_layers, num_heads=num_heads, attention_config=self.attention_config, dropout_rate=self.dropout_rate, attention_dropout_rate=self.attention_dropout_rate, stochastic_droplayer_rate=self.stochastic_droplayer_rate, dtype=self.dtype, name=encoder_name)(x, train=train) if self.classifier in ['token', '0']: x = x[:, 0] elif self.classifier in ('gap', 'gmp', 'gsp'): fn = {'gap': jnp.mean, 'gmp': jnp.max, 'gsp': jnp.sum}[self.classifier] x = fn(x, axis=list(range(1, x.ndim - 1))) return x # run attention across spacec, per frame x = jax.vmap( functools.partial( vit_body, mlp_dim=self.spatial_mlp_dim, num_layers=self.spatial_num_layers, num_heads=self.spatial_num_heads, encoder_name='SpatialTransformer'), in_axes=1, out_axes=1, axis_name='time')( x) assert x.ndim == 3 and x.shape[:2] == (bs, t) # run attention across time, over all frames if not self.attention_config.get('spatial_only_baseline', False): x = vit_body( x, mlp_dim=self.temporal_mlp_dim, num_layers=self.temporal_num_layers, num_heads=self.temporal_num_heads, encoder_name='TemporalTransformer') else: # Do global average pooling instead, as method of combining temporal info. x = jnp.mean(x, axis=list(range(1, x.ndim - 1))) if self.representation_size is not None: x = nn.Dense(self.representation_size, name='pre_logits')(x) x = nn.tanh(x) else: x = nn_layers.IdentityLayer(name='pre_logits')(x) if self.return_prelogits: return x else: x = nn.Dense( self.num_classes, kernel_init=nn.initializers.zeros, name='output_projection')(x) return x
Model 3: Factorised self-attention
Model 3 thì lại tương tự như model 1 😀 điểm khác biệt là transformer encoder block được sử dụng không phải là block transformer chuẩn thông thường. Thay vì sử dụng multi-headed self-attention (MSA) cho tất cả các cặp token, lớp MSA được tách ra làm 2 phần. Phần MSA layer đầu tiên sử dụng để tính toán attention giữa các token được trích xuất có cùng temporal index và MSA layer thứ 2 dùng để tính toán attention giữa các token được trích xuất có temporal index khác nhau. Hình dưới mô tả trực quan 2 layer này.
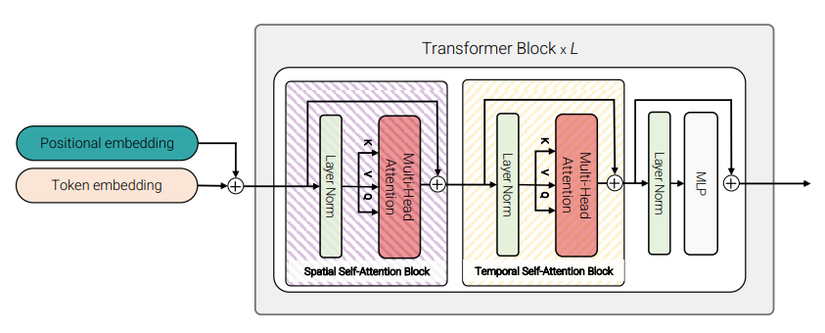
Nhóm tác giả cũng nhận thấy rằng thứ tự spatial đến temporal hay temporal đến spatial self-attention cũng không mang lại nhiều sự khác biệt. Số lượng tham số của model 3 lớn hơn model 1 do có thêm một self-attention layer.
Code cài đặt như sau:
class EncoderFactorizedSelfAttentionBlock(nn.Module): """Encoder with facctorized self attention block. Attributes: mlp_dim: Dimension of the mlp on top of attention block. num_heads: Number of heads. temporal_dims: Number of temporal dimensions in the flattened input attention_kernel_initializer: Initializer to use for attention layers. dropout_rate: Dropout rate. attention_dropout_rate: Dropout for attention heads. droplayer_p: Probability of dropping a layer. attention_order: The order to do the attention. Choice of {time_space, space_time}. dtype: the dtype of the computation (default: float32). """ mlp_dim: int num_heads: int temporal_dims: int attention_kernel_initializer: Initializer dropout_rate: float = 0.1 attention_dropout_rate: float = 0.1 droplayer_p: Optional[float] = None attention_order: str = 'time_space' dtype: jnp.dtype = jnp.float32 @nn.compact def __call__(self, inputs: jnp.ndarray, *, deterministic: bool): """Applies Encoder1DBlock module.""" b, thw, d = inputs.shape inputs = _reshape_to_time_space(inputs, self.temporal_dims) self_attention = functools.partial( nn.SelfAttention, num_heads=self.num_heads, kernel_init=self.attention_kernel_initializer, broadcast_dropout=False, dropout_rate=self.attention_dropout_rate, dtype=self.dtype) if self.attention_order == 'time_space': attention_axes = (1, 2) elif self.attention_order == 'space_time': attention_axes = (2, 1) else: raise ValueError(f'Invalid attention order {self.attention_order}.') def _run_attention_on_axis(inputs, axis, two_d_shape): """Reshapes the input and run attention on the given axis.""" inputs = model_utils.reshape_to_1d_factorized(inputs, axis=axis) x = nn.LayerNorm( dtype=self.dtype, name='LayerNorm_{}'.format(_AXIS_TO_NAME[axis]))( inputs) x = self_attention( name='MultiHeadDotProductAttention_{}'.format(_AXIS_TO_NAME[axis]))( x, deterministic=deterministic) x = nn.Dropout(rate=self.dropout_rate)(x, deterministic) x = x + inputs return model_utils.reshape_to_2d_factorized( x, axis=axis, two_d_shape=two_d_shape) x = inputs two_d_shape = inputs.shape for axis in attention_axes: x = _run_attention_on_axis(x, axis, two_d_shape) # MLP block. x = jnp.reshape(x, [b, thw, d]) y = nn.LayerNorm(dtype=self.dtype, name='LayerNorm_mlp')(x) y = attention_layers.MlpBlock( mlp_dim=self.mlp_dim, dtype=self.dtype, dropout_rate=self.dropout_rate, activation_fn=nn.gelu, kernel_init=nn.initializers.xavier_uniform(), bias_init=nn.initializers.normal(stddev=1e-6), name='MlpBlock')( y, deterministic=deterministic) return x + y
Model 4: Factorised dot-product attention
Model 4 này có độ phức tạp giống như model 2, 3 trong khi vẫn giữ lượng tham số như model 1 😀 Về cơ bản model 4 giống như model 1 về mặt kiến trúc nhưng khác ở MSA layer trong transformer block (xem hình dưới)
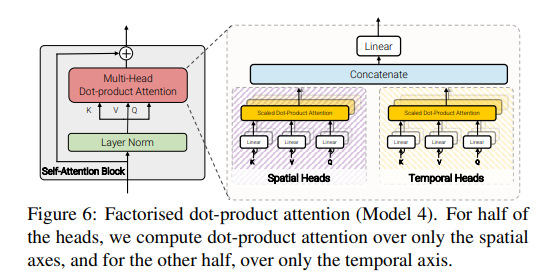
Trong MSA, nhóm tác giả tách ra làm 2 phần là spatial head và temporal head. Spatial head dùng để tính toán dot product self-attention giữa các token được trích xuất có cùng temporal index và Temporal head dùng để ùng để tính toán dot product self-attention giữa các token được trích xuất có cùng spatial index.
Dễ thấy, trong model 3 nhóm tác giả sử dụng toàn bộ head để tính toán lần lượt spatial và temporal attention, trong khi ở model 4, nhóm tác giả sử dụng các head khác nhau trong cùng MSA layer để tính toán temporal và spatial self-attention.
Code cài đặt như sau:
def factorized_dot_product_attention( query: jnp.ndarray, key: jnp.ndarray, value: jnp.ndarray, bias: Optional[jnp.ndarray] = None, broadcast_dropout: bool = True, dropout_rng: Optional[Any] = None, dropout_rate: float = 0.1, deterministic: bool = False, dtype: jnp.dtype = jnp.float32, precision: Optional[jax.lax.Precision] = None,
) -> jnp.ndarray: """Applies head-factorized qkv dot-product attention. This factorizes the dot-product attention by assigning different heads to run attention on different axes. Args: query: Queries for calculating attention with shape of `[batch..., num_heads, qk_depth_per_head]`. key: Keys for calculating attention with shape of `[batch..., num_heads, qk_depth_per_head]`. value: Values to be used in attention with shape of `[batch..., num_heads, v_depth_per_head]`. bias: Bias for the attention weights. This should be broadcastable to the shape: `[batch...]`. This can be used for incorporating causal masks, padding masks, proximity bias, etc. Default is None, which means no bias is applied on attention matrix. broadcast_dropout: Use a broadcasted dropout along batch dims. dropout_rng: JAX PRNGKey to be used for dropout. dropout_rate: Dropout rate. deterministic: Deterministic or not (to apply dropout). dtype: The dtype of the computation (default: float32). precision: Numerical precision of the computation see `jax.lax.Precision` for details. Returns: Output of shape `[bs, ..., num_heads, features]`. """ if query.shape != key.shape: raise ValueError('Axial dot product attention only supports ' 'query and key with the same shape.') if bias is not None: raise ValueError('Bias is not supported in ' 'factorized_dot_product_attention.') # Normalize the query with the square of its depth. query = query / jnp.sqrt(query.shape[-1]).astype(dtype) # Shape of query, key, and value: [bs, t, hw, h, c]. prefix_str = 'ab' # Split heads for each axial attention dimension. num_attn_dimensions = query.ndim - 3 # all dims but bs, heads, and channel. if query.shape[-2] % num_attn_dimensions != 0: raise ValueError(f'In head-axial dot-product attention, number of ' f'heads ({query.shape[-2]}) should be divisible by number ' f'of attention dimensions ({num_attn_dimensions})!') queries = jnp.split(query, num_attn_dimensions, axis=-2) keys = jnp.split(key, num_attn_dimensions, axis=-2) values = jnp.split(value, num_attn_dimensions, axis=-2) # queries, keys, and values are each a list with two arrays (sinec # we have two dims, t and hw) that are made by spliting heads: # [(bs, t, hw, h//2, c), (bs, t, hw, h//2, c)]. outputs = [] for i, (query, key, value) in enumerate(zip(queries, keys, values)): # Shape of query, key, and value: [bs, t, hw, h//2, c]. axis = i + 1 # to account for the batch dim batch_dims = prefix_str[:axis] einsum_str = f'{batch_dims}x...z,{batch_dims}y...z->{batch_dims}x...y' # For axis=1 einsum_str (q,k->a): ax...z,ay...z->ax...y # For axis=2 einsum_str (q,k->a): abx...z,aby...z->abx...y attn_logits = jnp.einsum(einsum_str, query, key, precision=precision) # For axis=1 (attention over t): attn_logits.shape: [bs, t, hw, h//2, t] # For axis=2 (attention over hw): attn_logits.shape: [bs, t, hw, h//2, hw] attn_weights = jax.nn.softmax(attn_logits, axis=-1) return jnp.concatenate(outputs, axis=-2)
Thực nghiệm
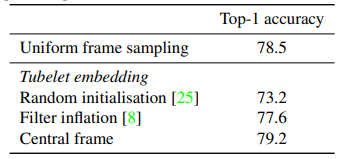
Bảng dưới là kết quả so sánh các phương pháp input encoding sử dụng ViViT-B và spatio-temporal attention trên tập dữ liệu Kinetics.
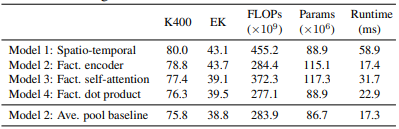
Bảng dưới là kết quả so sánh các kiến trúc model sử dụng ViViT-B là backbone. Kích thước tube là . Kết quả trong bảng là Top-1 accuracy trên tập Kinetic 400 (K400) và accuracy trên tập Epic Kitchens (EK). TPU-v3 được sử dụng trong quá trình inference.
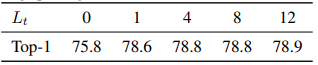
Nhóm tác giả cũng thực hiện nghiên cứu sự ảnh hưởng của số lượng temporal transformer trong model 2. Kết quả là Top-1 acccuracy trên tập Kinetics 400. nghĩa là sử dụng “average pooling baseline".
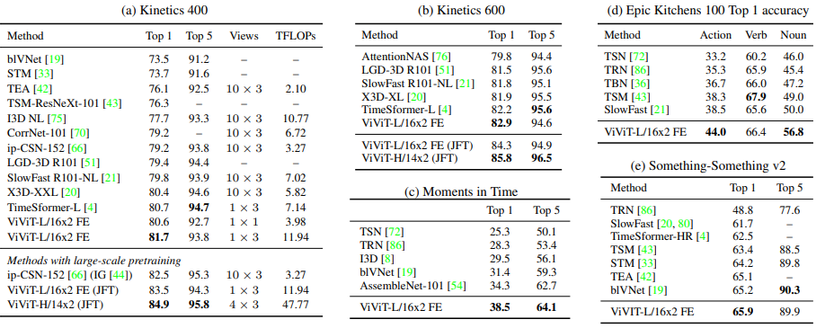
So sánh với các method khác trên nhiều tập dữ liệu khác nhau.
Tham khảo
[1] ViViT: A Video Vision Transformer
[2] https://github.com/google-research/scenic/tree/main/scenic/projects/vivit
[3] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE