Chào các bạn  ! Tại bài viết trước , mình đã chia sẽ những kiến thức ban đầu về Headless Browsers và Puppeteer cùng một ví dụ về việc khởi tạo Puppeteer cũng như thực hiện chức năng chụp ảnh từ một trang web bất kì. Tại bài viết lần này, mình sẽ cùng các bạn tìm hiểu những điều thú vị khác mà Puppeteer có thể làm được nhé. Get Started!!!!
! Tại bài viết trước , mình đã chia sẽ những kiến thức ban đầu về Headless Browsers và Puppeteer cùng một ví dụ về việc khởi tạo Puppeteer cũng như thực hiện chức năng chụp ảnh từ một trang web bất kì. Tại bài viết lần này, mình sẽ cùng các bạn tìm hiểu những điều thú vị khác mà Puppeteer có thể làm được nhé. Get Started!!!!
Một số chức năng của Puppteer
Chức năng tải xuống file PDF
Ngoài chức năng chụp ảnh màn hình, Puppeteer còn cho phép bạn tải trang xuống dưới định dạng file PDF:
Để làm điều này bạn cần sử dụng hàm: page.pdf([options])
Dưới đây là ví dụ:
import { launch } from "puppeteer"; const downloadPagePdf = async () => { const browser = await launch({ headless: false }); // khởi tạo browser const page = await browser.newPage(); // tạo một trang web mới await page.goto("https://news.sun-asterisk.com/vi"); // điều hướng trang web theo URL // Tải trang web dưới dạng PDF await page.pdf({ path: "sun.pdf", format: "a4" }); await browser.close(); // đóng trang web
};
Chức năng tải ảnh một ảnh cụ thể từ trang web
Ngoài chức năng screenshort giúp bạn lấy ra bức ảnh chụp lại toàn bộ trang web, Puppeteer còn giúp ta trích xuất 1 ảnh bất kỳ tại trang web đó bằng 2 hàm:
- page.waitForSelector(selector[, options]): Hàm thực hiện việc chờ đến khi selector mà bạn chỉ định được tìm thấy. Nếu selector được tìm thấy, hàm sẽ được chạy qua ngay lập tức. Tuy nhiên, nếu selector không được tìm thấy trong khoảng thời gian timeout, hàm sẽ thả về 1 lỗi không tìm thấy selector yêu cầu.
- page.$(selector) : Hàm tìm ra đối tượng mang selector tương ứng. Cụ thể hàm sẽ chạy
document.querySelector. Nếu không tìm được, hàm sẽ trả về giá trị null.
Sau đây là một ví dụ, mình sẽ lấy logo trang chủ Soha. Như ta thấy, xem màn hình console của trang chủ Soha, nó đang được lưu với class "logo"

Ta thực hiện code như sau:
import { launch } from "puppeteer"; const downloadSpecificImage = async () => { const browser = await launch({ headless: false }); const page = await browser.newPage(); await page.goto("https://soha.vn"); await page.waitForSelector(".logo"); // tìm đối tượng có class là "logo" // Lấy ra đối tượng có class là logo const svgImage = await page.$(".logo"); await svgImage?.screenshot({ path: "itemImage.png", omitBackground: true, }); await browser.close(); // đóng trang web
}; Vì giá trị của hàm page.$(".logo") có thể là null nên ta cần validate nó trước khi gọi hàm screenshot bằng cách thực hiện svgImage?.screenshot
Chức năng "cào" dữ liệu
Chức năng cuối cùng và cũng là chức năng mà mình cho là hữu ích nhất của Puppeteer đó là chức năng "cào" dữ liệu bằng các sử dụng hàm page.evaluate(pageFunction[, ...args])
page.evaluate cho phép ta chạy script trong browser và lấy kết quả trả về và xử lý chúng.
Mình sẽ làm một chức năng đơn giản đó là lấy ra danh sách đề mục và đường dẫn của các bài báo trong mục bản tin nóng. Tại màn hình console, ta sẽ thấy các bản tin nóng sẽ được chia ra làm các đầu mục có class là shnews_box:
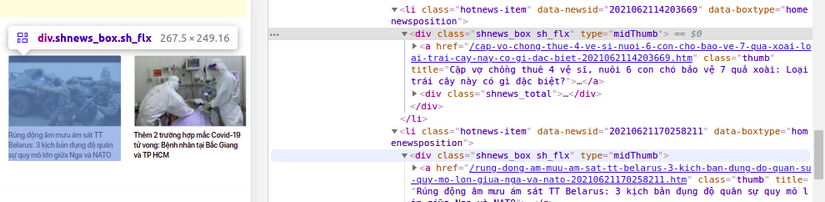
Ta có thể thực hiện như sau:
const getDataOfArticles = async () => { const browser = await launch({ headless: false }); const page = await browser.newPage(); await page.goto("https://soha.vn"); await page.waitForSelector(".hotnews-item"); const hotNews = await page.evaluate(async () => { const articles = document.querySelectorAll(".shnews_box > a");// lấy ra các đối tượng mang class hotnews-item chứa 1 thẻ a const dataAticles = [...articles].map((link) => ({ title: link.getAttribute("title"), url: link.getAttribute("href"),
})); return dataAticles; }); console.log(hotNews); await browser.close(); // đóng trang web
};
Sau khi thực hiện thành công, kết quả trả về cho ta sẽ có dạng một mảng các đối tượng như sau:
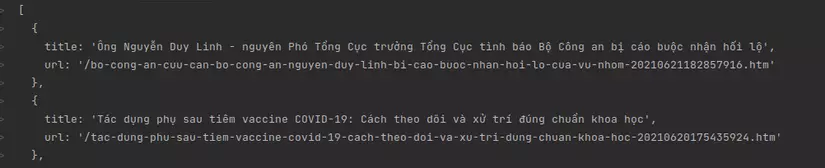
Sau đó, ta có thể tùy ý xử lý các dữ liệu đó theo nhu cầu của bản thân !!
Kết
Trên đây, mình vừa giới thiệu 3 chức năng cơ bản để bạn có thể sử dụng với Puppeteer. Tuy vậy, những chức năng của Puppeteer còn rất nhiều và thú vị. Do bài viết có hạn nên mình xin được tạm dừng ở đây. Chúc các bạn sẽ còn khám phá được thật nhiều điều về Puppeteer và hẹn gặp lại các bạn ở những bài viết sau nhé!