Ở bài trước chúng ta đã tìm hiểu qua các config cơ bản trong postgresSQL, hôm nay mình sẽ hướng dẫn các bạn tạo WAL Replication trong postgresSQL nhé 😁
Trước khi tạo replication cho database của chúng ta, mình sẽ nói qua về WAL(Write-Ahead Logging) cho các bạn hiểu qua nhé.
Các bạn hiểu đơn giản Write-Ahead Logging là một cơ chế quan trọng trong cơ sở dữ liệu nói chung, khi hệ thống thực hiện thao tác như INSERT, UPDATE, DELETE, nó sẽ không ghi trực tiếp vào database, mà sẽ được ghi vào WAL giống như nhật kí, sau đó mới được ghi xuống database, dựa vào cơ chế này mà chúng ta có thể tạo ra các bản replication dựa trên nhật kí WAL này.
Chúng ta có 2 cơ chế để đồng bộ dữ liệu giữa các database server với WAL là : File-Based Log Shipping và Streaming WAL Records.
- File-Based Log Shipping
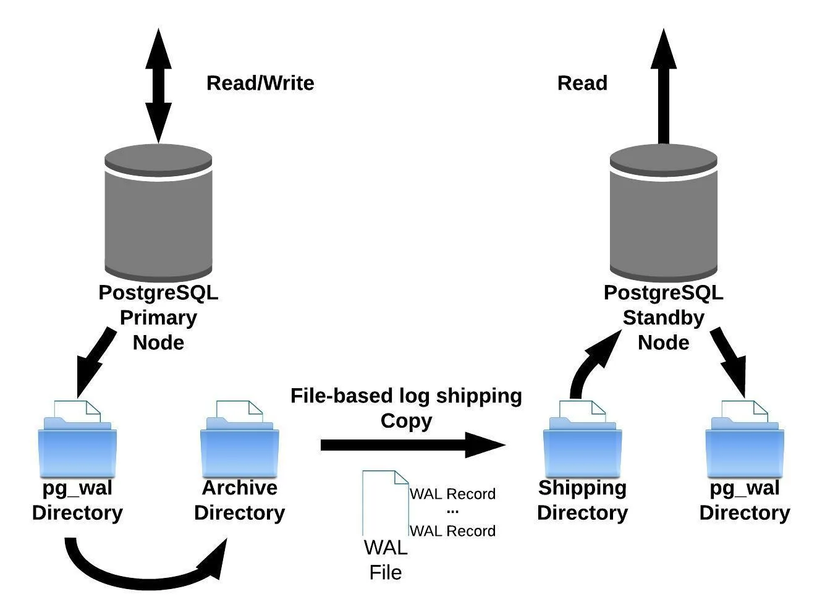
Với cơ chế này, máy master sẽ gửi trực tiếp Wal logs đến máy phụ, từ đó máy phụ có thể đồng bộ hóa dữ liệu với máy chính, nhưng với cơ chế này chỉ khi Wal logs đủ 16MB thì máy chính mới gửi tới máy phụ, điều này có thể dẫn đến không đồng bộ dữ liệu giữa các máy với nhau.
- Streaming WAL Records
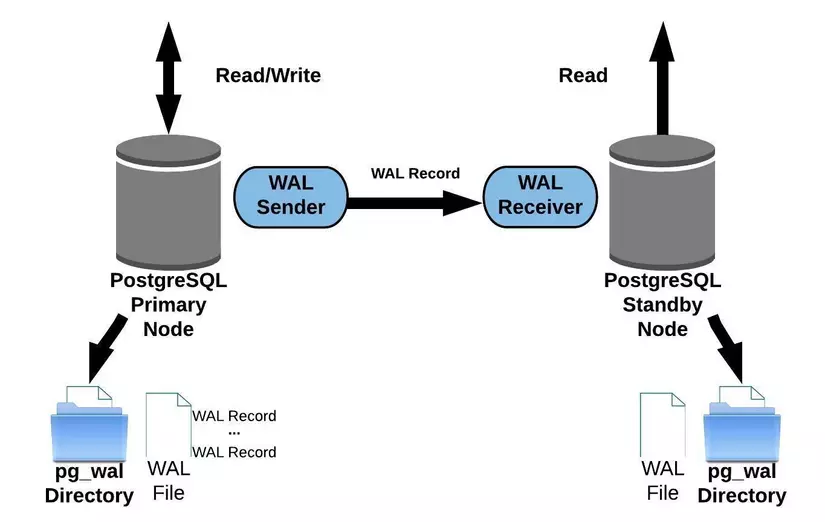
Còn mới cơ chế streaming này, dữ liệu sẽ luôn được đồng bộ hóa một cách liên tục, vì vậy mình sẽ dùng cách này để setup nhé 😁
Vào việc nào !
Giờ anh em sẽ setup lần lượt từng máy master(máy chính) sau đó đến máy standby(máy phụ) nhé.
- Đầu tiên mình sẽ dựng máy master với docker như bài trước đã hướng dẫn các bạn và đặt tên container là
master-node-postgres(bạn nào chưa biết cách cài đặt với docker thì quay lại đọc qua nhé https://viblo.asia/p/cai-dat-he-quan-tri-co-so-du-lieu-postgressql-y37LdAX2Vov)

Sau khi đã dựng xong, anh em vào file postgresql.conf và sửa lại một số cấu hình như sau để phù hợp cho replication nhé.
Bạn nào chưa biết chỉnh sửa như nào có thể quay lại bài trước nhé (https://viblo.asia/p/cac-thong-so-trong-file-config-cua-postgressql-can-luu-y-0gdJznrGJz5)
wal_level = replica
wal_log_hints = on
max_wal_senders = 3
hot_standby = on
- wal_level = replica: như mình đã giải thích ở bài trước, để setup replication thì chúng ta sẽ sử dụng giá trị replica cho wal_level để có thể đáp ứng được yêu cầu nhé.
- wal_log_hints = on: hiểu đơn giản với trạng thái on, replica sẽ yêu cầu pg_rewind( là công cụ giúp các máy trong replication đồng bộ với master) đồng bộ lại nếu máy standby và master không được đồng bộ.
- max_wal_senders = 3: dùng để chỉ định số lượng kết nối đồng thời tối đa được thiết lập giữa máy master và các máy standby.
- hot_standby = on: chỉ định cho các máy standby chỉ có quyền read_only khi kết nối tới master.
Tiếp theo anh em sẽ tạo thêm 1 user tại máy master với quyền replication để cung cấp cho máy standby có thể connect tới máy master với câu query sau:
CREATE USER standby_user REPLICATION LOGIN ENCRYPTED PASSWORD 'standby_pass'
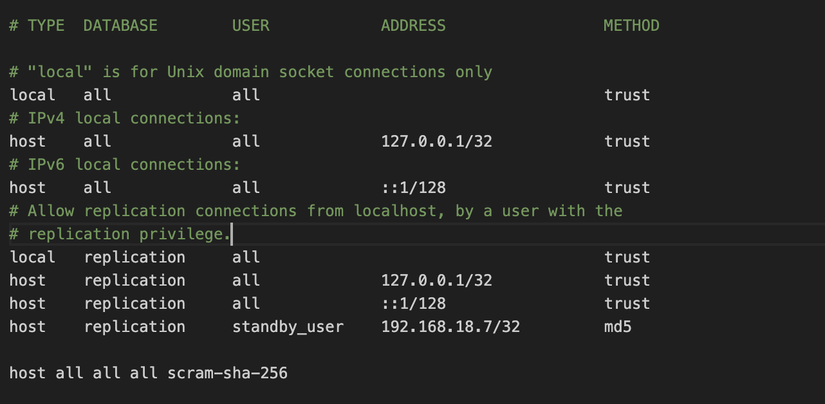
Khi tạo xong chúng ta sẽ làm thêm 1 động tác đó là add thông tin máy standby cùng user vừa tạo vào file config pg_hba.conf như sau nhé:
host replication standby_user 192.168.18.7/32 md5
Anh em kéo xuống cuối sẽ thấy cấu hình như sau nhé:
Tương tự như cách chúng ta tạo máy master, anh em qua 1 con vps khác và dựng 1 con postgres khác với docker như sau:

sau khi đã có con standby node, chúng ta sẽ cấu hình thêm 1 chút cho nó nhé:
Chúng ta sẽ tiến hành đi vào trong container của standby node với câu lệnh:
docker exec -it d3a4d7a810df bash sau đó tiến hành xóa hết file cấu hình mặc định của database standby (tệp cấu hình sẽ được lấy từ máy master qua ở bước tiếp theo) rm -rf /data/postgres
Sau đó dùng pg_basebackup và sử dụng câu lệnh sau:
pg_basebackup -h 192.168.18.204 -p 4432 -U standby_user -X stream -C -S standby_node_1 -v -R -W -D /data/postgres
Sau đó chúng ta restart lại máy standby để có thể thực hiện kết nối nhé.
Quay lại máy master và run câu query sau:
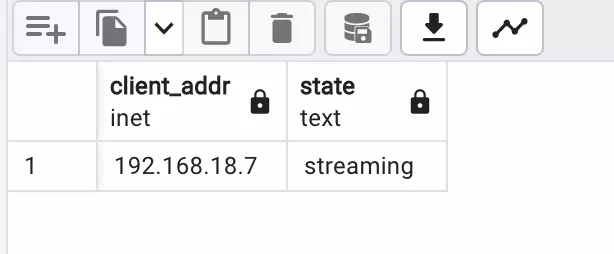
SELECT client_addr, state FROM pg_stat_replication;
Kết quả cho chúng ta thấy thông tin của máy standby:
Vậy là chúng ta đã tạo thành công máy replication rồi nhé.
Giờ tiến hành test thôi nào.
Tạo 1 Database và table users bên máy master và check xem bên máy standby như nào nhé.
CREATE DATABASE users_db;
CREATE TABLE users (first_name VARCHAR(15), last_name VARCHAR(15) , email VARCHAR(40) );
INSERT INTO users
VALUES ('Tran', 'Huy', 'xuanhuy@gmail.com');
Trên là các thao tác cơ bản, các bạn tự test và cảm nhận thành quả nhé.
Cảm ơn các bạn đã đọc và theo dõi, chúng các bạn thành công!