Động lực
Nếu đã là một người học và làm AI thì hẳn chúng ta không còn xa lạ gì với việc train/test model sử dụng GPU. Việc training model sử dụng GPU giúp ta rút ngắn thời gian training đi rất nhiều so với sử dụng CPU. Khi model hoặc dataset trở nên lớn hơn, chỉ sử dụng 1 GPU là không đủ, ví dụ như trong các Large language model hiện nay phải sử dụng rất nhiều GPU khỏe và training trong rất nhiều ngày, thậm chí nhiều tháng. Do đó, ta cần tìm cách để có thể train model cùng một lúc trên nhiều GPU, mục tiêu là thúc đẩy tốc độ training. Pytorch hỗ trợ 2 cách để phân chia model và data trên nhiều GPU sử dụng: nn.DataParallel và nn.DistributedDataParallel. Trong bài viết, ta sẽ tìm hiểu các cách train một model trên nhiều GPU một cách hiệu quả sử dụng Pytorch. Ngoài ra, để hiểu bài viết một cách tốt nhất, các bạn cần có kiến thức về các chủ đề về Multiprocessing, Neural network,...
Giới thiệu nn.DataParallel và nn.DistributedDataParallel
Câu hỏi đặt ra là nên sử dụng nn.DataParallel hay nn.DistributedDataParallel? Để trả lời câu hỏi này ta cần so sánh sự khác nhau giữa DataParallel và DistributedDataParallel 😄 Ta có thể note ra một số ý chính như sau:
DataParallel:
- DataParallel hoạt động trong môi trường single-process, multi-thread (một quá trình duy nhất, nhiều luồng) trên một máy tính duy nhất.
- Ý tưởng chính của DataParallel là sao chép mô hình sang nhiều GPU và mỗi GPU xử lý một phần của dữ liệu đầu vào trong mỗi lượt huấn luyện.
- Tuy nhiên, việc sử dụng multi-thread trên một máy tính có thể gặp phải GIL (Global Interpreter Lock) contention, điều này có thể làm giảm hiệu suất huấn luyện.
- Mô hình được nhân bản giữa các GPU, điều này đòi hỏi cần lưu trữ nhiều bản sao của mô hình trong bộ nhớ, gây tốn bộ nhớ và thời gian sao chép dữ liệu giữa các GPU.
DistributedDataParallel:
- DistributedDataParallel hoạt động trong môi trường multi-process (nhiều quá trình), có thể chạy trên cả single-machine và multi-machine (nhiều máy tính).
- Ý tưởng chính của DistributedDataParallel là sử dụng phương pháp giao tiếp giữa các tiến trình (process) để phân phối quá trình huấn luyện trên nhiều GPU và nhiều máy tính.
- Phương pháp này có thể giảm thiểu tốn kém về hiệu suất do GIL contention và không yêu cầu lưu trữ nhiều bản sao của mô hình. DistributedDataParallel phân chia dữ liệu và mô hình qua nhiều GPU và máy tính thông qua giao tiếp mạng hiệu quả, giúp tăng tốc độ huấn luyện.
Sử dụng DataParallel
Phần này mình sẽ thiết kế một chương trình training giả định để tìm hiểu cách sử dụng DataParallel.
Đầu tiên ta sẽ khai báo các thư viện và tham số cần thiết:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader # Parameters and DataLoaders
input_size = 5
output_size = 2 batch_size = 30
data_size = 100
Device:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
Để đơn giản, ta sẽ tạo một bộ dataset ngẫu nhiên như sau:
class RandomDataset(Dataset): def __init__(self, size, length): self.len = length self.data = torch.randn(length, size) def __getitem__(self, index): return self.data[index] def __len__(self): return self.len rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True)
Mô hình ta sử dụng ở đây là một neural network gồm một layer linear. Bạn cũng có thể sử dụng các model khác cho thực nghiệm của mình. Do cần thực nghiệm xem DataParallel hoạt động như nào, ta cần in ra thông tin kích thước của input tensor và output tensor.
class Model(nn.Module): def __init__(self, input_size, output_size): super(Model, self).__init__() self.fc = nn.Linear(input_size, output_size) def forward(self, input): output = self.fc(input) print("\tIn Model: input size", input.size(), "output size", output.size()) return output
Sau đây là "tiết mục" chính 😄 Đầu tiên, ta sẽ tạo một model instance và kiểm tra xem ta có bao nhiêu GPU. Nếu số GPU lớn hơn 1, ta có thể wrap model sử dụng nn.DataParallel. Sau đó có thể khai báo model sử dụng GPU model.to(device).
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") model = nn.DataParallel(model) model.to(device)
Output sẽ có dạng như sau:
Let's use 2 GPUs! DataParallel( (module): Model( (fc): Linear(in_features=5, out_features=2, bias=True) )
)
Ta sẽ kiểm tra xem kích thức của input tensor và output tensor như thế nào:
for data in rand_loader: input = data.to(device) output = model(input) print("Outside: input size", input.size(), "output_size", output.size())
Vì hiện tại ta có 2 GPU nên kểt quả sẽ như sau:
Let's use 2 GPUs! In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2]) In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
Kích thước input tensor tương ứng với mỗi batch có chiều là [30, 5] nhưng khi vào model lại được chia đều ra là [15, 5] (do có 2 GPU)  Vậy tức là data được chia đều ra làm 2 phần tương ứng với 2 GPU (batch_size / gpus). Nhận thấy việc coding sử dụng DataParallel rất đơn giản, ta chỉ thêm một dòng code là xong
Vậy tức là data được chia đều ra làm 2 phần tương ứng với 2 GPU (batch_size / gpus). Nhận thấy việc coding sử dụng DataParallel rất đơn giản, ta chỉ thêm một dòng code là xong
Model Parallel trên một machine
Trong phần vừa rồi ta đã sử dụng DataParallel để train một model trên nhiều GPU. DataParallel thực hiện sao chép model đến tất cả các GPU, mỗi GPU sử dụng một phần input data khác nhau. Mặc dù phần nào có thể tăng tốc độ training nhưng cách này sẽ không work trong trường hợp model quá lớn để có thể chạy trên 1 GPU 😄 Do đó trong trường hợp này, thay vì sao chép toàn bộ model và đưa lên từng GPU thì ta sẽ "cắt nhỏ" model này ra. Giả sử ta có một model gồm 10 layer, nếu sử dụng DataParallel trên 2 GPU, mỗi GPU sẽ chứa đủ 10 layer của model . Tuy nhiên, nếu sử dụng model parallel trên 2 GPU, mỗi GPU sẽ chỉ chứa 5 layer của model thôi 😄
Nói chung, ý tưởng chính của "model parallel" là chia mô hình thành các phần nhỏ hơn (sub-networks) và đặt chúng lên các thiết bị tính toán khác nhau, chẳng hạn như chia thành các model con trên từng GPU riêng biệt. Sau đó, sử dụng hàm "forward" để di chuyển dữ liệu output trung gian giữa các thiết bị. Vì chỉ có một phần của mô hình hoạt động trên từng thiết bị tính toán cụ thể, một tập hợp các thiết bị có thể cùng nhau xử lý một mô hình lớn hơn. Điều này giúp tận dụng tối đa khả năng tính toán của các thiết bị và giải quyết vấn đề về giới hạn tài nguyên của từng thiết bị.
Ta sẽ bắt đầu bằng một model đơn giản gồm 2 layer linear. Để chạy model trên 2 GPU, ta sẽ đặt mỗi layer linear trên các GPU khác nhau, sau đó di chuyển input và output trung gian để khớp với các GPU tương ứng.
import torch
import torch.nn as nn
import torch.optim as optim class RandomModel(nn.Module): def __init__(self): super(RandomModel, self).__init__() self.net1 = torch.nn.Linear(10, 5).to('cuda:0') self.relu = torch.nn.LeakyReLU() self.net2 = torch.nn.Linear(5, 5).to('cuda:1') def forward(self, x): x = self.relu(self.net1(x.to('cuda:0'))) return self.net2(x.to('cuda:1'))
Ở đây, x đã được chuyển sang cuda:0 trong net1 và cuda:1 trong net2 tương ứng. Cách cài đặt không khác gì nhiều khi sử dụng trên một GPU ngoài việc thêm to(device) 😄 Các hàm backward() và torch.optim sẽ tự động tính toán gradient như ở trên 1 GPU. Một điểm chú ý là ta cần cài đặt label và output trên cùng 1 thiết bị để tính loss cho mô hình.
model = RandomModel()
loss_fn = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad() outputs = model(torch.randn(20, 10))
labels = torch.randn(20, 5).to('cuda:1')
loss_fn(outputs, labels).backward()
optimizer.step()
Ta cũng có thể áp dụng model parallel cho model có sẵn bằng cách kế thừa và ghi đè lên các lớp và hàm forward của model đó. Ví dụ cho đoạn code dưới đây:
from torchvision.models.resnet import ResNet, Bottleneck num_classes = 2 class ModelParallelResNet50(ResNet): def __init__(self, *args, **kwargs): super(ModelParallelResNet50, self).__init__( Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs) self.seq1 = nn.Sequential( self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2 ).to('cuda:0') self.seq2 = nn.Sequential( self.layer3, self.layer4, self.avgpool, ).to('cuda:1') self.fc.to('cuda:1') def forward(self, x): x = self.seq2(self.seq1(x).to('cuda:1')) return self.fc(x.view(x.size(0), -1))
Trong đoạn code trên ta import model Resnet từ torchvision.models.resnet. Để có thể chạy phân tách model này và đưa vào 2 GPU ta sẽ tạo một class mới tên ModelParallelResNet50 kế thừa Resnet. Sau đó thay đổi thuộc tính của seq1, seq2 và fc chuyển tới thiết bị khác nhau. Tiếp theo, override hàm forward để ghép 2 thành phần của mạng lại với nhau bằng cách chuyển output trung gian tới các thiết bị tương ứng.
Cách trên có thể làm cho việc train model chậm hơn so với việc chỉ chạy trên một GPU. Nguyên nhân là tại một thời điểm chỉ một trong 2 GPU hoạt động và mất thời gian khi các output trung gian liên tục được copy từ cuda:0 sang cuda:1. Từ kết quả thực nghiệm tại model_parallel_tutorial cho thấy rằng việc sử dụng Model Parallel chậm hơn 7% so với chạy trên 1 GPU. Đây cũng là chi phí copy các tensor giữa các GPU.
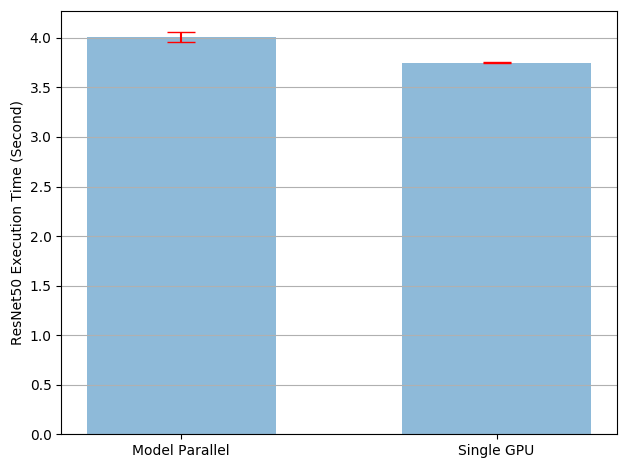
Một cách để giải quyết vấn đề một thằng GPU làm và thằng còn lại ngồi chơi 😄 là ta sẽ tách nhỏ batch dữ liệu sao cho khi một phần dữ liệu đến sub-network thứ 2, phần tách còn lại sẽ được đưa vào mạng con thứ nhất. Bằng cách này ta sẽ chạy đồng thời được trên cả 2 GPU.
Giả sử ban đầu ta chạy với batchsize là 100, ta sẽ chia batch thành các phần chứa 20 ảnh (batch của batch 😄). Cài đặt sẽ như sau:
class PipelineParallelResNet50(ModelParallelResNet50): def __init__(self, split_size=20, *args, **kwargs): super(PipelineParallelResNet50, self).__init__(*args, **kwargs) self.split_size = split_size def forward(self, x): splits = iter(x.split(self.split_size, dim=0)) s_next = next(splits) s_prev = self.seq1(s_next).to('cuda:1') ret = [] for s_next in splits: # A. ``s_prev`` runs on ``cuda:1`` s_prev = self.seq2(s_prev) ret.append(self.fc(s_prev.view(s_prev.size(0), -1))) # B. ``s_next`` runs on ``cuda:0``, which can run concurrently with A s_prev = self.seq1(s_next).to('cuda:1') s_prev = self.seq2(s_prev) ret.append(self.fc(s_prev.view(s_prev.size(0), -1))) return torch.cat(ret)
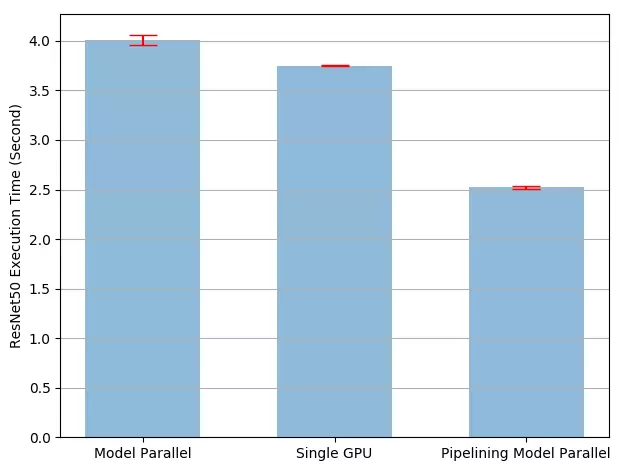
Tốc độ đã trở nên nhanh hơn rất nhiều so với trước. Câu hỏi đặt ra là sử dụng split_size với giá trị bao nhiêu là tối ưu nhất. Về mặt trực quan, việc sử dụng split_size nhỏ dẫn đến khởi chạy nhiều nhân CUDA nhỏ, trong khi sử dụng split_size lớn dẫn đến thời gian "nhàn rỗi" tương đối dài trong lần phân tách đầu tiên và cuối cùng. Ta có kết quả thực nghiệm với các giá trị split_size khác nhau như sau:
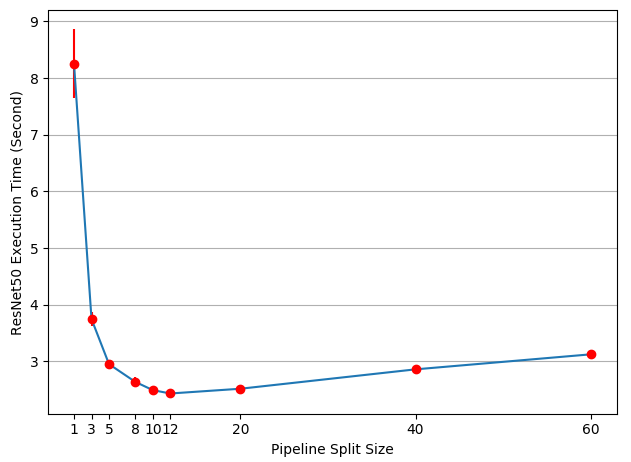
Tốc độ thực thi lớn nhất khi split_size có giá trị 12. Vì giá trị này còn tùy thuộc vào mô hình và data khác nhau nên không có một cách tối ưu chung cho mọi trường hợp.
Sử dụng DistributedDataParallel
Trước khi bắt đầu sử dụng DistributedDataParallel ta cần hiểu một số thuật ngữ:
- "Node": Trong kiến trúc phân tán, "node" là một hệ thống đơn lẻ có khả năng tính toán và chứa nhiều GPU. Đây có thể là một máy tính hoặc một máy tính hàng loạt có khả năng tính toán song song nhờ nhiều GPU.
- "Global rank": Đây là một số định danh duy nhất cho mỗi "node" trong kiến trúc phân tán. Nó giúp xác định mỗi "node" riêng biệt và duy nhất trong hệ thống.
- "Local rank": Đây cũng là một số định danh duy nhất, nhưng nó xác định các tiến trình (processes) trong từng "node" riêng lẻ.
- "World": "World" là tập hợp của tất cả các thực thể trong kiến trúc phân tán, bao gồm cả "nodes" và các tiến trình trong từng "node". Nó là không gian làm việc toàn cầu cho toàn bộ hệ thống phân tán.
- "world_size": Đây là một số xác định kích thước của "world", tức là tổng số tiến trình trong hệ thống. Nó được tính bằng cách nhân số lượng "nodes" với số lượng GPU trong mỗi "node". Việc hiểu "world_size" là quan trọng để quản lý số lượng tiến trình và tối ưu hóa phân phối công việc trong hệ thống.
- "Process group": Trong việc huấn luyện hoặc kiểm tra mô hình trên nhiều GPU, "process group" là một tập hợp các tiến trình (processes) tương ứng với số lượng GPU được sử dụng. Mỗi tiến trình trong "process group" đại diện cho một GPU và các tiến trình này cùng hoạt động để thực hiện tính toán song song trong quá trình huấn luyện mô hình.
DistributedDataParallel (DDP) là một phương pháp thực hiện xử lý song song dựa trên mô-đun (module-level) trong PyTorch và có thể chạy trên nhiều máy tính khác nhau. Nó cho phép huấn luyện mô hình trên nhiều GPU và nhiều máy tính, giúp tăng tốc quá trình huấn luyện. Các ứng dụng sử dụng DDP cần tạo ra nhiều tiến trình (processes) và tạo một phiên bản DDP duy nhất cho mỗi tiến trình. Điều này đảm bảo việc xử lý song song và tối ưu hiệu suất của việc đồng bộ gradient và bộ đệm giữa các tiến trình. Cách sử dụng DDP được khuyến nghị là tạo ra một tiến trình cho mỗi bản sao của mô hình (model replica), trong đó mỗi bản sao của mô hình có thể trải dài qua nhiều thiết bị tính toán.
Để tạo một DDP module, ta sẽ phải setup các process group như sau:
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp from torch.nn.parallel import DistributedDataParallel as DDP def setup(rank, world_size): os.environ['MASTER_ADDR'] = 'localhost' os.environ['MASTER_PORT'] = '12355' # initialize the process group # giao thức "gloo" thay thế bằng "nccl" nếu sử dụng giao thức NVIDIA's NCCL dist.init_process_group("gloo", rank=rank, world_size=world_size) def cleanup(): dist.destroy_process_group()
Tiếp theo ta sẽ tạo dataloader sử dụng torch.utils.data.distributed.DistributedSampler. "DistributedSampler" là một sampler trong PyTorch được sử dụng trong việc phân tán dữ liệu khi huấn luyện trên nhiều GPU hoặc nhiều máy tính. Khi sử dụng "DistributedSampler", toàn bộ chỉ số (indices) của tập dữ liệu (dataset) sẽ được chia thành world_size phần. Sau khi tách các chỉ số thành các phần, DistributedSampler sẽ phân phối chúng một cách đồng đều cho các DataLoader trong từng tiến trình (process) mà không có sự trùng lặp. Điều này đảm bảo rằng mỗi tiến trình sẽ nhận được một tập hợp các chỉ số độc lập, không trùng lặp với các tiến trình khác.
from torch.utils.data.distributed import DistributedSampler
def prepare(rank, world_size, batch_size=32, pin_memory=False, num_workers=0): dataset = Your_Dataset() sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank, shuffle=False, drop_last=False) dataloader = DataLoader(dataset, batch_size=batch_size, pin_memory=pin_memory, num_workers=num_workers, drop_last=False, shuffle=False, sampler=sampler) return dataloader
Giả sử ta có 3 GPU và độ dài của dataset là 10. DistributedSampler sẽ đảm bảo phân chia các chỉ số (indices) một cách đồng đều. Trong trường hợp này, số lượng chỉ số (10) không chia hết cho số lượng tiến trình (3), nhưng DistributedSampler vẫn đảm bảo các chỉ số được phân chia một cách cân đối và không bị lệch.
Nếu chúng ta đặt drop_last=False khi định nghĩa DistributedSampler, nó sẽ tự động thêm phần pad. Điều này xảy ra khi số lượng chỉ số không chia hết cho số lượng tiến trình. Ví dụ: Nếu rank=1, DistributedSampler sẽ chia chỉ số [0,1,2,3,4,5,6,7,8,9] thành [0,3,6,9] và tự động thêm phần pad (giá trị 0) để đảm bảo có đủ số lượng chỉ số cho mỗi tiến trình. Ngược lại, nếu chúng ta đặt drop_last=True, nó sẽ cắt bỏ các phần tử dư thừa. Ví dụ: Nếu drop_last=True và rank=1, DistributedSampler sẽ chia chỉ số [0,1,2,3,4,5,6,7,8,9] thành [0,3,6] và cắt bỏ phần tử cuối (9) để đảm bảo số lượng chỉ số chia hết cho số lượng tiến trình.
Tiếp theo ta sẽ wrap model sử dụng DistributedDataParallel.
class RandomModel(nn.Module): def __init__(self): super(RandomModel, self).__init__() self.net1 = nn.Linear(10, 10) self.relu = nn.ReLU() self.net2 = nn.Linear(10, 5) def forward(self, x): return self.net2(self.relu(self.net1(x))) def demo_basic(rank, world_size): print(f"Running basic DDP example on rank {rank}.") setup(rank, world_size) # create model and move it to GPU with id rank model = RandomModel().to(rank) ddp_model = DDP(model, device_ids=[rank]) loss_fn = nn.MSELoss() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001) optimizer.zero_grad() outputs = ddp_model(torch.randn(20, 10)) labels = torch.randn(20, 5).to(rank) loss_fn(outputs, labels).backward() optimizer.step() cleanup()
Khi muốn truy cập vào các thuộc tính tùy chỉnh của mô hình đã được wrap bằng DistributedDataParallel (DDP), ta sẽ cần phải tham chiếu đến model.module. Điều này có nghĩa là thực tế mô hình được lưu trữ như một thuộc tính "module" của mô hình DDP. Do đó, khi muốn truy cập các thuộc tính xxx mà không phải thuộc tính built-in hoặc các hàm, chúng ta phải truy cập chúng qua model.module.xxx.
Do đó, nếu muốn load mô hình DDP saved model sang non-DDP model, ta cần phải loại bỏ tiền tố module một cách thủ công như sau:
model_dict = OrderedDict()
pattern = re.compile('module.')
for k,v in state_dict.items(): if re.search("module", k): model_dict[re.sub(pattern, '', k)] = v else: model_dict = state_dict
model.load_state_dict(model_dict)
Tiếp theo ta sẽ gọi hàm spawn để chạy các tiến trình song song.
def run_demo(demo_fn, world_size): mp.spawn(demo_fn, args=(world_size,), nprocs=world_size, join=True)
Trong hàm "demo_fn" được sử dụng để bắt đầu quá trình huấn luyện phân tán, tham số đầu tiên là "rank". Tham số này đại diện cho số thứ tự của tiến trình hiện tại trong "process group". Khi sử dụng hàm mp.spawn trong PyTorch để bắt đầu huấn luyện phân tán, "rank" sẽ được tự động chuyển cho mỗi tiến trình một cách tự động, ta không cần phải truyền nó một cách rõ ràng. Mặc định, "rank=0" được coi là nút chủ (master node). Đây thường là tiến trình đầu tiên trong "process group", có trách nhiệm điều phối và quản lý các tiến trình khác trong quá trình huấn luyện phân tán. Giá trị của "rank" dao động từ 0 đến K-1, trong đó K là tổng số tiến trình (số GPU) trong "process group". Ví dụ: Nếu có 2 GPU (K=2), thì rank của các tiến trình sẽ có giá trị là 0 và 1. "rank=0" sẽ là nút chủ (master node), và "rank=1" là tiến trình thứ hai trong quá trình huấn luyện phân tán.
Ta cũng có thể đơn giản hóa DDP code bằng cách sử dụng Pytorch Elastic. Giả sử ta có một file elastic_ddp.py như sau:
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim from torch.nn.parallel import DistributedDataParallel as DDP class ToyModel(nn.Module): def __init__(self): super(ToyModel, self).__init__() self.net1 = nn.Linear(10, 10) self.relu = nn.ReLU() self.net2 = nn.Linear(10, 5) def forward(self, x): return self.net2(self.relu(self.net1(x))) def demo_basic(): dist.init_process_group("nccl") rank = dist.get_rank() print(f"Start running basic DDP example on rank {rank}.") # create model and move it to GPU with id rank device_id = rank % torch.cuda.device_count() model = ToyModel().to(device_id) ddp_model = DDP(model, device_ids=[device_id]) loss_fn = nn.MSELoss() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001) optimizer.zero_grad() outputs = ddp_model(torch.randn(20, 10)) labels = torch.randn(20, 5).to(device_id) loss_fn(outputs, labels).backward() optimizer.step() if __name__ == "__main__": demo_basic()
Bằng một câu lệnh torch run, ta có thể chạy trên tất cả node để khở tạo DDP job như sau:
torchrun --nnodes=2 --nproc_per_node=4 --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=$MASTER_ADDR:29400 elastic_ddp.py
Với câu lệnh trên,ta chạy DDP script trên hai host và mỗi host chạy 4 process, nói một cách khác là ta đang chạy trên 8 GPU. Lưu ý rằng $MASTER_ADDR phải giống nhau trên tất cả các node.
Kết luận
Vậy là ta đã đi qua một số cách để có thể training model trên nhiều GPU. Khi mà model ngày càng lớn thì việc nắm được cách training trên GPU sẽ càng quan trọng 😄 Các cách được trình bày ở trên là những ý tưởng cơ bản nhất của Distributed training, bạn hoàn toàn có thể custom lại cho mô hình và dữ liệu của mình để đạt được kết quả tối ưu nhất.
Tham khảo
[1] https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
[2] https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html