Các thành phần và chức năng của ELK Stack
1. Các thành phần của ELK Stack
E = Elasticsearch
Elasticsearch là một hệ thống tìm kiếm và phân tích văn bản đầy đủ được xây dựng trên Apache Lucene, cung cấp khả năng tìm kiếm và phân tích gần như theo thời gian thực cho tất cả các loại dữ liệu.
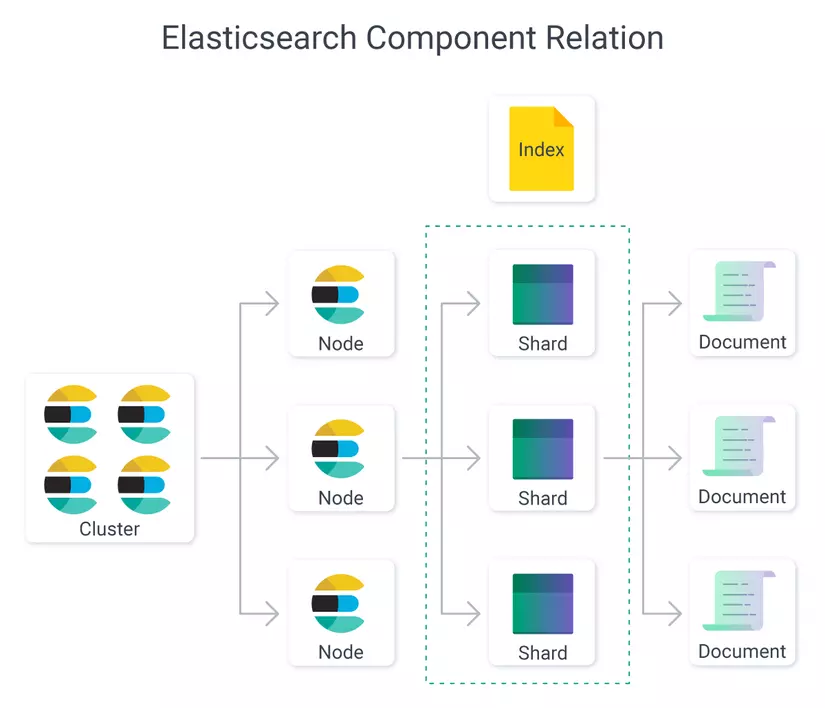
Dưới đây là các điểm chính về Elasticsearch:
Dữ liệu vào (Data in: documents and indices): • Elasticsearch là một kho lưu trữ tài liệu phân tán, lưu trữ các cấu trúc dữ liệu dưới dạng tài liệu JSON. • Mỗi tài liệu được lập chỉ mục và có thể tìm kiếm đầy đủ trong thời gian gần thực.
Thông tin ra (Information out: search and analyze):
• Elasticsearch cung cấp API REST (được sử dụng bởi các thành phần UI và có thể được gọi một cách trực tiếp để cấu hình và truy cập các tính năng của Elasticsearch) để quản lý cụm và lập chỉ mục, và tìm kiếm dữ liệu. • API REST hỗ trợ truy vấn có cấu trúc, truy vấn toàn văn bản và truy vấn kết hợp cả hai. • Elasticsearch sử dụng thư viện công cụ tìm kiếm Apache Lucene để có khả năng tìm kiếm mạnh mẽ.
Tìm kiếm dữ liệu (Search of data):
• Quản trị viên có thể truy cập tất cả các khả năng tìm kiếm bằng cách sử dụng Query DSL. • Quản trị viên cũng có thể xây dựng các truy vấn kiểu SQL để tìm kiếm và tổng hợp dữ liệu nguyên bản bên trong Elasticsearch, và trình điều khiển JDBC và ODBC cho phép một loạt các các ứng dụng của bên thứ ba để tương tác với Elasticsearch thông qua SQL.
Khả năng mở rộng và khả năng phục hồi (Scalability and Resilience): clusters, nodes, and shards:
• Quản trị viên có thể thêm máy chủ (nodes) vào một cụm (cluster) để tăng dung lượng và Elasticsearch tự động phân phối dữ liệu và tải truy vấn của quản trị viên trên tất cả các nút (node) đã có sẵn. Elasticsearch biết cách cân bằng các cụm đa nút để cung cấp tính quy mô và sẵn sàng cao.
Hệ điều hành và JVM hỗ trợ:
• Elasticsearch 8.12.x hỗ trợ nhiều hệ điều hành như RHEL, CentOS, Ubuntu, Windows, Debian, và nhiều JVM như Oracle/OpenJDK/Temurin.
Tóm lại, Elasticsearch là một giải pháp mạnh mẽ cho việc tìm kiếm, phân tích và lưu trữ dữ liệu, đặc biệt hiệu quả trong việc xử lý lượng dữ liệu lớn và đáp ứng theo thời gian thực.
L = Logstash
Logstash là một công cụ tải nhập dữ liệu nguồn mở cho phép người dùng thu thập dữ liệu từ các nguồn khác nhau, chuyển đổi dữ liệu và gửi dữ liệu tới điểm đích họ muốn. Với các bộ lọc được tạo sẵn và hỗ trợ hơn 200 phần bổ trợ, Logstash cho phép người dùng dễ dàng tải nhập dữ liệu đến từ bất kỳ nguồn dữ liệu hay thuộc loại dữ liệu nào.
Quy trình xử lý của Logstash bao gồm ba giai đoạn chính: Đầu vào, Bộ lọc và Đầu ra.
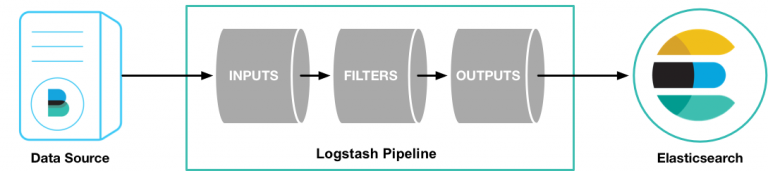 Đầu vào (Inputs): Đầu vào tạo ra các sự kiện, bộ lọc sửa đổi chúng và đầu ra gửi chúng đi. Đầu vào và đầu ra hỗ trợ codecs cho phép quản trị viên mã hóa hoặc giải mã dữ liệu khi nó đi vào hoặc ra khỏi đường ống mà không cần phải sử dụng riêng bộ lọc.
Đầu vào (Inputs): Đầu vào tạo ra các sự kiện, bộ lọc sửa đổi chúng và đầu ra gửi chúng đi. Đầu vào và đầu ra hỗ trợ codecs cho phép quản trị viên mã hóa hoặc giải mã dữ liệu khi nó đi vào hoặc ra khỏi đường ống mà không cần phải sử dụng riêng bộ lọc.
Đầu vào (Inputs):
- Fle: Đọc dữ liệu từ một file trên hệ thống file.
- Syslog: Hoạt động trên cổng 514 cho syslog messages và phân tích cú pháp theo định dạng RFC3164.
- Redis: Đọc từ máy chủ Redis, sử dụng cả kênh Redis và danh sách Redis.
- Beats: Xử lý các sự kiện do Beats gửi.
Bộ lọc (Filters): Là thiết bị xử lý trung gian trong đường ống (pipeline) Logstash.
-
Grok: Phân tích cú pháp và cấu trúc văn bản.
-
Mutate: Thực hiện các phép biến đổi trên trường sự kiện.
-
Drop: Bỏ hoàn toàn một sự kiện.
-
Clone: Tạo một bản sao của một sự kiện.
-
Geoip: Thêm thông tin về vị trí địa lý của địa chỉ IP.
 Đầu ra (Outputs): Là giai đoạn cuối cùng của đường ống Logstash. Một sự kiện có thể đi qua nhiều đầu ra, nhưng sau khi tất cả các quá trình đầu ra hoàn tất, sự kiện sẽ được xử lý hoàn chỉnh:
Đầu ra (Outputs): Là giai đoạn cuối cùng của đường ống Logstash. Một sự kiện có thể đi qua nhiều đầu ra, nhưng sau khi tất cả các quá trình đầu ra hoàn tất, sự kiện sẽ được xử lý hoàn chỉnh: -
Elasticsearch
-
File: Ghi dữ liệu sự kiện vào tệp trên đĩa.
-
Graphite: Gửi dữ liệu sự kiện đến Graphite, công cụ lưu trữ và vẽ đồ thị số liệu.
-
StatSD: Dịch vụ lắng nghe số liệu thống kê, được gửi qua UPD và gửi tổng hợp đến các dịch vụ phụ trợ.
Mô hình vận hành:
- Đường ống xử lý sự kiện Logstash có các giai đoạn Đầu vào, Bộ lọc và Đầu ra.
- Mỗi đầu vào được chạy trong một luồng riêng.
- Sự kiện được đưa vào hàng đợi trung tâm để được xử lý.
- Các worker thread lấy sự kiện từ hàng đợi, chạy qua các bộ lọc và gửi đến các đầu ra.
- Kích thước của lô và số lượng worker thread có thể được cấu hình CS trong Logstash:
- Elastic Common Schema (ECS) là một đặc tả mã nguồn mở, chuẩn hóa dữ liệu sự kiện trong Elasticsearch. ECS xác định một tập hợp các trường phổ biến được sử dụng để lưu trữ dữ liệu sự kiện,
- Với ECS, người dùng có thể chuẩn hóa dữ liệu sự kiện để phân tích, trực quan hóa và tương quan tốt hơn với dữ liệu được thể hiện trong các sự kiện của họ.
- Tất cả các plugin trong Logstash 8 chạy ở chế độ tương thích ECS v8 theo mặc định. Người dùng có thể chọn tham gia hoặc không tham gia ECS tùy thuộc vào yêu cầu cụ thể.
Tóm lại, Logstash hoạt động thông qua quy trình Đầu vào, Bộ lọc và Đầu ra, cung cấp khả năng xử lý linh hoạt cho việc thu thập, xử lý và chuyển tiếp dữ liệu sự kiện.
K = Kibana
Kibana là một công cụ hiển thị trực quan và khám phá dữ liệu được sử dụng trong những trường hợp phân tích nhật ký và chuỗi thời gian, giám sát ứng dụng và thông tin kinh doanh. Công cụ này cung cấp những tính năng mạnh mẽ, dễ sử dụng như biểu đồ tần suất, biểu đồ đường, biểu đồ tròn, biểu đồ nhiệt và hỗ trợ không gian địa lý được tích hợp sẵn.
Kibana cung cấp nhiều tính năng tương tác và trực quan, bao gồm:
- Tìm Kiếm và Quan Sát:
- Kibana cho phép tìm kiếm, quan sát, và bảo vệ dữ liệu một cách hiệu quả.
- Tìm kiếm Enterprise cung cấp trải nghiệm tìm kiếm mạnh mẽ cho ứng dụng, môi trường làm việc, hay trang web.
- Khả Năng Quan Sát Elastic:
- Được thiết kế để theo dõi và áp dụng phân tích thời gian thực đến các sự kiện trên mọi môi trường.
- Phân tích sự kiện nhật ký, theo dõi hiệu suất máy chủ, và kiểm tra tính khả dụng của dịch vụ.
- Phân Tích Dữ Liệu:
- Sử dụng Kibana Analytics để tìm kiếm, khám phá, và tạo biểu đồ dữ liệu một cách linh hoạt.
- Thêm dữ liệu từ nhiều nguồn thông qua tích hợp hoặc tải tệp lên.
- Trực Quan Hóa Dữ Liệu:
- Tạo biểu đồ, bảng, chỉ số và nhiều loại trực quan hóa dữ liệu khác.
- Sử dụng Canvas để tạo trực quan hóa động và sáng tạo từ dữ liệu Elasticsearch.
Chúc mừng năm mới đến toàn thể dân IT! Mong rằng năm mới sẽ đem lại cơ hội mới, thành công và niềm vui trong công việc. Hãy tiếp tục nỗ lực và sáng tạo để đạt được những mục tiêu mới. Chúc mọi người một năm mới tràn đầy hạnh phúc và thành công!``