
1. Steganography là gì ?
Nếu là một fan trinh thám hay các văn hóa phẩm về điệp viên, chắc hẳn bạn không còn lạ gì với việc truyền tin bằng những đoạn tin quảng cáo tưởng như rất bình thường trên báo, với mật mã "hình nhân nhảy múa" trong Sherlock Holmes, hay gần gũi nhất là hồi nhỏ chúng ta thử nghiệm mực vô hình: dùng nước chanh viết lên giấy, đợi khô rồi hơ nóng, thông điệp viết bằng nước chanh sẽ dần hiện ra.
Những ví dụ trên đều là một hình thức của Steganography. Nói đơn giản là chúng ta sẽ tạo ra một loại thông điệp hoặc mật mã mà người ngoài nhìn vào, không những không giải được mà còn không nhận ra được rằng nó có ẩn chứa một thông điệp bí mật - "The art of disguise is knowing how to hide in plain sight"
Theo định nghĩa từ Wikipedia:
Steganography (Kỹ thuật giấu tin hay kỹ thuật giấu thư, kỹ thuật ẩn mã) là nghệ thuật và khoa học về việc viết và chuyển tải các thông điệp một cách bí mật, sao cho ngoại trừ người gửi và người nhận, không ai biết đến sự tồn tại của thông điệp, là một dạng của bảo mật bằng cách che giấu. Từ steganography có gốc Hy lạp có nghĩa là "giấu tin" kết hợp từ hai từ steganos (στεγανός) nghĩa là "ẩn nấp để bảo vệ" và graphein (γράφειν) nghĩa là "viết".
Trong không gian số, steganography tồn tại dưới dạng file, lời nhắn, hình ảnh hoặc đoạn video được ẩn giấu trong một file/ lời nhắn/ hình ảnh hoặc video khác. Các file media là lớp vỏ bọc (cover) lý tưởng để giấu tin vì chúng có kích thước lớn. Ví dụ người gửi có thể thay đổi thành phần màu sắc của một số pixel trên tấm ảnh tương ứng với các ký tự trong bảng chữ cái, sự thay đổi này rất nhỏ đến mức không thể nhận ra bằng mắt thường. Trong hai hình phía dưới, hình bên trái là stego image - hình ảnh đã được cài "thông điệp" bí mật bằng cách xử lý color component của từng pixel. Hình bên phải là "thông điệp" sau khi được extract ra.


Như vậy chắc các bạn cũng đã nhận ra ưu điểm của steganography so với cryptography (mã hóa thông tin), đó là nó sẽ không thu hút sự chú ý. Một mật mã dù mạnh đến đâu, cũng vẫn sẽ bị để ý đến hoặc tìm cách phá giải, thậm chí bị coi là phạm pháp ở một số quốc gia. Đặt trong bối cảnh ngày nay, thời đại mà thông tin trao đổi qua lại của chúng ta trở thành mỏ vàng cho các công ty quảng cáo, thời đại mà tự do ngôn luận ở một số quốc gia lại là điều xa xỉ, thời đại mà "Big Brother is watching you" không phải chỉ dừng lại ở một viễn cảnh, thì steganography lại càng trở nên đáng được quan tâm hơn bao giờ hết.
2. Text Steganography
Như đã nói ở trên, có rất nhiều phương tiện có thể dùng để làm vật trung gian mang tin: file, audio, hình ảnh, video, vv. Nhưng trong cuộc sống hàng ngày thì văn bản (text) chính là phương tiện truyền tin phổ biến nhất. Tuy nhiên so với các file media thì text có mức độ mã hóa thông tin cao hơn dẫn đến ít thông tin dư thừa (redundant information) hơn, làm cho việc giấu thông tin trong đó khó hơn rất nhiều. Trong phạm vi bài viết này, mình sẽ tìm hiểu về bài toán steganography với định dạng text cũng như một số kỹ thuật giấu tin (generation-based) trong văn bản được phát triển trong thời gian gần đây.
2.1. Đặt vấn đề
Giả sử A muốn gửi cho B một tin nhắn chứa thông tin nhạy cảm qua một kênh được giám sát bởi C. Kênh này có thể được sử dụng chung để liên lạc bởi nhiều bên khác nhau. Thông tin được truyền đi trong kênh là văn bản chứa ngôn ngữ tự nhiên (natural language). A vừa phải đảm bảo chỉ có mình B hiểu được nội dung tin nhắn, vừa phải tránh gửi những nội dung "mất tự nhiên" có thể khiến C nghi ngờ. Vậy A và B có thể thực hiện các bước như sau:
- A mã hóa nội dung tin nhắn thành một đoạn văn bản mã hóa (ciphertext), key để mã hóa được nắm giữ bởi cả A và B
- A giấu đoạn ciphertext (thường là một chuỗi các bit) vào trong một tin nhắn dưới dạng ngôn ngữ tự nhiên bình thường (stegotext)
- A gửi đoạn stegotext qua kênh liên lạc do C giám sát
- B nhận được và trích xuất ra ciphertext
- B giải mã đoạn ciphertext với key chung để lấy được thông tin mật.
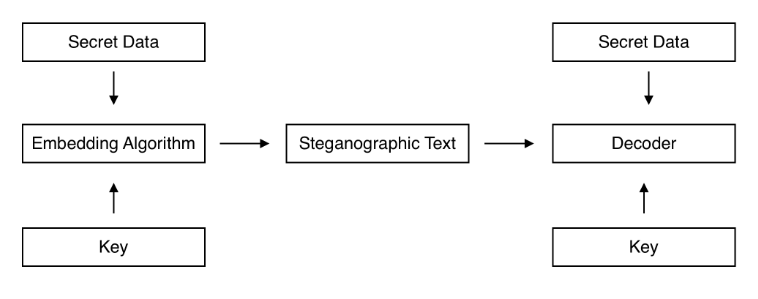
Mô hình tổng quát của bài toán giấu tin được thể hiện như sau:
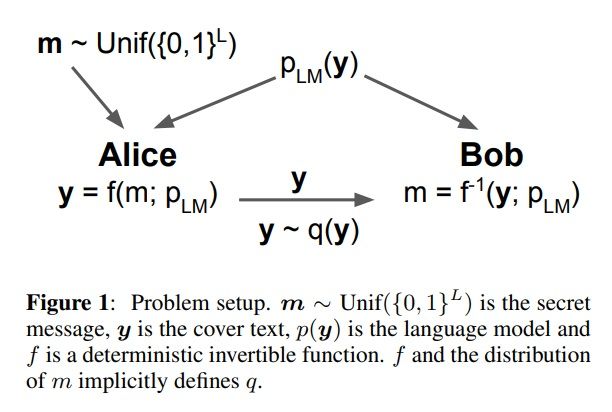
Trong đó:
- là tin nhắn bí mật (thường được mã hóa thành một một chuỗi các bit tuân theo phân phối đều (uniform distribution)
- là đoạn cover text - stegotext
- là phân phối xác suất của y
- là một hàm khả nghịch dùng để biến đổi m thành y
- Cả A và B đều sử dụng cùng một mô hình ngôn ngữ trong quá trình encode, giấu tin và decode
Như vậy ta có thể thấy quá trình này liên quan đến hai công đoạn chính: (1) mã hóa đoạn tin cần chuyển đi và (2) giấu nó vào trong một đoạn văn bản bình thường.
Vậy để hệ thống steganography hoạt động hiệu quả thì hai công đoạn này cần phải đạt những mục tiêu nào? Hay nói cách khác, có những metrics nào để đánh giá tính hiệu quả của của một phương pháp giấu tin?
2.2. Evaluation metrics
2.2.1. Perplexity
Perplexity là thước đo đánh giá chất lượng của một mô hình ngôn ngữ (language model). Giả sử khi chúng ta xây dựng một mô hình ngôn ngữ từ một tập mẫu câu, ta sẽ giữ lại một tập câu để test (held-out):
Với mỗi câu trong tập test, ta có thể tính được xác suất của nó bằng mô hình ngôn ngữ vừa được xây dựng. Như vậy chất lượng của mô hình có thể được tính bằng xác suất của tất cả các câu trong test set:
Giá trị này càng cao thì có nghĩa là mô hình ngôn ngữ hoạt động càng tốt: mô hình ít bị bất ngờ đối với những câu chưa từng xuất hiện.
Lấy log cơ số 2 của giá trị này chia trung bình cho số từ vựng có trong bộ test (với là số từ trong câu ) ta có:
Ta có Perplexity được tính bằng công thức sau:
Vậy: Perplexity càng thấp tương ứng với chất lượng của language model càng cao.
Metric này dùng để đánh giá hệ thống giấu tin xây dựng trên mạng LSTM dựa trên tập dataset có sẵn. Mục đích của nó là đánh giá xem đoạn stegotext sinh ra có "tự nhiên", có đúng ngữ pháp hay không, vv. Còn đối với những cách tiếp cận mới hơn dùng mô hình ngôn ngữ pretrained (ví dụ GPT-2), đồng thời để đánh giá xem hệ thống giấu tin có "đánh lừa" được những phần mềm được tạo ra để phát hiện điều bất thường (thường dựa trên phân phối xác suất của đoạn văn bản được sinh ra) thì chúng ta cần sử dụng metrics thứ 2 dưới đây.
2.2.2. KL Divergence
Một metrics nữa thường dùng để đo lường tính hiệu quả của mô hình steganography là KL Divergence. Cụ thể là với là phân phối xác suất thực tế của ngôn ngữ tự nhiên, là phân phối xác suất của stegotext được tạo ra bởi thuật toán. Tuy nhiên vì không thể tính toán được nên người ta sẽ tính với là phân phối của mô hình ngôn ngữ được sử dụng khi generate stegotext.
có nghĩa là hệ thống là an toàn tuyệt đối vì người/ công cụ giám sát không thể phân biệt được sự khác nhau giữa văn bản ngôn ngữ tự nhiên với stegotext.
Như vậy mục tiêu về mặt an ninh của mô hình steganography là đảm bảo nhỏ, tức là phân phối của càng gần với phân phối càng tốt.
2.2.3. Bits/word
Để đánh giá tính hiệu quả về mặt nén dữ liệu của mô hình, người ta sử dụng tỷ số bits/word. Tỷ lệ này được tính bằng số bit của message đầu vào sau khi được mã hóa (ciphertext) chia cho số từ ở đầu ra (stegotext). Tức là trong một đoạn text đầu ra có thể chứa được nhiều hay ít thông tin cần truyền đi.
3. Encoding techniques
Trong phần này mình sẽ giới thiệu một số phương pháp encode - giấu tin thường được sử dụng
3.1. Bins
(được giới thiệu trong paper Generating Steganographic Text with LSTMs)
B1: Mã hóa thông tin cần giấu thành một chuỗi bit (cách đơn giản nhất có thể dùng ASCII coding map)
B2: Chia chuỗi thành các bit block nhỏ hơn với độ dài , như vậy sẽ có tổng cộng bit block. Ví dụ nếu = 100001 và =2 thì ta sẽ có các bit block là 10, 00, 01.
B3: Tạo bộ key chung của người gửi và người nhận: Ta có bộ từ vựng V bao gồm tất cả các token (từ, dấu câu, vv.) có thể xuất hiện. Chia random bộ từ vựng thành bins (thùng chứa), mỗi bin () tương ứng với một bit block và chứa token. ( là số từ trong bộ từ vựng)
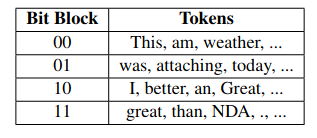
B4: Dựa trên chuỗi bit block ở B2, ta sẽ sử dụng mô hình LSTM để sinh ra các câu. Với mỗi bit block , mô hình LSTM sẽ lựa chọn một token cất trong bin . Mạng LSTM bị giới hạn chỉ có thể chọn token từ trong một bin nhất định tuy nhiên một bin có thể chứa lượng token đủ phong phú để đoạn văn bản được sinh ra trông "tự nhiên".
Ví dụ một đoạn text được gen ra từ chuỗi “1000011011” và key ở bảng trên:
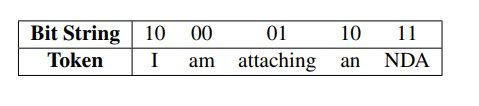
Để tăng tính tự nhiên và linh hoạt của đoạn văn bản được sinh ra, ta có thể thêm cùng một tập common-token vào tất cả các bin. Khi mạng LSTM chọn phải một common token trong một bin, ta sẽ bắt nó chọn thêm một token từ chính bin đó cho đến khi chọn được một token không thuộc tập common token.
Ngày nay khi các mô hình ngôn ngữ pretrained phát triển ngày càng mạnh mẽ và chính xác, ta có thể thay thế mạng LSTM trong việc lựa chọn token ở bước này bằng cách chọn trong bin token được xác định là có likelihood cao nhất theo mô hình ngôn ngữ.
2.2. Variable-length coding (VLC) - Huffman + patient Huffman
Thay vì fixed-length coding (một stegotext token chỉ encode bits) như ở phần 2.1., thuật toán VLC (Huffman coding) có thể encode nhiều hơn 1 bit trong mỗi token được sinh ra. Ngoài ra thì để cải thiện KL Divergence của stegotext, thuật toán patient-Huffman cũng đã được phát triển. (được giới thiệu trong paper Towards Near-imperceptible Steganographic Text)
Điểm mới của patient-Huffman là đưa vào giá trị ngưỡng : tại mỗi bước encode ta sẽ kiểm tra xem KL divergence (hoặc total variance distance) giữa và phân phối của cây Huffman có đủ nhỏ không. Nếu giá trị này lớn hơn một ngưỡng nhất định thì ta sẽ sinh ra token tiếp theo dựa vào phân phối của thay vì phân phối Huffman và "kiên nhẫn" đợi thời cơ tiếp theo.
Tại mỗi bước encoding:
B1: Từ language model và prefix ( là phần prefix tức kết quả đã được encode trước đó), tính toán được phân phối xác suất cho token tiếp theo
B2: Xây dựng cây Huffman cho phân phối (https://en.wikipedia.org/wiki/Huffman_coding) Theo phân phối Huffman mới, mỗi token nằm tại tầng thứ sẽ có hàm khối xác suất (probability mass) là .
B3: Tính TVD (hoặc KL divergence) giữa và phân phối Huffman tương ứng
B4:
- Nếu TVD (hoặc KL divergence) > thì sample ra một token theo phân phối
- Nếu TVD (hoặc KL divergence) < thì chúng ta sẽ sample ra token mới theo cây Huffman bằng cách tuân theo chuỗi bit . Bắt đầu từ gốc, nếu gặp bit 0 thì rẽ nhánh bên trái và rẽ nhánh phải nếu gặp bit 1, cho đến khi gặp một lá (leaf)
B5: Nối token mới với prefix
2.3. Arithmetic coding - mã hóa số học
(được giới thiệu trong paper Neural Linguistic Steganography)
Arithmetic coding là một phương pháp nén dữ liệu chuyên dùng để mã hóa các chuỗi với phân phối đã biết. Trong phương pháp mã hóa số học truyền thống, một chuỗi các phần tử sẽ được map với một chuỗi nhị phân phân phối đều (uniformly distributed). Để sử dụng phương pháp này trong steganography, chúng ta đảo ngược thứ tự: một đoạn mã có sẵn (uniformly sampled) sẽ được map với một chuỗi các từ.
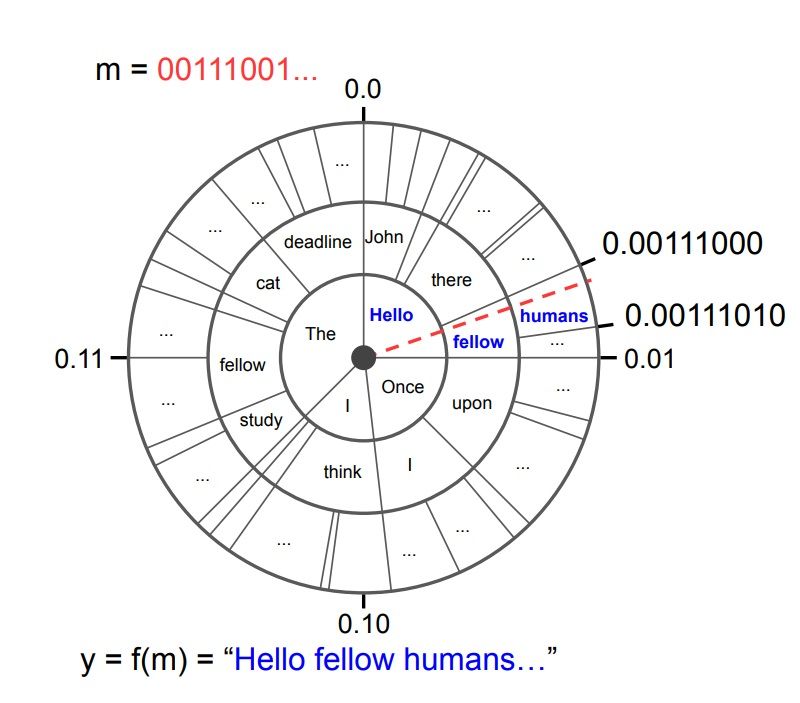
B1: Phương thức mã hóa được mô hình hóa trong hình trên (hình minh họa, trong thực tế phân phối xác suất của các từ sẽ được lấy từ xác suất có điều kiện trong một mô hình ngôn ngữ pre-trained). Các đường tròn đồng tâm thể hiện các bước timestep (trong cùng là t=1, rồi lần lượt là t=2, t=3, vv.). Mỗi đường tròn thể hiện xác suất có điều kiện . Ví dụ: cho = "Once" thì có "upon" và "I" là hai token duy nhất với xác suất bằng nhau. Sơ đồ hình tròn biểu diễn đoạn [0,1) với mốc 0 ở trên cùng.
B2: Mã hóa thông tin cần giấu thành một chuỗi bit . sẽ được coi như một biểu diễn dưới dạng nhị phân của một phân số trong đoạn . Phân số này sẽ biểu diễn một điểm duy nhất trên đường tròn cũng như một đường thẳng duy nhất nối từ tâm đến điểm đó.
B3: Bước encoding được thực hiện bằng cách lấy các token mà đường thẳng nói trên đi qua
Như vậy ta có thể áp dụng phương thức này để tạo ra các đoạn stegotext dựa vào context cho trước. Để đảm bảo đoạn text tạo ra được "tự nhiên" hơn, người ta có thể áp dụng các kỹ thuật như temperature sampling và top-k sampling.
Các nghiên cứu đã cho thấy, phương pháp mã hóa hình học đạt hiệu quả tối ưu không chỉ trong nén dữ liệu (data compression) mà cả đối với kỹ thuật giấu tin. Giả sử phân phối đích mà ta muốn "bắt chước" là , thì khi áp dụng phương pháp trên cho chuỗi phân phối đều ban đầu, ta sẽ được một phân phối mà , hay nói cách khác là đối với những câu dài. Do vậy và số bit trung bình dùng để mã hóa chính bằng entropy của .
Kết luận
Như vậy trong bài này mình đã trình bày một số khái niệm cơ bản về kỹ thuật giấu tin - steganography cũng như giới thiệu qua một số phương pháp giấu tin bằng cách generate văn bản chưa tin mật. Trong này những phần nặng hơn về toán mình cũng chưa có điều kiện để trình bày nên nếu quan tâm các bạn có thể đọc thêm trong từng paper nhé.