Vì công cụ và chuyên môn liên quan đến PySpark ngày càng được săn đón trên thị trường, bài viết này cung cấp bộ câu hỏi phỏng vấn và câu trả lời bao quát toàn bộ chủ đề từ cơ bản đến nâng cao dành cho dân công nghệ và dữ liệu. Apache PySpark là một công cụ phân tích dữ liệu hợp nhất được kết kế để xử lý các khối dữ liệu khổng lồ một cách nhanh chóng và hiệu quả.
Câu hỏi phỏng vấn PySpark cơ bản
Ưu điểm chính của việc sử dụng PySpark so với Python truyền thống để xử lý dữ liệu lớn là gì?
PySpark, API Python cho Apache Spark, cung cấp một số lợi thế so với Python truyền thống trong việc xử lý dữ liệu lớn. Bao gồm các:
Khả năng mở rộng để xử lý các tập dữ liệu lớn. Hiệu suất cao thông qua xử lý song song. Khả năng chịu lỗi để đảm bảo độ tin cậy của dữ liệu. Tích hợp với các công cụ dữ liệu lớn khác trong hệ sinh thái Apache.
Làm cách nào để tạo SparkSession trong PySpark? Công dụng chính của nó là gì?
Trong PySpark, SparkSession đây là điểm bắt đầu để sử dụng chức năng Spark và được tạo bằng API SparkSession.builder
Công dụng chính của nó bao gồm:
Tương tác với Spark SQL để xử lý dữ liệu có cấu trúc. Tạo DataFrame. Cấu hình thuộc tính Spark. Quản lý vòng đời SparkContext và SparkSession. Sau đây là ví dụ về cách SparkSession tạo ra:
Mô tả những cách khác nhau để đọc dữ liệu vào PySpark
PySpark hỗ trợ đọc dữ liệu từ nhiều nguồn khác nhau, chẳng hạn như CSV, Parquet và JSON, cùng nhiều nguồn khác. Với mục đích này, nó cung cấp nhiều phương pháp khác nhau, bao gồm spark.read.csv(), spark.read.parquet(), spark.read.json(), spark.read.format(), spark.read.load().
Sau đây là ví dụ về cách dữ liệu có thể được đọc vào PySpark:
Làm cách nào để xử lý dữ liệu bị thiếu trong PySpark?
Trong PySpark, chúng ta có thể xử lý dữ liệu bị thiếu bằng một số phương pháp sau:
Chúng ta có thể xóa các hàng hoặc cột chứa giá trị bị thiếu bằng phương pháp .dropna(). Chúng ta có thể điền dữ liệu còn thiếu bằng một giá trị cụ thể hoặc sử dụng các phương pháp nội suy với phương thức .fillna(). Chúng ta có thể quy định các giá trị bị thiếu bằng cách sử dụng các phương pháp thống kê, chẳng hạn như giá trị trung bình hoặc trung vị, bằng cách sử dụng Imputer. Đây là một ví dụ về cách xử lý dữ liệu bị thiếu trong PySpark:
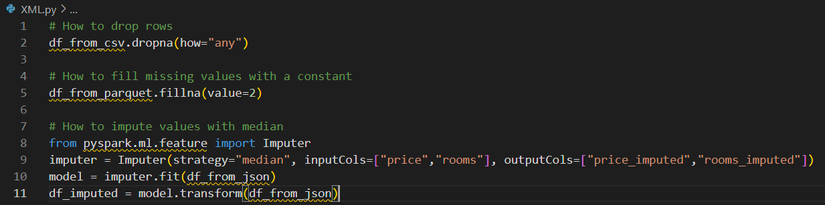
xử lý dữ liệu bị thiếu trong PySpark
Làm thế nào để lưu trữ dữ liệu trong PySpark để cải thiện hiệu suất?
Một trong những lợi thế của PySpark là nó cho phép chúng ta sử dụng các phương pháp .cache()hoặc .persist()lưu trữ dữ liệu trong bộ nhớ hoặc ở mức lưu trữ được chỉ định. Nhiệm vụ này cải thiện hiệu suất bằng cách tránh các phép tính lặp lại và giảm nhu cầu tuần tự hóa và hủy tuần tự hóa dữ liệu.
Sau đây là ví dụ về cách lưu trữ dữ liệu trong PySpark:
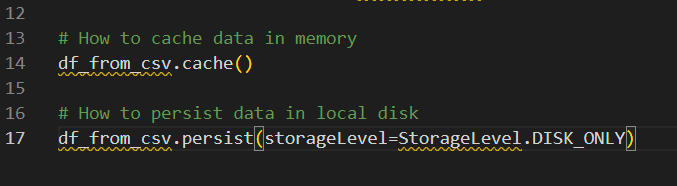
Lưu trữ dữ liệu trong PySpark
Mô tả cách thực hiện nối trong PySpark
Pyspark cho phép chúng ta thực hiện một số loại phép nối: nối trong, nối ngoài, nối trái và nối phải. Bằng cách sử dụng .join()phương thức này, chúng ta có thể chỉ định điều kiện nối trên tham số on và loại liên kết bằng how tham số đó, như trong ví dụ:
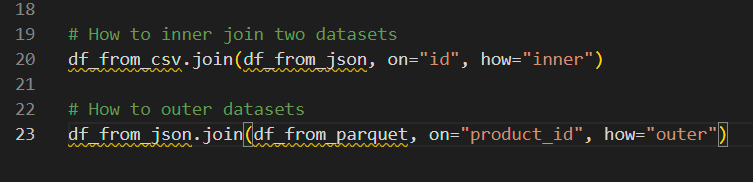
Thực hiện nối trong PySpark
Sự khác biệt chính giữa RDD, DataFrames và Datasets trong PySpark là gì?
Spark Resilient Distributed Datasets (RDD), DataFrame và Datasets là các khái niệm trừu tượng chính trong Spark cho phép chúng ta làm việc với dữ liệu có cấu trúc trong môi trường điện toán phân tán. Mặc dù tất cả chúng đều là cách biểu diễn dữ liệu, nhưng chúng có những điểm khác biệt chính:
RDD là các API cấp thấp thiếu lược đồ và cung cấp quyền kiểm soát dữ liệu. Chúng là bộ sưu tập đồ vật bất biến DataFrames là các API cấp cao được xây dựng dựa trên RDD được tối ưu hóa cho hiệu suất nhưng không phải là loại an toàn. Họ sắp xếp dữ liệu có cấu trúc và bán cấu trúc thành các cột được đặt tên. Bộ dữ liệu kết hợp các lợi ích của RDD và DataFrames. Chúng là các API cấp cao cung cấp khả năng trừu tượng hóa kiểu an toàn. Chúng hỗ trợ Python và Scala, đồng thời cung cấp khả năng kiểm tra kiểu thời gian biên dịch trong khi nhanh hơn DataFrames.
Giải thích khái niệm đánh giá lười biếng trong PySpark. Nó ảnh hưởng đến hiệu suất như thế nào?
PySpark triển khai một chiến lược được gọi là đánh giá lười biếng, trong đó các phép biến đổi được áp dụng trên các tập dữ liệu phân tán (RDD, DataFrames hoặc Datasets) không được thực thi ngay lập tức. Ngược lại, Spark xây dựng một chuỗi các thao tác hoặc phép biến đổi sẽ được thực hiện trên dữ liệu được gọi là biểu đồ chu kỳ có hướng (DAG). Đánh giá lười biếng này cải thiện hiệu suất và tối ưu hóa việc thực thi vì quá trình tính toán được trì hoãn cho đến khi một hành động được kích hoạt và thực sự cần thiết.
Vai trò của phân vùng trong PySpark là gì? Nó có thể cải thiện hiệu suất như thế nào?
Trong PySpark, phân vùng dữ liệu là tính năng chính giúp chúng ta phân phối tải đều trên các nút trong cụm. Phân vùng đề cập đến hành động chia dữ liệu thành các phần nhỏ hơn (phân vùng) được xử lý độc lập và song song trên cụm. Nó cải thiện hiệu suất bằng cách cho phép xử lý song song, giảm di chuyển dữ liệu và cải thiện việc sử dụng tài nguyên. Phân vùng có thể được kiểm soát bằng các phương pháp như .repartition()và .coalesce().
Giải thích khái niệm về biến phát sóng trong PySpark và cung cấp trường hợp sử dụng.
Biến phát sóng là một tính năng chính của các khuôn khổ điện toán phân tán Spark. Trong PySpark, chúng là các biến chia sẻ chỉ đọc được lưu vào bộ nhớ đệm và phân phối đến các nút cụm để tránh các hoạt động xáo trộn. Chúng có thể rất hữu ích khi chúng ta có một ứng dụng máy học phân tán cần sử dụng và tải một mô hình được đào tạo trước. Chúng ta phát sóng mô hình dưới dạng một biến và điều đó giúp chúng ta giảm chi phí truyền dữ liệu và cải thiện hiệu suất.
Câu hỏi phỏng vấn PySpark trung cấp
Sau khi nắm được những kiến thức cơ bản, chúng ta hãy chuyển sang một số câu hỏi phỏng vấn PySpark ở trình độ trung cấp để đi sâu hơn vào kiến trúc và mô hình thực thi của các ứng dụng Spark.
Trình điều khiển Spark là gì và trách nhiệm của nó là gì?
Trình điều khiển Spark là quy trình cốt lõi điều phối các ứng dụng Spark bằng cách thực thi các tác vụ trên các cụm. Nó giao tiếp với người quản lý cụm để phân bổ tài nguyên, lên lịch tác vụ và giám sát việc thực hiện các công việc Spark.
Spark DAG là gì?
Biểu đồ tuần hoàn có hướng (DAG) trong Spark là một khái niệm quan trọng vì nó đại diện cho mô hình thực thi logic Spark. Nó được định hướng vì mỗi nút biểu thị một phép biến đổi được thực hiện theo một thứ tự cụ thể ở các cạnh. Nó không có tính tuần hoàn vì không có vòng lặp hoặc chu trình nào trong kế hoạch thực hiện. Kế hoạch này được tối ưu hóa bằng cách sử dụng các phép biến đổi đường ống, kết hợp nhiệm vụ và đẩy xuống vị từ.
Các loại trình quản lý cụm khác nhau có sẵn trong Spark là gì?
Spark hiện hỗ trợ các trình quản lý cụm khác nhau để quản lý tài nguyên và lập kế hoạch công việc, bao gồm:
Độc lập, cụm đơn giản được tích hợp trong Spark. Hadoop YARN là một trình quản lý chung trong Hadoop được sử dụng để lập kế hoạch công việc và quản lý tài nguyên. Kubernetes được sử dụng để tự động hóa, triển khai, mở rộng quy mô và quản lý các ứng dụng được đóng gói. Apache Mesos là một hệ thống phân tán được sử dụng để quản lý tài nguyên cho từng ứng dụng.
Mô tả cách triển khai chuyển đổi tùy chỉnh trong PySpark.
Để triển khai một phép chuyển đổi tùy chỉnh trong PySpark, chúng ta có thể định nghĩa một hàm Python hoạt động trên PySpark DataFrames và sau đó sử dụng phương .transform()thức để tạo ra phép chuyển đổi.
Đây là ví dụ về cách triển khai chuyển đổi tùy chỉnh trong PySpark:
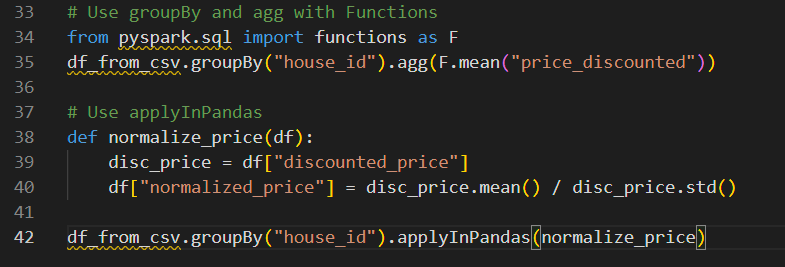
Triển khai chuyển đổi tùy chỉnh trong PySpark
Bạn đã gặp phải những thách thức nào khi làm việc với các tập dữ liệu lớn trong PySpark? Bạn đã vượt qua chúng như thế nào?
Với câu hỏi này, chúng ta có thể liên hệ đến kinh nghiệm của riêng mình và kể một trường hợp cụ thể mà chúng ta gặp phải những thách thức với PySpark và các tập dữ liệu lớn có thể bao gồm một số điều sau:
Quản lý bộ nhớ và sử dụng tài nguyên. Độ lệch dữ liệu và phân bổ khối lượng công việc không đồng đều. Tối ưu hóa hiệu suất, đặc biệt đối với các chuyển đổi và xáo trộn rộng. Gỡ lỗi và xử lý sự cố các lỗi công việc phức tạp. Phân vùng và lưu trữ dữ liệu hiệu quả. Để khắc phục những vấn đề này, PySpark cung cấp tính năng phân vùng tập dữ liệu, lưu trữ đệm các kết quả trung gian, sử dụng các kỹ thuật tối ưu hóa tích hợp, quản lý cụm mạnh mẽ và tận dụng các cơ chế chịu lỗi.
Làm thế nào để tích hợp PySpark với các công cụ và công nghệ khác trong hệ sinh thái dữ liệu lớn?
PySpark tích hợp mạnh mẽ với nhiều công cụ dữ liệu lớn, bao gồm Hadoop, Hive, Kafka và HBase, cũng như lưu trữ đám mây như AWS S3 và Google Cloud Storage. Tích hợp này được thực hiện bằng các trình kết nối, thư viện và API tích hợp do PySpark cung cấp.
Một số biện pháp tốt nhất để thử nghiệm và gỡ lỗi ứng dụng PySpark là gì?
Một số phương pháp hay nhất được đề xuất để thử nghiệm và gỡ lỗi Ứng dụng PySpark bao gồm:
Viết bài kiểm tra đơn vị bằng cách sử dụng pyspark.sql.test.SQLTestUtils cùng với thư viện Python ( pytest) Gỡ lỗi ứng dụng và ghi nhật ký tin nhắn bằng thư viện logging cũng như Spark UI Tối ưu hóa hiệu suất bằng API Spark org.apache.spark.metrics và các công cụ giám sát hiệu suất.
Bạn sẽ xử lý các vấn đề về bảo mật dữ liệu và quyền riêng tư như thế nào trong môi trường PySpark?
Việc chia sẻ dữ liệu ngày nay đã trở nên dễ dàng hơn nên việc bảo vệ thông tin nhạy cảm và bí mật là cách tốt để tránh rò rỉ dữ liệu. Một trong những phương pháp hay nhất mà chúng tôi có thể làm theo là áp dụng mã hóa dữ liệu trong quá trình xử lý và lưu trữ.
Trong PySpark, chúng ta có thể đạt được điều đó bằng cách sử dụng aes_encrypt()và aes_decrypt()các hàm cho các cột trong DataFrame. Chúng ta cũng có thể sử dụng một thư viện khác, chẳng hạn như thư viện mật mã, để đạt được mục tiêu này.
Mô tả cách sử dụng PySpark để xây dựng và triển khai mô hình học máy.
PySpark cung cấp cho chúng ta thư viện MLIb, một thư viện học máy có thể mở rộng để xây dựng và triển khai các mô hình học máy trên các tập dữ liệu lớn. API thư viện này có thể được sử dụng cho một số tác vụ trong quy trình ML, chẳng hạn như xử lý trước dữ liệu, thiết kế tính năng, đào tạo mô hình, đánh giá và triển khai. Sử dụng các cụm Spark, chúng ta có thể triển khai các mô hình ML dựa trên PySpark trong sản xuất bằng cách sử dụng suy luận theo lô hoặc theo luồng.
Câu hỏi phỏng vấn máy chủ SQL dành cho kỹ sư dữ liệu
Nếu bạn đang phỏng vấn cho một vị trí kỹ sư dữ liệu, hãy chuẩn bị những câu hỏi đánh giá khả năng thiết kế, tối ưu hóa và khắc phục sự cố của các ứng dụng PySpark trong môi trường sản xuất. Hãy cùng tìm hiểu một số câu hỏi phỏng vấn điển hình mà bạn có thể gặp phải.
Mô tả cách bạn sẽ tối ưu hóa một tác vụ PySpark đang chạy chậm. Bạn sẽ xem xét những yếu tố chính nào?
Nếu tác vụ PySpark chạy chậm, chúng ta có thể cải thiện một số khía cạnh để tối ưu hóa hiệu suất của tác vụ đó:
Đảm bảo kích thước và số lượng phân vùng dữ liệu phù hợp để giảm thiểu việc xáo trộn dữ liệu trong quá trình chuyển đổi. Sử dụng DataFrames thay vì RRD vì họ đã sử dụng một số mô-đun Tối ưu hóa để cải thiện hiệu suất của khối lượng công việc Spark. Sử dụng các phép nối phát sóng và các biến phát sóng để nối một tập dữ liệu nhỏ với tập dữ liệu lớn hơn. Bộ nhớ đệm và duy trì các DataFrame trung gian được sử dụng lại. Điều chỉnh số lượng phân vùng, lõi thực thi và phiên bản để sử dụng hiệu quả tài nguyên cụm. Chọn các định dạng tệp thích hợp để giảm thiểu kích thước dữ liệu.
Làm thế nào để đảm bảo khả năng chịu lỗi trong các ứng dụng PySpark?
Để đảm bảo khả năng chịu lỗi trong ứng dụng PySpark, chúng ta có thể thực hiện một số chiến lược:
Sử dụng Checkpointing để lưu dữ liệu tại một số điểm nhất định. Sao chép dữ liệu của chúng tôi bằng cách lưu nó trên nhiều máy khác nhau. Giữ nhật ký về những thay đổi được thực hiện đối với dữ liệu của chúng tôi trước khi chúng xảy ra. Thực hiện kiểm tra xác thực dữ liệu để quét lỗi. Chọn mức độ kiên trì phù hợp. Sử dụng khả năng chịu lỗi tích hợp của Spark để tự động thử lại các tác vụ không thành công.
Có những cách nào để triển khai và quản lý ứng dụng PySpark?
Chúng tôi có thể triển khai và quản lý các ứng dụng PySpark bằng các công cụ sau:
YARN: trình quản lý tài nguyên giúp chúng tôi triển khai và quản lý các ứng dụng trên cụm Hadoop Kubernetes: Spark cung cấp hỗ trợ triển khai các ứng dụng bằng cụm Kubernetes Databricks: Nó cung cấp nền tảng được quản lý hoàn toàn cho các ứng dụng PySpark, loại bỏ sự phức tạp của việc quản lý cụm.
Bạn sẽ giám sát và khắc phục sự cố các tác vụ PySpark chạy trong môi trường sản xuất như thế nào?
PySpark cung cấp cho chúng ta các công cụ sau để giám sát và khắc phục sự cố các công việc đang chạy trong môi trường sản xuất:
Spark UI: Giao diện người dùng dựa trên web giúp chúng tôi theo dõi tiến độ công việc, sử dụng tài nguyên và thực hiện tác vụ. Ghi nhật ký: Chúng tôi có thể định cấu hình ghi nhật ký để nắm bắt thông tin chi tiết về lỗi và cảnh báo. Số liệu: Chúng ta có thể sử dụng hệ thống giám sát để thu thập và phân tích số liệu liên quan đến tình trạng cụm và hiệu suất công việc.
Giải thích sự khác biệt giữa phân bổ động và tĩnh của Spark và khi nào bạn có thể chọn một trong hai.
Trong Spark, phân bổ tĩnh đề cập đến việc cung cấp trước và liên tục các tài nguyên cố định, chẳng hạn như bộ nhớ thực thi và lõi, trong toàn bộ thời gian của ứng dụng. Ngược lại, phân bổ động cho phép Spark điều chỉnh linh hoạt số lượng người thực thi dựa trên nhu cầu khối lượng công việc. Các tài nguyên có thể được thêm vào hoặc loại bỏ khi cần thiết, cải thiện việc sử dụng tài nguyên và giảm chi phí.
Phần kết luận
Trong bài viết này, chúng tôi đã đề cập đến nhiều câu hỏi phỏng vấn PySpark bao gồm các chủ đề cơ bản, trung cấp và nâng cao. Từ việc hiểu các khái niệm và ưu điểm cốt lõi của PySpark cho đến đi sâu vào các kỹ thuật khắc phục sự cố và tối ưu hóa phức tạp hơn, chúng tôi đã khám phá các lĩnh vực chính mà các nhà tuyển dụng tiềm năng có thể quan tâm.
Đọc thêm: