Lời mở đầu
Xin chào mọi người, bài dịch lần này mình muốn chia sẻ với anh em một chủ đề thú vị liên quan đến Optical Character Recognize (OCR). Đây đã và đang là một công nghệ hot và có rất nhiều paper xoay quanh việc tăng độ chính xác cho OCR nhưng vẫn đảm bảo tốc độ runtime. Trong OCR, mình tạm chia một cách dễ dàng gồm OCR trên văn bản có cấu trúc và không có cấu trúc. Nhưng bài dịch này tập trung giải quyết một vấn đề nhận nhiều quan tâm đó là phát triển hệ thống OCR cho các hình ảnh có độ phân giải thấp (low - resolution). Đa phần mình (tác giả) nhận thấy có một sự thiếu sót khi xử lý với pre-trained Tesseract models. Và trong quá trình thực nghiệm lại, mình thấy có thể huấn luyện lại model pre-trained bằng chính bộ data của mình. Tuy nhiên, nguồn tài liệu tham khảo để có thể thực hiện ý tưởng này khá ít và sẽ là thử thách đối với những người less experience. Và 👉️bài dịch này chính là câu trả lời mà bạn cần tìm 😄.
Nội dung
Một số từ khóa
- Optical Character Recognize - OCR
- Tesseract
- Pre-trained model
Các bước thực hiện chính (Step involved)
- Data preparing: Tổng hợp và đặt tên cho image files
- Generating Box files
- Annotating Box files
- Training Tesseract
Và okie, let's go! 😀
1. Data preparing:
Nhiệm vụ đầu tiên trong việc huấn luyện lại Tesseract model đó là thu thập tất cả các file ảnh để sử dụng làm custom data.Đó có thể là các file full-page document hoặc các dòng single line được cắt từ các đoạn text. Và mình xin lưu ý rằng, việc chọn hình ảnh huấn luyện cần đồng bộ về ngôn ngữ hoặc dạng text mà bạn muốn trích xuất. Đây là một giai đoạn vô cùng quan trọng để đạt được độ chính xác mong muốn cho quá trình huấn luyện lại model. Do đó, trong quá trình thu thập data, anh em cần có những tiêu chuẩn riêng để đảm bảo cho hình ảnh huấn luyện và đỡ cực hơn trong quá trình xử lý data sau đó.
-
Full-page document

-
Single line of text
Sau khi thực hiện xong giai đoạn thu thập data - gathering data, chúng ta sẽ tạo một cấu trúc thư mục như dưới đây để dễ dàng quản lý hơn.
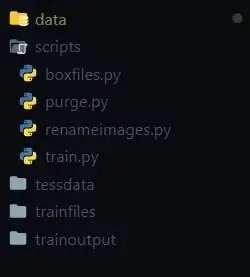
Nguồn: https://saiashish90.medium.com/training-tesseract-ocr-with-custom-data-d3f4881575c0
Bước cuối cùng của step 1 là cần đổi tên các file ảnh sao cho đúng định dạng mà Tesseract có thể hiểu - rename file images.
Cấu trúc chung: [language name].[font name].exp[number].[file extension]
# use this script to rename all the image files before generating boxfiles.
# Language and font should not have spaces and preferable an abbreviated name should be used. import os
dir = 'tesseract/data'
images = [f for f in os.listdir(dir)[:2] if f.endswith(('.jpg', '.jpeg', '.png', '.tif', '.bmp'))]
print(f"{len(images)} number of images found")
lang = input('Enter The language without spaces\n')
font = input('Enter font without spaces\n')
part1 = f"{lang}.{font}.exp"
for i, image in enumerate(images): filename = f"{part1}{i}.{image[-3:]}" print(filename) os.rename(os.path.join(dir, image), os.path.join(dir, filename))
2. Generating box data
Ở bước này, chúng ta sẽ tạo các tệp để chứa box bao quanh các ký tự. Tesseract hoàn toàn có thể thực hiện tác vụ xác định bounding box nhưng việc chúng ta không thể có metric để đảm bảo chắc chắn cho kết quả các box. Do đó, chúng ta sẽ thực hiện tạo các file box tương ứng với các file ảnh và theo một cấu trúc chung: [language name].[font name].exp[number].box
# reads all the image files present in data dir and creates corresponding box files.
# Files need to have the correct naming convention.
import os
os.chdir('tesseract/data')
number_of_files = len(os.listdir('./'))
for i in range(0, number_of_files): os.system(f"tesseract eng.ocrb.exp{i}.jpg eng.ocrb.exp{i} batch.nochop makebox")
Các file boxes sẽ chứa các danh sách các bounding box của các ký tự trên ảnh và để sau đó tiến hành trả lời hai câu hỏi WHERE và WHAT với bước gán nhãn tiếp theo.
3. Annotating Box file
Bây giờ chúng ta sẽ đến bước thực hiện gán nhãn cho các tệp box. Mọi người có thể sử dụng phần mềm như jTessBoxEditor để mở các file ảnh và kiểm tra danh sách các bounding box cho từng ký tự trong ảnh mà tesseract thực hiện trước đó. Chúng ta có thể biết chính xác danh sách các boxes và các ký tự trong đó. Và đặc biệt, chúng ta hoàn toàn có thể điều chỉnh hoặc tự bouding box cho các ký tự Tesseract chưa thực hiện.
Đây là một bước quan trọng và có thể nói bất kỳ một lỗi nào trong khâu gán nhãn sẽ ảnh hưởng nghiêm trọng đến kết quả cũng như độ chính xác của mô hình OCR.
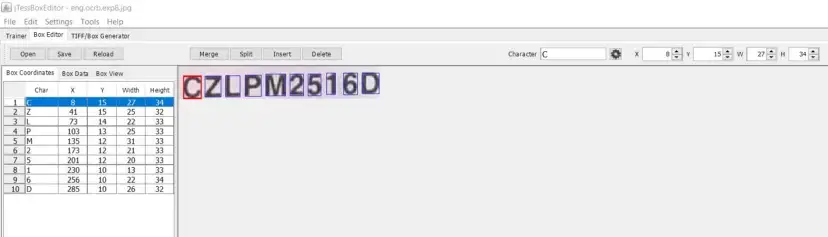
Nguồn: https://saiashish90.medium.com/training-tesseract-ocr-with-custom-data-d3f4881575c0
4. Training data (Tesseract model)
Và sau khi đã chuẩn bị đủ nguyên vật liệu cần thiết, giờ chúng ta sẽ tiến hành "nấu" thôi! 😅
# Run after annotating all the box files generated from boxfiles.py
# https://github.com/nguyenq/jTessBoxEditor/releases/tag/Release-2.3.1 can be used for annotating. import os
import subprocess
srcdir = 'tesseract/data'
destdir = 'tesseract/trainfiles'
# Removing all previous trained files.
try: os.remove('tesseract/tessdata/eng.traineddata')
except OSError: pass
files = os.listdir(srcdir)
for item in files: if not item.endswith(('.jpg', '.box')): os.remove(os.path.join(srcdir, item)) # Generating the tuples of filenames
files = os.listdir(srcdir)
jpgs = [x for x in files if x.endswith('.jpg')]
boxes = [x for x in files if x.endswith('.box')]
trainfiles = list(zip(jpgs, boxes)) # generating TR files and unicode charecter extraction
unicharset = f"unicharset_extractor --output_unicharset ../../{destdir}/unicharset "
unicharset_args = f""
errorfiles = []
for image, box in trainfiles: unicharset_args += f"{box} " if os.path.isfile(f"{destdir}/{image[:-4]}.tr"): continue try: print(image) os.system(f"tesseract {srcdir}/{image} {destdir}/{image[:-4]} nobatch box.train") except: errorfiles.append((image, box))
os.chdir(srcdir)
subprocess.run(unicharset+unicharset_args)
os.chdir('../../') # Creating font properties file
with open(f"{destdir}/font_properties", 'w') as f: f.write("ocrb 0 0 0 1 0") # # Getting all .tr files and training
output = '../../tesseract/trainoutput'
trfiles = [f for f in os.listdir(destdir) if f.endswith('.tr')]
os.chdir(destdir)
mftraining = f"mftraining -F font_properties -U unicharset -O {output}/eng.unicharset -D {output}"
cntraining = f"cntraining -D {output}"
for file in trfiles: mftraining += f" {file}" cntraining += f" {file}"
subprocess.run(mftraining)
subprocess.run(cntraining)
os.chdir('../../')
# # Renaming training files and merging them
os.chdir(output[6:])
os.rename('inttemp', 'eng.inttemp')
os.rename('normproto', 'eng.normproto')
os.rename('pffmtable', 'eng.pffmtable')
os.rename('shapetable', 'eng.shapetable')
os.system(f"combine_tessdata eng.") # Writing log file
if len(errorfiles) == 0: errorfiles.append(('no', 'Error'))
with open('tesseract/scripts/logs.txt', 'w') as f: f.write('\n'.join('%s %s' % x for x in errorfiles))
- Đầu tiên, chúng ta đọc tất cả các file box và ảnh cũng như tạo thành một tuple.
- Với mỗi ảnh/box file trong danh sách, trước tiên anh em kiểm tra xem train-data có generated cho ảnh chưa? Nếu chưa, anh em chạy lệnh:
tesseract {srcdir}/{image} {destdir}/{image[:-4]} nobatch box.train
Điều này sẽ tạo danh sách các file .tr trong thư mục .trainfiles. Chúng ta cũng thêm các file box bằng câu lệnh
unicharset_extractor — output_unicharset ../../{destdir}/unicharset
Câu lệnh này sau đó sẽ trích xuất tất cả các ký tự từ tất cả các file box và thêm chúng vào file unicharset.
- Bước tiếp theo, chúng ta sẽ tạo file font-properties
Mỗi dòng bên trong file
font-propertiesđã được định dạng sẵn theo cấu trúc:fontnameitalicboldfixedseriffraktur.
Trong đó, fontname là tên của chuỗi mà anh em tự đặt (hay nôm na là một tên đại diện). Còn 5 giá trị còn lại sẽ được gán theo hai giá trị nhị phân 0 và 1 tương ứng với cơ chế có hoặc không.
Hơi khó hiểu nhỉ 🤔. Ok để mình lấy một ví dụ:
bold-italic 1 1 0 0 0
Dòng trên có nghĩa là có một font tên là bold-italic và nó là kiểu nghiêng, in đậm. Anh em hoàn toàn có thể edit cho file dựa trên font của dữ liệu ảnh anh em thu thập.
-
Bước tiếp theo, chúng ta thêm tất cả các file vào lệnh mftraining và cntraining và chạy chúng. Kết quả là một file tập các ký tự cho ngôn ngữ đang thực hiện OCR và 4 file khác trong thư mục trainoutput.
-
Cuối cùng, chúng ta có thể kết hợp tất cả các file sang file có extension là .traineddata. Sau đó, chúng ta sẽ copy file này đến thư mục nguồn của Tesseract và sử dụng
-langđể sử dụng kết quả trained.
tesseract image.png -l [lang]
Lưu ý rằng: sử dụng đoạn code dưới đây để xóa tất cả dữ liệu huấn luyện và bắt đầu lại từ đầu
# Removes all previous training and log files.
import os
srcdir = 'tesseract/trainfiles'
destdir = 'tesseract/trainoutput'
files = os.listdir(srcdir) for item in files: if not item.endswith(('.jpg', '.box')): os.remove(os.path.join(srcdir, item)) files = os.listdir(destdir)
for item in files: os.remove(os.path.join(destdir, item))
Lời cảm ơn
Hy vọng bài dịch này sẽ cung cấp cho anh em những điều thú vị về thư viện Tesseract cũng như hiểu sâu hơn về mô hình OCR sức mạnh này. Cảm ơn tác giả Sai Ashish đã cung cấp nhiều kiến thức thú vị này.