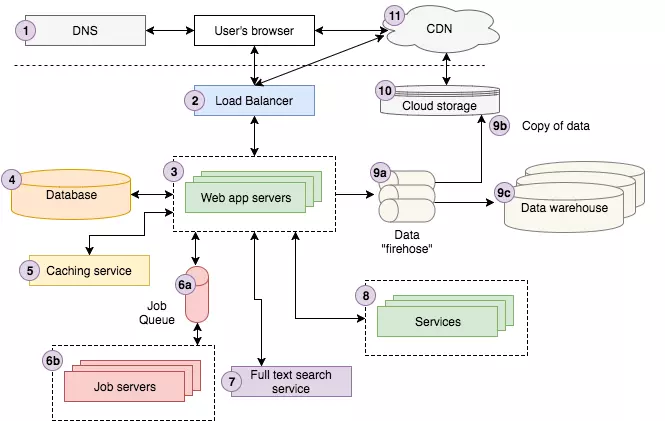
Đây là một kiến trúc cơ bản mà bất kì một người mới gia nhập backend không nên bỏ qua. Thật lòng mà nói, 200Lab thấy rằng nắm được các thành phần trong này và vận dụng hợp lý thì hệ thống đã rất ổn rồi.
Bài chia sẻ được 200Lab tổng hợp, tự viết lại dựa trên kiến trúc được chia sẻ bởi StoryBlocks.
1. DNS
Đầu tiên chúng ta cùng tìm hiểu DNS là gì? DNS là từ viết tắt của Domain Name System, hiểu nôm na nó giống như phonebook của Internet. Đây là một phần không thể thiếu, giúp “phân giải” các domain (tên miền) thành các địa chỉ máy tính (IP) trên mạng.
Thật ra cũng giống như thay vì chúng ta nhớ số điện của “crush” để nhập lại mỗi khi liên lạc, ta lưu vào danh bạ để lần sau chỉ cần call “crush” là được. Sau này đổi crush thì vào edit số là được nhé.
2. Load Balancer
Hiểu theo nghĩa tiếng Việt nó là Bộ cân bằng tải. Khi đạt đến một ngưỡng tải nhất định, một máy tính không thể cứ mãi nâng cấp. Khi ấy chúng ta sẽ dùng nhiều máy tính hơn để cùng chia sẻ, gánh vác các request từ client. Load Balancer (LB) sẽ đứng ra giúp việc phân chia các request vào các server.
3. Web Application Servers
Chính là các server phục vụ request của chúng ta. Như trong ảnh, ta có thể có nhiều Web Servers thay vì 1 để tăng tải.
Thông thường thì server web đóng vai trò như một Rendering Server, trả về HTML để trình duyệt hiểu và hiển thị thông tin cho người dùng cuối.
4. Database
Database là nơi lưu trữ toàn bộ dữ liệu trong hệ thống. Trong kiến trúc này, tác giả chỉ vẽ tượng trưng Database như một thành phần bắt buộc của hệ thống, để lưu trữ thông tin.
Trên thực tế Database cũng có thể chia ra nhiều phần hơn, tuy nhiên ta cứ hiểu gọi chung là Database.
200Lab cho rằng nếu các bạn sử dụng Web Server (3) để vừa xử lý và render HTML thì sẽ như trong hình, còn nếu có dùng Service (8) thì các bạn nên kết nối (8) và (4) thay vì (3) và (4).
5. Caching Service
Trong quá trình hệ thống hoạt động, hẳn sẽ có những thành phần dữ liệu thường xuyên được truy xuất nhưng rất ít khi thay đổi. Hoặc trong trường hợp quá trình tìm kiếm và tổng hợp dữ liệu rất lâu, chúng ta nên nghĩ tới Cache.
Thông thường các caching service sử dụng dạng key/value trên RAM để truy xuất nhanh nhất O(1).
6. Job Queue (6a) & Servers (6b)
Trên thực tế, không phải tất cả request đều cần hệ thống thực hiện đầy đủ rồi trả về. Rất nhiều trường hợp, hệ thống cần đưa vào hàng đợi (Queue), dưới dạng FIFO (First-in-first-out), rồi trả về client nhanh nhất có thể. Hàng đợi này sẽ được một xử lý thông qua các Job/Server khác để tránh overload các service chính.
VD: Đơn hàng tạo thành công, hệ thống cần gởi email thông báo, gởi notification cho các bên có liên quan và một loạt các nghiệp vụ khác. Nếu để client phải đợi hệ thống xong hết các công việc này sẽ không hợp lý, resource tại servers tiếp nhận request cũng tiêu tốn rất lớn.
7. Full-text Search Service
Như tên gọi của nó, service này chuyên dùng để tìm kiếm full-text.
Ví dụ: bạn gõ vào tìm kiếm “áo thun xanh”, “áo xanh thun”. Hệ thống phải cần trả về các sản phẩm có các keyword trên. Công việc nghe tưởng chừng tưởng không khó ấy lại khó không tưởng. Vì một DB thông thường không thể có sức mạnh và tính năng để làm việc này một cách tốt và nhanh nhất.
Thay vào đó, chúng ta sẽ dùng Elasticsearch, Sphinx Search, Solr hoặc các index DB chuyên về full-text hơn.
8. Services
Khi hệ thống đạt một ngưỡng tải nhất định, hệ thống thường nên được chia nhỏ ra thành các service riêng lẻ.
Các service này đóng một vai trò nhất định: Account Service, Product Service, Order Service,… Mục đích vẫn là chia để trị tốt hơn, tránh dồn hết vào một server, 1 service bị nghẽn sẽ ảnh hưởng tới các toàn bộ service khác.
Ở đây các bạn có thể thấy rằng Web Server chỉ còn làm nhiệm vụ của nó là render HTML thôi, các service bên dưới mới thực sự xử lý thông tin. Những service này có thể độc lập hoặc có giao tiếp với nhau mà sau này kiến trúc “tiến hoá” lên Micro Services rất nổi tiếng.
9. Data
Cả 3 phần (9a), (9b) và (9c) trong kiến trúc này đều thể hiện các xây dựng Data Warehouse mặc dù không có chi tiết.
Data Warehouse (nhà kho dữ liệu) là nơi xắp xếp và lưu trữ dữ liệu thường lớn tới siêu lớn. Dữ liệu tại DWH có thể được tổ chức theo cách riêng để phục vụ cho thống kê, phân tích, báo cáo và Machine Learning, cần rất nhiều data để vận hành.
Chúng ta sẽ không dùng trực tiếp Database cho việc này, vì nó không phù hợp, ảnh hưởng tải hiện tại của hệ thống.
10. Cloud storage
Thay vì tự phải lưu trữ các file vật lý (hình ảnh, văn bản, nhạc, video,…) trên các service và lo lắng về việc mất mát và quản lý chúng. Các service này thường là bên thứ ba (third-party / 3rd cung cấp) như: AWS S3, Google Storage.
Chi phí cho các service này cũng rất rất rẻ. Vì thế, hệ thống nên “chuyển giao” phần này cho các Cloud Storage để nhẹ gánh lo âu.
11. CDN – Content Delivery Network
Khi người dùng chúng ta từ khắp mọi nơi trên thế giới. Khi hệ thống cần phục vụ file vật lý tốt hơn: nhanh, ổn định. Lúc đó ta cần dùng CDN để chúng gánh vác việc này.
CDN có nhiệm vụ chính là phân phối các file vật lý lưu trữ ở rất nhiều server trên thế giới thay vì một nơi. Từ đó người dùng ở gần server nào thì sẽ được server ấy phục vụ. Với một mạng lưới cung cấp file vật lý như thế, chúng ta cũng không còn lo lắng quá nhiều về việc backup, hoặc server chịu tải và băng thông lớn nữa.
Cũng như Cloud Storage, các CDN cũng thường có giá không cao, hiện có nhiều đơn vị cung cấp với giá rất cạnh tranh để các nhà làm hệ thống có nhiều lựa chọn thay thế.
Tóm lại:
Qua bài viết này, 200Lab nghĩ rằng các bạn đọc, đặc biệt những bạn mới, sẽ hiểu hơn về các thành phần quan trọng trong hệ thống và giúp các bạn xác định phần nào định hướng phát triển hệ thống nhé.
Tham khảo bài viết gốc: https://edu.200lab.io/blog/kien-truc-web-he-thong-cho-nguoi-moi-bat-dau