Mở đầu
Xin chào các bạn, nhân dịp đang có cơ hội được tìm hiểu về ELK Stack mình muốn chia sẻ với các bạn một số thứ mà mình mò mẫm và học được từ công nghệ đang khá hot này. Như tiêu đề bài viết, trong bài này mình sẽ hướng dẫn các bạn cách phân tích log, trích xuất ra các trường trong log của Web Server Apache, ngoài ra đối với các log của các phần mềm khác thì cũng gần tương tự để chúng ta có thể áp dụng.
Tổng quan về ELK Stack
ELK Stack được viết rút gọn từ 3 từ ( Elasticsearch - LogStash - Kibana ), 3 công cụ này hợp tại tạo nên một môi trường giúp chúng ta phân tích, lưu trữ tập trung, tìm kiếm và mô hình hóa log để có thể tiếp cận một cách dễ dàng hơn.
Đến với từng công cụ trong Stack này:
- Beats - Filebeat: Phần mềm này sẽ được cài ở các máy chủ mà chúng ta muốn lấy log. Phần mềm này sẽ giúp chúng ta chọn ra những loại log nào cần lấy và đẩy log đến LogStash cho tiền xử lý hoặc gửi trực tiếp đến Elasticsearch.
- LogStash: Phần mềm này sẽ giúp chúng ra lọc ra những trường cần thiết trong log, hoặc sửa đổi log trước khi gửi đến Elasticsearch.
- ElastichSearch: Log sẽ được lưu trữ và tìm kiếm nhanh chóng tại đây.
- Kibana: Phần mềm giúp mô hình hóa log dưới dạng biểu đồ, cột,...
Phân tích Apache Log
Trước hết đi vào quá trình phân tích log ta cần phải biết Apache ghi ra những loại log gì, Apache mặc định sẽ ghi ra 2 loại log là Access Log và Error Log tại thư mục /var/log/apache2/

Xem qua định dạng Access Log:

Về cơ bản chúng ta hiểu ý nghĩa từng mục của Apache Access Log thế này:

Nếu để mặc định mà đẩy log này lên ElasticSearch thì sẽ rất rối, không thể bóc tách được ra các trường mà chúng ta cần. Vì vậy chúng ta sẽ cần lọc ra các trường tại LogStash bằng các plugin. Chúng ta có thể tham khảo các pipeline mẫu về phân tích log các phần mềm phổ biến tại trang chủ Elastic.co .
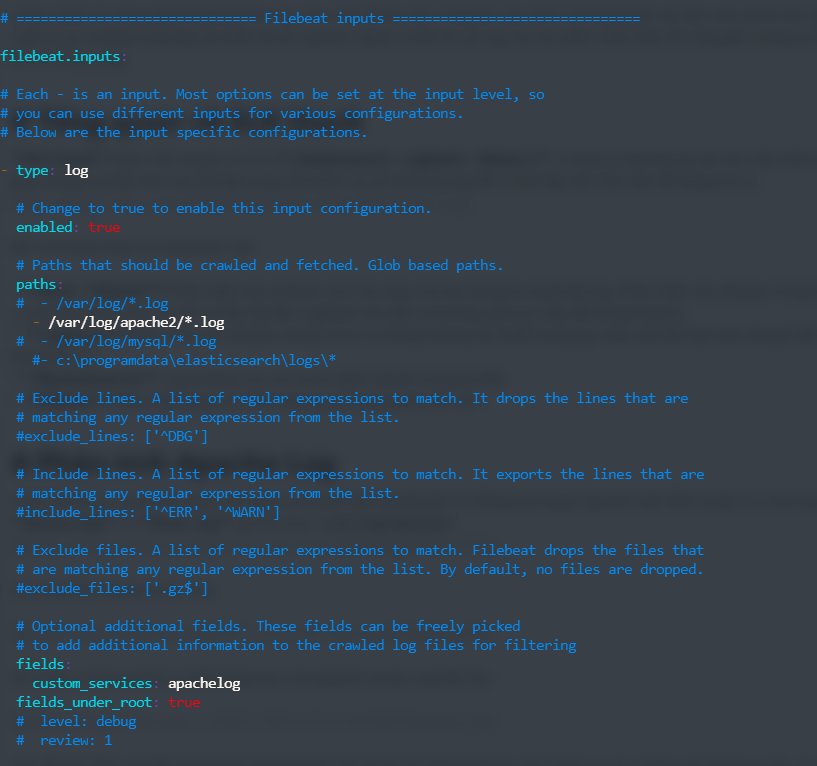
Đầu tiên, tại Filebeat ở máy cần lấy log ta thêm trường "custom_services: apachelog" trong phần "filebeat.inputs:" ở file /etc/filebeat/filebeat.yml như hình để có thể định danh được luồng log này khi đẩy lên LogStash:
Quay về với LogStash trên ELK Stack Server, mình sử dụng file YAML với cấu hình như phía dưới được lưu tại /etc/logstash/conf.d/apache2-pipeline.conf .
input { beats { port => 5044 host => "0.0.0.0" }
}
filter { if [custom_services] == "apachelog" { grok { match => { "message" => ["%{IPORHOST:clientip} - %{DATA:username} \[%{HTTPDATE:http_date}\] \"%{WORD:method} %{DATA:path} HTTP/%{NUMBER:apache_http_version}\" %{NUMBER:code} %{NUMBER:sent_bytes}( \"%{DATA:referrer}\")?( \"%{DATA:agent}\")?", "%{IPORHOST:clientip} - %{DATA:username} \\[%{HTTPDATE:http_date}\\] \"-\" %{NUMBER:code} -" ] } } mutate { rename => { "clientip" => "apache_remote_ip" "username" => "apache_user" "http_date" => "apache_access_time" "method" => "apache_method" "path" => "apache_path" "code" => "apache_code" "apache_http_version" => "apache_http_version" "sent_bytes" => "apache_sent_bytes" "referrer" => "apache_referrer" "agent" => "apache_agent" } } }
}
output { elasticsearch { hosts => localhost manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" }
}
Giải thích đơn giản là với input vào có trường "custom_services" bằng "apachelog" thì sẽ tiến hành tìm đoạn message và phân tích ra theo các định dạng có sẵn như: IPRHOST, HTTPDATE, NUMBER,... Sau đó chúng ta sẽ sửa đổi tên các thành phần mà đã phân tích từ message bằng mutate và rename. Còn 2 khối input và output là luồng chạy của dữ liệu. Sau khi cấu hình xong chúng ta restart services để cập nhật cấu hình mới.
Sau khi cập nhật xong trên ElasticSearch chúng ta sẽ thấy xuất hiện thêm các trường mà ta đã lọc.
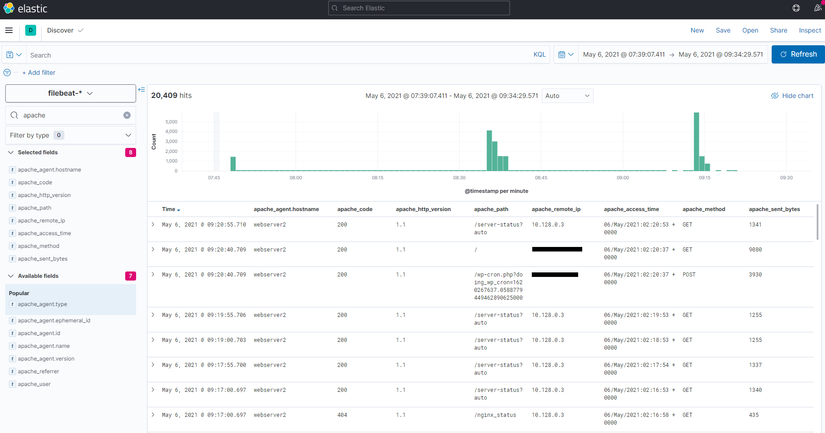
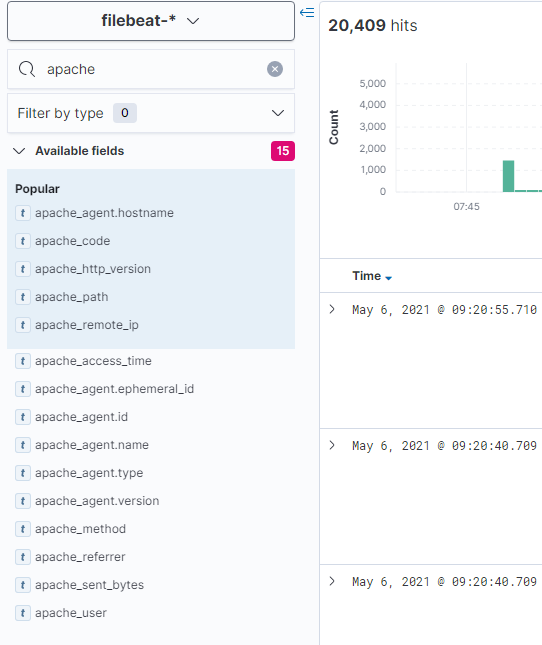 Từ đó là sẽ chọn lọc và hiển thị ra những thông tin cần thiết và dễ dàng mô hình hóa hơn.
Từ đó là sẽ chọn lọc và hiển thị ra những thông tin cần thiết và dễ dàng mô hình hóa hơn.
Kết
Mình là newbie nên chắc chắn sẽ có thiếu sót và sai, nếu có đóng góp hãy comment cho mình biết. Hy vọng bài viết này giúp cho bạn có thêm 1 chút kiến thức. Have a nice day!