Như đã hứa ở blog trước, bài viết tiếp theo của mình hôm nay là về Image Captioning (hoặc Automated image annotation), bài toán gán nhãn mô tả cho ảnh.
Đại khái là, ta có một cái ảnh, và ta cần sinh mô tả cho nó. Trông như thế này này:
 Hình 1
Hình 1
Trước khi bắt tay làm gì đó, mình thường nhìn vào ứng dụng của nó trước. Có thể thấy thay ngay hai ứng dụng lớn.
- Sinh mô tả cho ảnh. Số lượng ảnh đang ngày càng khổng lồ và việc gán nhãn thủ công sẽ rất tiêu tốn. Hãy để AI gán nhãn dùm.
- Các ứng dụng trong việc hỗ trợ người khiếm thị. Đúng vậy.
Ngoài ra, các ứng dụng của Image Captioning đối với mình hiện tại vẫn chưa rõ ràng lắm. Tuy nhiên, mình nghĩ đây lại là một bài tập rất hay để ôn tập kiến thức. Chi tiết việc ôn tập thế nào sẽ được thể hiện trong bài.
Let's go !! 
Kiến thức cần có: RNN, CNN. Mọi người nếu quên mất RNN có thể xem lại bài viết của mình trước đó Recurrent Neural Network: Từ RNN đến LSTM :vv (time for PR)
1. Image Captioning
Ý tưởng cơ bản
Vấn đề đầu tiên của bài toán này là, bài toán này có tận 2 nguồn dữ liệu đầu vào lúc huấn luyện. Thứ nhất là ảnh, thứ hai là caption của ảnh.
Với việc đầu vào của chúng ta là một cái ảnh, ta có thể nghĩ ngay đến việc dùng CNN để trích xuất ra những đặc trưng của ảnh. Đối với đầu vào là một câu văn bản, ta lại thường nghĩ đến dùng RNN thường thấy để xử lí chuỗi.
Vậy câu hỏi mà mình đặt ra ở đây là, làm sao để kết hợp thông tin của hai nguồn dữ liệu trên. Mình nên xây dựng một mạng nhận cả ảnh và caption vào một lúc, hay nên xử lí từng phần riêng biệt, xử lí ảnh riêng, xử lý caption riêng, rồi concat kết quả lại. Nhưng xử lý ảnh và caption cùng lúc hẳn sẽ cung cấp thêm thông tin cho nhau. Vậy lại phát sinh thêm câu hỏi khác, nên dùng cả ảnh để bổ trợ cho mỗi step, hay nên chia ảnh ra thành các step để fig với độ dài của caption. Liệu như thế có thể lấy hết thông tin của ảnh. Rốt cuộc làm như thế nào mới là tốt. Rất may, mình đã tìm được một bài báo chỉ rõ vấn đề này.
Bạn có thể đọc đầy đủ bài báo ở đây: Where to put the Image in an Image Caption Generator
Phần dưới đây mình sẽ tóm tắt lại các ý chính của bài báo.
Về cơ bản, như đã nói ở trên, có 2 cách cơ bản để input cho image captioning: Injection Architecture và Merging Architecture. Không có gì rõ hơn thông qua một cái ảnh:

- Injection Architecture: input sẽ là hỗn hợp dữ liệu của cả ảnh và caption, hay nói cách khác, tại mỗi step của RNN đều sẽ bị ảnh hưởng bởi dữ liệu ảnh. Câu hỏi đặt ra là, liệu RNN đủ tốt để thu thông tin của ảnh,
- Merging Architecture: xử lý riêng rồi merge thông tin lại.
Trong đó, Injection Architecture có 3 loại chính:
- init-inject: thông thường, đầu vào của hidden state đầu tiên sẽ được khởi tạo là ma trận 0. Bây giờ ta thay ma trận đó bằng image.
- pre-inject: ảnh được xem như 1 từ đầu vào, có ý nghĩ tương tự như các từ khác trong câu token.
- par-inject: mỗi đều là sự tổng hợp của cả ảnh và từ.
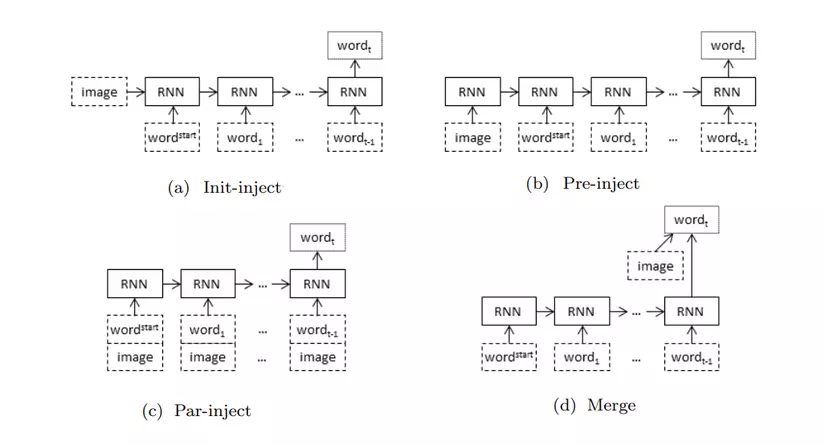
Đương nhiên, hoàn toàn có thể kết hợp các kiến trúc trên lại. Trong phần implement code hôm nay, mình sẽ sử dụng Merge Architecture.
Trong bài báo, Table 4,5,6 so sánh kết quả của 4 kiến trúc trên, dựa theo các yếu tố đánh giá như chất lượng captions, độ đa dạng captions.
Tiếp theo đây mình xin giới thiệu một cách đánh giá đơn giản cho mô hình.
Đánh giá mô hình - BLEU score
BLEU socre định nghĩa thế nào là 1 mô tả tốt cho ảnh? Nó thể hiện trong hai yêu tố:
- Adequacy: mô tả đầy đủ thông tin trong ảnh
- Fluency: đúng ngữ pháp, cấu trúc câu.
Hầu hết từ trước đến nay, mình ko mấy để ý đến metric đánh giá, các metric thường thấy như accuracuy, recision, recall, F1-score. Nhưng rõ ràng là rất khó để đánh giá tương tự với mô hình image captioning. Bởi vì nhìn vào thực tế, từ một bức ảnh có thể sinh ra rất nhiều cách mô tả khác nhau như ví dụ ở hình 1. Việc so khớp 1-1 giữa label và predict sẽ không đánh giá đúng.
Việc đánh giá xem caption được predict ra có bao nhiêu phần giống với tập các label captions, lại tương tự như việc đánh giá độ chính xác của một Machine Translation. Bởi vậy, BLEU score được dùng.
BLEU score (viết tắt của Bilingual Evaluation Understudy) được giới thiệu trong paper BLEU: a Method for Automatic Evaluation of Machine Translation) . BLEU được thiết kế để sử dụng trong dịch máy (Machine Translation), đồng thời, phép đo này cũng được sử dụng trong các nhiệm vụ như tóm tắt văn bản, nhận dạng giọng nói, sinh nhãn ảnh (image captioning). Bên cạnh đó phép đo này cũng sử dụng để đánh giá chất lượng bản dịch của con người.
BLEU đánh giá một câu thông qua so khớp giữa câu đó và câu mẫu. Điểm được cho nằm trong khoảng 0 (sai hoàn toàn) đến 1 (khớp hoàn toàn).
Cách tính của BLEU là đếm số n-gram khớp nhau giữa câu mẫu (R) và câu được đánh giá (C) sau đó chia cho số token của C. Việc chọn n phụ thuộc vào ngôn ngữ, nhiệm vụ và mục tiêu cụ thể. Đơn giản nhất là unigram là n-gram chứa 1 token (n=1), bigram (n=2), trigram (n=3). Một cách trực quan, n càng lớn, câu văn càng mượt.
(mình xin phép sử dụng từ candidate (ứng với caption máy sinh ra) và preference (ứng với label captions, ví dụ dataset Flickr mỗi ảnh có 5 captions đi kèm) để đồng nhất với cách dùng từ của các tài liệu)
Vấn đề thứ nhất:
Ví dụ:
- candidate : the the the the the the the (len = 7)
- preference 1: the cat is on the mat (len = 6)
- preference 2: these is a cat on the mat (len = 7)
Theo cách tính thông thường, các từ trong candidate (the) đều xuất hiện trong preference, tức là điểm chính xác = = 1 --> khớp hoàn toàn. (trong đó m là số n-grams khớp, là số token của candidate). Cách tính này rõ ràng có vấn đề vì candidate trên rất tệ và không mang ý nghĩa nào cả. Để giải quyết vấn đề này, BLEU sử dụng Count Clip.
Cách tính Count Clip như sau:
- Step1: tính Count = số lần khớp lớn nhất giữa n-grams candidate và preference. Trong ví dụ trên, Count = 7 với n = 1 (cả 7 từ của candidate đều xuất hiện trong preference).
- Step 2: Tính Ref = số lần xuất hiện của n-grams candidate trong preference. Ở đây chúng ta có có 2 preference, tương ứng tính ra Ref1 = 2, Ref2 = 2.
- Step 3: Max Ref Count = max ( Ref1, Ref2... Refm) nếu có m preference.
- Step 4: . Trong ví dụ trên Count clip = min (2, 7) = 2.
- Step 5: cộng tất cả Count clips của các từ trong candidate lại.
Vậy điểm bây giờ = .
Vấn đề tiếp theo: Ta thấy cách tính trên có lợi hơn với n bé (dịch tốt các cụm ngắn). Vậy nên BLEU score sử dụng thêm một chế độ phạt BP.
Trong đó , và lần lượt là số token trong preference và candidate.
Và cuối cùng, ta được công thức BLUE score.
Trong đó là số n-grams ta đã dùng. Ví dụ ta dùng cả unigram, bigram và trigram, thì ,
Như vậy, đó là một trong các cách đánh giá thường dùng của bài toán Image Captioning.
Bạn đọc có thể tham khảo thêm tại bài blog sau, khá chi tiết và ví dụ dễ hiểu : BLEU — Bilingual Evaluation Understudy.
2. Implement code using keras
Bạn có thể xem file notebook đầy đủ tại repo Github. Phần bài sau đây là giải thích code.
1. Chuẩn bị dữ liệu.
Dữ liệu thường được sử dụng có thể là bộ Flickr 8k, Flickr 30k hoặc bộ dữ liệu MS COCO. Ở đây mình sử dụng dữ liệu Flickr 8k được tải trực tiếp từ kaggle. Cách tải các bạn có thể xem trong file notebook.
Dữ liệu bao gồm một bộ 8000 ảnh và một file captions.txt. Mỗi ảnh sẽ có 5 captions làm nhãn. Cấu trúc file như sau:
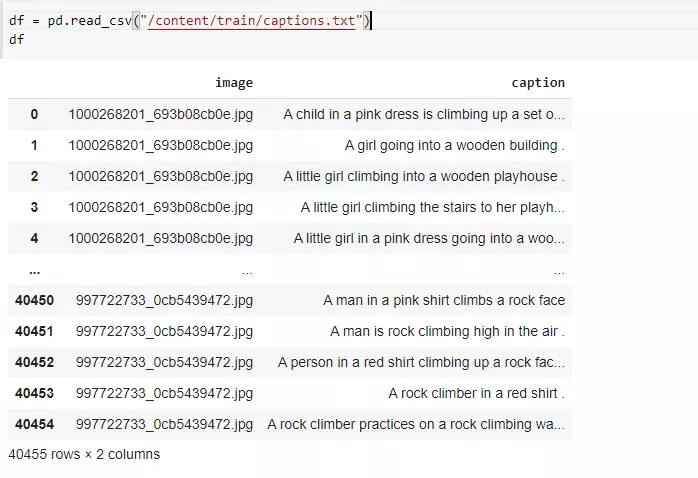
Image size của data này là (500,375,3)
Ví dụ về 1 ảnh và 5 captions của nó:
n = 17
img = Image.open(image_path + df['image'][5*n])
plt.figure(figsize=(7, 7))
plt.imshow(img)
print(df['caption'][5*n:5*n+5])

Tiếp theo ta có 2 công việc:
- Xử lý word
- Xỷ lý ảnh
2. Embedding word
Đầu tiên, chúng ta cần xử lý các captions (dữ liệu text). Thực hiện các thao tác làm sạc dữ liệu cơ bản. Ở đây, mình sẽ loại bỏ tất cả các dấu câu và các từ có chứa chữ số (từ bị lỗi).
import re
def caption_preprocessing(text, remove_digits=True): # removw punctuation pattern=r'[^a-zA-z0-9\s]' text=re.sub(pattern,'',text) # tokenize text=text.split() # convert to lower case text = [word.lower() for word in text] # remove tokens with numbers in them text = [word for word in text if word.isalpha()] # concat string text = ' '.join(text) # insert 'startseq', 'endseq' text = 'startseq ' + text + ' endseq' return text
Kết quả:
print(caption_preprocessing('chao .. ban $ hello980 it\'s a table.#'))
Out: startseq chao ban its a table endseq
Tiếp theo mình đếm số lượng từ trong toàn bộ các captions để quyết định vocab_size. Đồng thời tìm ra độ dài captions dài nhất (max_length) . Đây cũng chính là độ dài hidden state của mạng RNN chúng ta xây dựng sau này.
Đồng thời để giảm vocab size, mình chỉ lấy các từ xuất hiện trên 10 lần. Tại sao lại là 10? Thực ra cũng chỉ là một hype-parameter và các bạn có thể thử bằng 5 với 15 xem ảnh hưởng kết quả thế nào. Ở đây mình xin phép chọn 10.
word_counts = {} # a dict : { word : number of appearances}
max_length = 0
for text in df['caption']: words = text.split() max_length = len(words) if (max_length < len(words)) else max_length for w in words: try: word_counts[w] +=1 except: word_counts[w] = 1
print(len(word_counts)) # Out : 8777
print(max_length) # Out: 34 # Chỉ lấy các từ xuất hiện trên 10 lần
word_count_threshold = 10
vocab = [w for w in word_counts if word_counts[w] >= word_count_threshold]
print('After preprocessed %d -> %d' % (len(word_counts), len(vocab)))
# Out : After preprocessed: 8777 -> 1952
Đồng thời, như thường lệ, mình cũng tạo hai ma trận word to index và index to word để tiện sử dụng sau này.
i2w = {}
w2i = {} id = 1
for w in vocab: w2i[w] = id i2w[id] = w id += 1 print(len(i2w), len(w2i))
# Out : 1952 1852
Glove
Mình sở dụng Glove để embedding word. Sau khi tải Glove từ trang chủ về, ta có 4 file:
! wget https://nlp.stanford.edu/data/glove.6B.zip
! mkdir glove
! unzip glove.6B.zip -d glove
Out:
Archive: glove.6B.zip inflating: glove/glove.6B.50d.txt inflating: glove/glove.6B.100d.txt inflating: glove/glove.6B.200d.txt inflating: glove/glove.6B.300d.txt Nếu bạn đọc chưa từng có kiến thức về embedding word thì mình nghĩ mọi người có thể tìm kiếm các bài đọc về Embdding word để dễ hiểu hơn. Ở đây mình xin phép tóm tắt một số ý:
GloVe (viết tắt global vectors) cung cấp 4 file chứa các vectơ từ được huấn luyện trên các bộ dữ liệu web khác nhau (đều cực kỳ đồ sộ). Chúng ta sẽ sử dụng “Wikipedia 2014 + Gigaword 5”, đây là file nhỏ nhất (“ glove.6B.zip”) có dung lượng 822 MB. GloVe được huấn luyện trên một kho ngữ liệu chứa 6 tỷ từ trong tập từ vựng chứa 400 nghìn từ khác nhau.
Ở đây mình chọn sử dụng file glove/glove.6B.200d.txt, nghĩa là bây giờ 1 từ của mình sẽ được biểu diễn bằng một vector có chiều (200,). Bạn có thể thấy rõ hơn trong file notebook.
embedding_dim = 200
vocab_size = len(vocab) + 1 # thêm 1 padding (1953)
Mình sẽ xây dựng embedding matrix với số chiều = (vocab_size, embedding_dim)
embedding_matrix = np.zeros((vocab_size, embedding_dim)) for word, i in w2i.items(): embedding_vector = embeddings_index.get(word) if embedding_vector is not None: # Words not found in the embedding index will be all zeros embedding_matrix[i] = embedding_vector
print(embedding_matrix.shape)
Out: (1953, 200)
Đồng thời vì thời gian embedding cũng kha khá nên mình khuyên các bạn nên lưu lại vào file pickle. Chi tiết cách lưu trong file notebook.
3. Transfer learning using Inception v3
Nếu bạn chưa biết về transfer learning, có thể lướt nhanh qua bài viết này của anh Tuan Nguyen.
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras.models import Model
model = InceptionV3()
# Tạo model mới, bỏ layer cuối từ inception v3
model_new = Model(model.input, model.layers[-2].output)
model_new.input_shape
Out: (None, 299, 299, 3)
Như trên, ta thấy đầu vào của inception v3 là ảnh 299 x 299. Dataset của chúng ta là ảnh 500 x 375, nên cần resize lại ảnh.
from keras.applications.inception_v3 import preprocess_input
# Image embedding thành vector (2048, )
def encode(image): # Convert all the images to size 299x299 as expected by the inception v3 model img = np.resize(image, (299, 299, 3 )) # Add one more dimension img = np.expand_dims(img, axis=0) # preprocess the images using preprocess_input() from inception module img = preprocess_input(img) feature_vec = model_new.predict(img) # Get the encoding vector for the image feature_vec = np.reshape(feature_vec, feature_vec.shape[1]) # reshape from (1, 2048) to (2048, ) return feature_vec
# Gọi hàm encode với các ảnh trong traning set
start = time()
encoding_image = {}
for id, img in images.items(): encoding_image[id] = encode(img)
print("Time taken in seconds =", time()-start)
Out: Time taken in seconds = 478.9260160923004
4. Huấn luyện
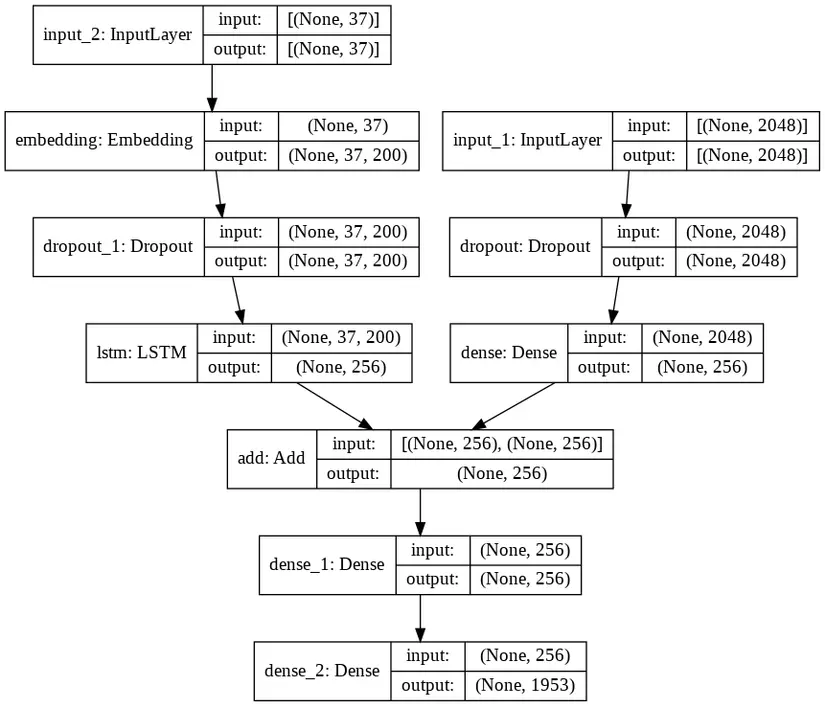
Như đã giới thiệu ở phần 1, lần này mình sử dụng merge architure, xử lý ảnh và image riêng và add kết quả lại ở cuối. Model mình đã sử dụng ở hình dưới.
Như đã nói, chúng ta có 2 input đầu vào, nên phần dữ liệu truyền vào của chúng ta có dạng [X_image, X_caption] và Y.
Sau khi dùng một mạng RNN (LSTM) để xử lý captions, mình cộng các kết quả lại để đưa ra output.
inputs1 = Input(shape=(2048,))
fe1 = Dropout(0.5)(inputs1)
fe2 = Dense(256, activation='relu')(fe1) # max_length = 35, vocab_size = 2005, embedding_dim = 200
inputs2 = Input(shape=(max_length,))
se1 = Embedding(vocab_size, embedding_dim, mask_zero=True)(inputs2)
se2 = Dropout(0.5)(se1)
se3 = LSTM(256)(se2) decoder1 = add([fe2, se3])
decoder2 = Dense(256, activation='relu')(decoder1)
outputs = Dense(vocab_size, activation='softmax')(decoder2) model = Model(inputs=[inputs1, inputs2], outputs=outputs)
# Layer 2 dùng GLOVE Model nên set weight thẳng và không cần train
model.layers[2].set_weights([embedding_matrix])
model.layers[2].trainable = False
Để truyền dữ liệu vào huấn luyện, dữ liệu captions sẽ được xử lý như sau (kiếm mãi mới ra cái ảnh đúng ý  )
)
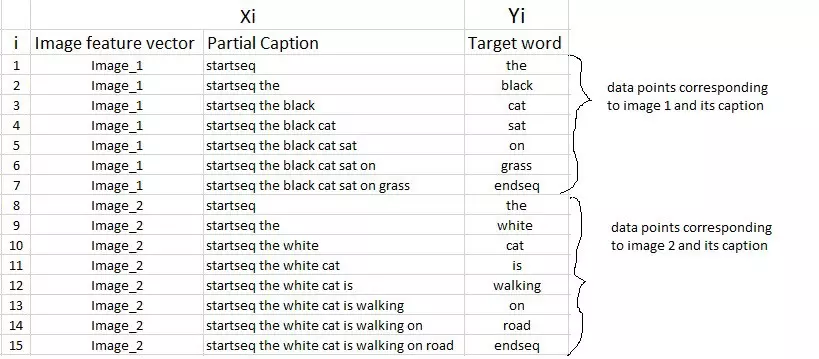 Phần này được thực hiện trong hàm data_generator của mình.
Phần này được thực hiện trong hàm data_generator của mình.
def data_generator(captions, images, w2i, max_length, batch_size): X_image, X_cap, y = [], [], [] n = 0 while 1: for id, caps in captions.items(): n += 1 image = images[id] for cap in caps: # encode the sequence seq = [w2i[word] for word in cap.split(' ') if word in w2i] for i in range(1, len(seq)): # split into input and output pair in_seq, out_seq = seq[:i], seq[i] # pad input sequence in_seq = pad_sequences([in_seq], maxlen=max_length)[0] # encode output sequence out_seq = to_categorical([out_seq], num_classes=vocab_size)[0] X_image.append(image) X_cap.append(in_seq) y.append(out_seq) if n == batch_size: yield ([np.array(X_image), np.array(X_cap)], np.array(y)) X_image, X_cap, y = [], [], [] n = 0
Huấn luyện:
generator = data_generator(captions=captions, images=train_features, w2i=w2i, max_length=max_length, batch_size=batch_size)
model.fit(generator, epochs=epochs, steps_per_epoch=steps, verbose=1, callbacks=[cp_callback])
Kết quả:
Epoch 1/5
8091/8091 [==============================] - 1055s 130ms/step - loss: 3.3241
Epoch 2/5
8091/8091 [==============================] - 1038s 128ms/step - loss: 2.9998
Epoch 3/5
8091/8091 [==============================] - 1041s 129ms/step - loss: 2.8467
Epoch 4/5
8091/8091 [==============================] - 1039s 128ms/step - loss: 2.7386
Epoch 5/5
8091/8091 [==============================] - 1034s 128ms/step - loss: 2.6541
5. Inference
Ở phần Inference, mình sử dụng greedy search cho đơn giản. Hầu hết source code sử dụng Beam search để chính xác hơn.
- Greedy search: ta khởi đầu với chuỗi rỗng. Tại mỗi bước, ta thực hiện tìm kiếm toàn bộ trên không gian của bước đó và chỉ lấy duy nhất 1 kết quả có điểm số cao nhất và bỏ qua tất cả các kết quả khác. Sang bước tiếp theo, ta chỉ mở rộng tìm kiếm từ kết quả duy nhất trước đó.
- Beam search cũng khởi đầu với chuỗi rỗng. Tại mỗi bước, ta thực hiện tìm kiếm toàn bộ trên không gian của bước đó và lấy ra k kết quả có điểm số cao nhất thay vì chỉ lấy 1 kết quả cao nhất.
def predict(photo): in_text = 'startseq' for i in range(max_length): sequence = [w2i[w] for w in in_text.split() if w in w2i] sequence = pad_sequences([sequence], maxlen=max_length) yhat = model_new.predict([photo,sequence], verbose=0) yhat = np.argmax(yhat) word = i2w[yhat] in_text += ' ' + word if word == 'endseq': break final = in_text.split() final = final[1:-1] final = ' '.join(final) return final
Và cuối cùng ta được kết quả như sau: 
pic = list(train_features.keys())[50]
image = train_features[pic].reshape((1,2048))
img = Image.open(image_path + pic)
print(df['caption'][df['image'] == pic])
plt.imshow(img)
plt.show()
predict = inference(image)
print(predict)

Kết
Cảm ơn mọi người đã theo dõi bài viết. Model này còn đơn giản và độ chín xác chưa được cao. Trong bài viết tiếp theo của series A Guide to Image Captioning, mình sẽ trình bày các kiến trúc phức tạp hơn cho bài toán Image này.
Đón chờ bài viết sau của mình nhé.
Cảm ơn mọi người. 