Vấn đề không tự sinh ra cũng không tự mất đi, nó chỉ chuyển từ dạng này sang dạng khác, hoặc từ chỗ này sang chỗ khác.
Đây là định luật bảo toàn vấn đề áp dụng trong thế giới phần mềm do chính mình phát biểu =))). Bạn có vấn đề, bạn tìm cách giải quyết nó, và vấn đề khác lại xuất hiện bởi vì giải pháp của bạn cho vấn đề phía trước, và bạn lại tìm cách giải quyết nó, và lại phát sinh vấn đề...
Đó là cách mọi thứ hoạt động. Chúng ta không thể làm gì khác ngoài việc tiếp tục tìm cách giải quyết vấn đề, và lại sẽ gặp những vấn đề khác ở level cao hơn =))) Nhưng mà thôi, cuộc sống mà. Biết đâu con đường dài vô tận khắc phục vấn đề đó lại có gì hay ho. Hãy dũng cảm tiến bước nhé.

First things first
Nhưng mà trước khi các bạn đọc tiếp thì vấn đề đầu tiên tất nhiên là phải hỏi thăm tác giả (cũng chính là mình - Minh Monmen) một chút xem dạo này làm ăn thế nào, sao mà mất hút lâu thế.
Chả là thời gian vừa rồi lại là 1 khoảng thời gian mình buộc phải thay đổi để có thể tiếp tục đi theo niềm đam mê làm sản phẩm của bản thân. Mong ước được gần với user, được tự do làm cái tốt cho sản phẩm mà không phải mất quá nhiều thời gian cho lớp trung gian đã thôi thúc mình bước tiếp, tìm kiếm những vị trí không chỉ là một công việc nuôi sống bản thân mà còn nuôi sống niềm đam mê với solution.
Rất may mắn là có vẻ mình đã tìm thấy. Mình đã bị cuốn vào 30 ngày hăng say và quay cuồng với nhiều thử thách cả về mặt sản phẩm, công nghệ, nhân sự, quản lý... cũng tốn 1 mớ thời gian để làm mọi thứ tốt nhất trong khả năng nên giờ mới có thể có chút thời gian để tiếp tục chuỗi bài viết còn dang dở. Và chúng ta lại ở đây, trong bài viết thứ 3 của series Caching đại pháp kể về những kinh nghiệm của mình khi implement hệ thống caching.
- Caching đại pháp 1: Nấc thang lên level của developer
- Caching đại pháp 2: Cache thế nào cho hợp lý
- Caching đại pháp 3: Vấn đề và cách giải quyết <~ YOU ARE HERE
Chắc đây sẽ tạm thời là bài viết cuối của series nói về caching này (cho tới khi mình nghĩ ra được chủ đề tiếp theo). Caching là 1 thế giới rộng lớn trải dài từ level junior cho tới level chef (C-level ấy), do đó mình cảm thấy mình vẫn chỉ mới cọ xát được có 1 tí xíu cái bề nổi của nó thôi và cũng chưa có gì nhiều để chia sẻ được với các bạn. Trong bài viết này các bạn hãy cùng mình tìm hiểu xem việc sử dụng giải pháp thần thánh caching trong hệ thống của mình đã phát sinh những vấn đề gì và nó có lớn không nhé.
Vấn đề đầu tiên: Cache ôi thiu (stale cache)
Nếu nhắc tới caching, thì chắc chắn vấn đề đầu tiên phải xem xét chính là tính đúng đắn của dữ liệu rồi. Bởi vì khi bạn đã chấp nhận sử dụng cache thì nghĩa là bạn đã chấp nhận sử dụng lại 1 kết quả cũ và rất có thể kết quả đó sẽ không đúng đắn tại những thời điểm khác nhau. Cũng bởi vì đây là vấn đề lớn nhất và là tính chất của caching mà bạn phải chấp nhận, do đó nó cũng sinh ra tương đối nhiều tình huống dở khóc dở cười.
Quay trở lại với tấm hình trong bài viết đầu tiên của mình:
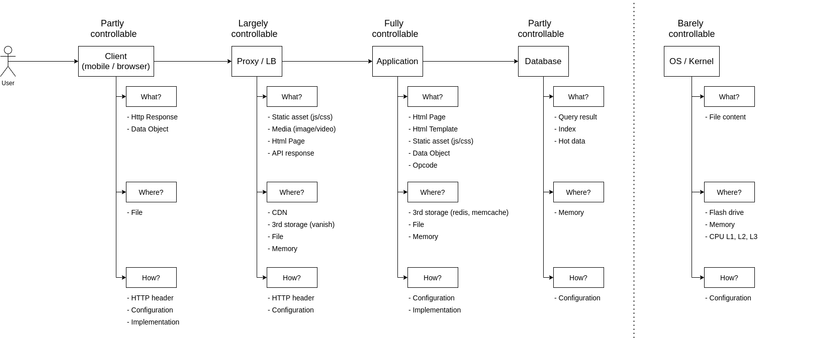
Ở bài viết đầu tiên thì mình chỉ đề cập qua loa tới khả năng kiểm soát cache của các bạn. Và đây là lý do tại sao khả năng đó của các bạn ở các level cache khác nhau là khác nhau. Mình sẽ chỉ đề cập tới 2 vị trí mà mọi người hay gặp vấn đề nhất ở đây thôi nhé.
Stale client cache (cụ thể là browser cache)
Well, đây chắc chắn là loại cache được mệnh danh là kẻ phá hoại lòng tin trong những năm đầu làm web của chúng ta. Cái thời mà còn chưa biết tới react, angular hay vuejs mà chỉ biết jquery, html, js thuần,... thì caching ở browser là thứ chúng ta thường ít để ý (mà thật ra là giờ cũng ít để ý thôi, nhưng framework nó take care hộ nên ít gặp lỗi).
Loại cache này có thể khiến cho user chém nhau với CSKH (chăm sóc khách hàng), tester chém nhau với dev, PM chém nhau với nhân viên =)) bởi vì mỗi người sẽ nhìn thấy trang web ở 1 phiên bản khác nhau:
- Bạn thêm tính năng mới, nhưng người khác vẫn chỉ thấy như cũ và nghi ngờ bạn xạo.
- Bạn gặp lỗi js làm trang trắng tinh, bạn đẩy fix, nhưng khách hàng vẫn kêu như cháy đồi và sếp thì phát rồ lên.
Nếu bạn đã từng phải dành cả thanh xuân với đội CSKH và nói những câu đại loại như:
- Hướng dẫn user clear cache browser đi rồi vào lại
- Bảo user ấn Ctrl + F5
- Thử tab ẩn danh xem
Thì chắc chắn là giờ các bạn cũng đã già (như mình =))). Chung quy lại cũng chỉ vì 1 tính năng vô cùng sáng giá của browser đó là Cache hết mọi thứ nhận được trừ khi được bảo KHÔNG. Hãy cùng xem request của 1 trang web khá cũ mà mình tìm được trên google để cùng trở lại tuổi thơ dữ dội nào.
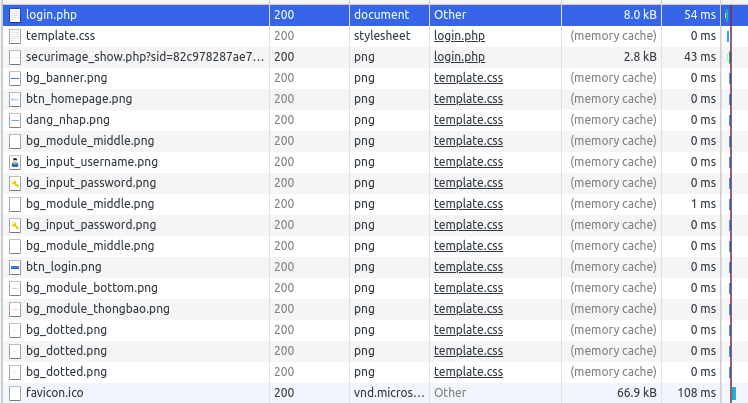
Nhưng các bạn thấy, css và image là những asset được browser cache in-memory (tức là không thèm gọi lại server tý nào). Thử nhìn vào response header khi mà file đó được load nhé:
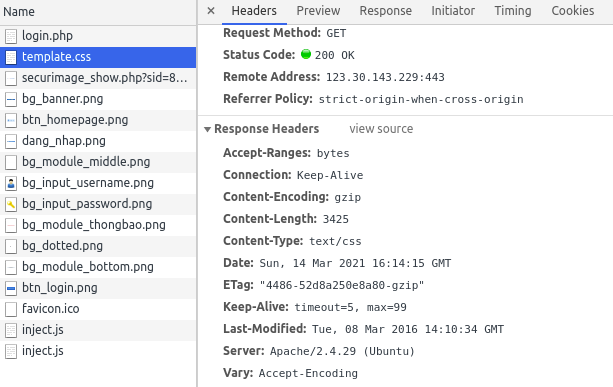
Nếu mình có sửa nội dung file css này trên server như sửa toàn bộ theme của trang thì user cũng vẫn sẽ nhìn thấy giao diện cũ do browser đã cache nội dung file trong memory rồi.
Như các bạn đã biết (hoặc sắp biết), thì 1 request HTTP sẽ được browser consider cache dựa trên cơ chế của header Last-Modified và Expires (với HTTP/1.0) và header Cache-Control, Vary,... (với HTTP/1.1). Tuy nhiên với những ứng dụng kiểu cũ mà chúng ta tự code html, tự code js, css và setup 1 cái web server đơn giản thì thường không set những header này. Và browser siêu thông minh của chúng ta sẽ tự động cache những asset trên cho tới khi chúng ta về hưu thì thôi (just kidding) =))).
Trust me, điều cuối cùng bạn muốn làm chính là thốt lên bảo khách hàng clear browser cache. Nó thể hiện sự bất lực trong việc quản lý sản phẩm của chính bạn và sẽ tốn của bạn một chuỗi ngày ác mộng để giải quyết với từng khách hàng.
Vậy phải làm sao để khắc phục vấn đề này?
Cache ở client (browser) là loại cache mà chúng ta có 1 phần quyền kiểm soát thông qua việc set HTTP header và tổ chức url cho phù hợp. Do đó hãy tận dụng chúng cho tốt. Sau đây là 1 số giải pháp để luôn giữ cho cache ở client của chúng ta tươi mới:
- Config HTTP header phục vụ cache trên web server: Dành thời gian tìm hiểu về cách hoạt động của các loại header HTTP liên quan tới caching và cấu hình nó cho đúng. Ngoài ra có thể sử dụng thêm các loại meta tag trong html.
- Invalidate asset cache bằng URL: Invalidate asset cũ thông qua việc thay đổi url (như thêm version/hash vào tên file hoặc query trong url tới file)
Some best practices:
- Set cache-control với thời hạn dài + thêm version/hash vào filename với các file asset: js, css, image,... để đảm bảo 1 url được trình duyệt cache trong thời gian dài. Khi có nhu cầu thay đổi thì chỉ cần đổi filename theo version/hash mới.
- Set
cache-control: no-cachevà sử dụngetagvới HTML request (vì không thể thay đổi url của html) để browser luôn validate lại với server về nội dung này.
TIPs: Tất cả những thứ trên không chỉ có tác dụng với browser mà còn có cả tác dụng với lớp proxy/CDN cache. Do đó đừng bỏ qua hay chỉ set default mà hãy implement 1 cách cẩn thận và chuẩn xác nhé.
Stale data object cache
Nếu như stale client cache phía trên thường dẫn tới kết cục giao diện trang của chúng ta bị sai hoặc lỗi thì việc data object ở application bị stale còn làm chúng ta gặp những câu chuyện dở khóc dở cười hơn khi mà dữ liệu trên trang sẽ bị sai lệch.
Chắc chắn khi đọc tới đây thì các bạn cũng sẽ nhớ đến câu nói nổi tiếng mà mình đã trích dẫn trong bài viết trước:
There are only two hard things in Computer Science: cache invalidation and naming things. - Phil Karlton
Vâng, cache invalidation chính là thứ mà chúng ta đang phải giải quyết đây. Các bạn sẽ trả lời ra sao nếu người dùng phàn nàn những điều sau:
- Tại sao tôi vừa đăng bài nhưng không thấy đâu?
- Tôi lỡ tay đăng hình gợi cảm và xóa rồi sao người ta vẫn nhìn thấy?
- Tôi blablo...
Hãy quay trở lại với những câu lệnh hết sức quen thuộc mà chúng ta đã thấy trong bài viết trước (nhưng thể hiện bằng nodejs + mongoose):
const articleCache = new NodeCache(); async function getArticleById(id) { const cacheKey = `article:${id}`; let article; // Check if cache has data if ( articleCache.has(cacheKey) ) { article = articleCache.get(cacheKey); } else { // Populatearticle data from database article = await Article.findById(id); // Putarticle data to cache and set TTL to 60s articleCache.set(cacheKey, article, 60); } return article;
}
Một lần nữa, cache-aside sẽ là chiến lược cache các bạn gặp nhiều nhất, hoặc các bạn đã dùng rồi mà không biết tên nó chẳng hạn. Với việc đơn giản là set cho data của bạn 1 khoảng thời gian gọi là Time To Live (TTL) (mà trong ví dụ trên là 60s), các bạn chấp nhận rằng trong 60s thì dù cho data có thay đổi trong database thì các client của chúng ta vẫn chỉ nhận được data cũ từ cache. Điều này có thể chấp nhận được với những hệ thống rất ít thay đổi (kểu như báo chí, blog, tin tức,...). Các bạn cũng có thể set 1 khoảng thời gian cache dài dài từ vài phút tới cả vài chục phút để phát huy hết hiệu quả của cache.
Tuy nhiên với những hệ thống mà dữ liệu thường xuyên thay đổi thì việc cache trong 1 khoảng thời gian dài sẽ làm dữ liệu trên trang bị cũ và gây nhiều hệ lụy về mặt logic. Nhưng mà set TTL quá nhỏ thì lại không có hiệu quả cache mấy. Lúc này thì các hệ thống invalidate cache chủ động sẽ phát huy tác dụng. Người ta thường hay dùng các cơ chế write-xxx cache như sau:
- Write-around: Application sẽ update data vào DB trước tiên, sau đó cache mới được update. Đây là cách thông dụng nhất và đáp ứng đa số ứng dụng khi chúng ta cần đảm bảo data được lưu trữ chuẩn xác trong DB. Người ta thường sử dụng 1 process phía sau (ví dụ 1 background job) để refresh cache sau khi action write xảy ra.
- Write-through: Application sẽ update cache và DB cùng 1 lúc. Kiểu này làm action write kéo dài hơn write-around nhưng được cái vừa đảm bảo dữ liệu được ghi vào DB vừa đảm bảo data trong cache luôn tươi mới.
- Write-behind: Application sẽ update vào cache trước, sau đó mới update data vào DB. Cách này là cách handle những ứng dụng có lượng write lớn và cho phép rủi ro liên quan tới tính toàn vẹn dữ liệu (kiểu các hệ thống counter, analytic, tracking,...) do data có thể mất mát khi chưa được lưu vào DB. Tuy nhiên đây là loại có action write nhanh nhất.
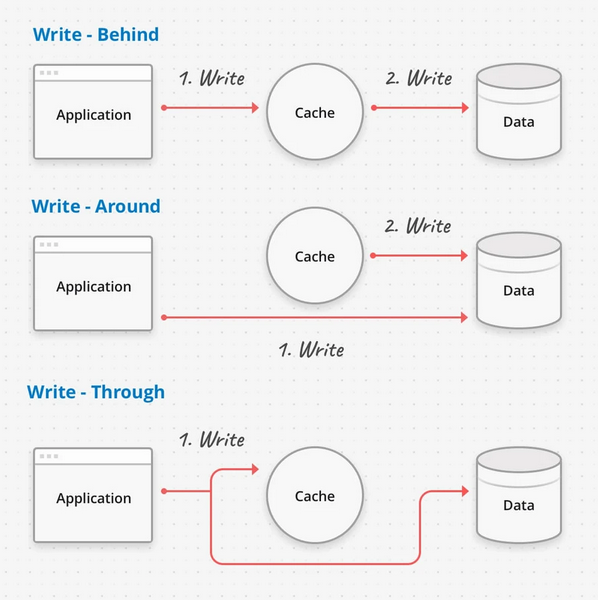
Riêng với thằng write-around là thằng phổ biến nhất thì các bạn có thể implement bằng:
- Trigger background job chủ động nếu action write của bạn chỉ từ 1 nguồn và bạn tích hợp được với thằng write.
- Lắng nghe Change Data Capture (CDC) thông qua binlog (mysql), oplog (mongodb),... nếu data của bạn chỉ đọc 1 nơi nhưng có nhiều nguồn write và không can thiệp được thằng write. Đây là cách hardcore động hẳn xuống việc thay đổi data trong DB, cần thận trọng khi dùng (nhưng cực kỳ hiệu quả).
- Setup cronjob để refresh cache hơi nông dân tý nhưng dùng đúng thì vẫn rất hiệu quả nếu bạn không can thiệp được vào thằng write cũng như chưa đủ điều kiện implement CDC.
Hiện nay 1 xu hướng của các hệ thống high performance là setup cache TTL dài, sau đó sử dụng stream CDC để xử lý invalidate cache khi data có thay đổi. Mình cũng có mô tả chi tiết 1 hệ thống mình đã từng dựng trong bài viết: Bài toán "Super fast API" với Golang và Mongodb
Vấn đề thứ hai: Paginated cache
Ngay từ khi không dùng cache thì việc đảm bảo tính nhất quán giữa các page data cũng đã là vấn đề rồi, vậy mà giờ đây còn thêm cả cache nữa thì vấn đề nó có thể phức tạp đến thế nào? Thật ra paginated cache cũng có thể được xem xét đưa vào vấn đề stale cache ở trên, nhưng mình đã tách nó ra riêng bởi vì chỗ này mình sẽ xử lý theo hướng khác hẳn.
Nếu như trong vấn đề đầu tiên, chúng ta tập trung vào giải quyết tính đúng đắn của dữ liệu, tức là giữ cho dữ liệu của chúng ta luôn tươi mới chứ không ôi thiu, thì khi giải quyết vấn đề thứ 2 này, mình đặt tính nhất quán trong góc nhìn của user lên trước, tức là có thể chấp nhận dữ liệu bị stale, nhưng phải nhất quán.
Nghe hơi học thuật rồi đúng không? Nói nôm na nghĩa là Cơm thiu thì phải ăn kèm thức ăn thiu, chứ không kiểu Cơm thiu ăn với thức ăn ngon. Nếu user đã xem dữ liệu cũ, thì phải cũ cho chót luôn chứ không nửa cũ nửa mới. Đây là 1 vấn đề khá khoai môn, nhất là với các hệ thống có dữ liệu kiểu infinity feed như mạng xã hội như fb, blog như medium,... khi mà trải nghiệm nhất quán của người dùng phải được ưu tiên.
Có rất rất nhiều cách mà các công ty lớn như thế giải quyết bài toán này, một phần bởi vì đặc điểm dữ liệu mỗi hệ thống khác nhau, một phần là do chính cơ chế sinh feed của các công ty cũng khác nhau. Ở đây mình không đưa ra 1 phương pháp best practices nào cả, bởi vì thật sự là cũng không có cách nào giải hết được các trường hợp, và mình cũng chưa tiếp xúc với các hệ thống lớn đó bao giờ. Tuy nhiên mình sẽ cung cấp cho các bạn 1 vài phân tích cơ bản và 1 vài hướng đi để các bạn thử.
Phân tích bài toán
Hãy bắt đầu đi từ đoạn code phân trang mà các bạn hay gặp nhất.
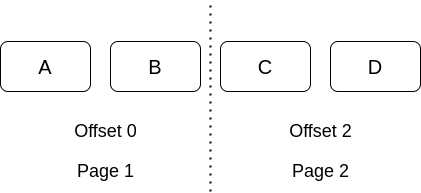
Phân trang bằng limit + offset là 1 trong những kiểu phân trang cổ điển nhất và gần như ai cũng đã từng sử dụng. Mặc dù có rất nhiều bài blog trong vài năm trở lại đây nói là cách phân trang này không tốt, nặng nề, blablo.... nhưng nó vẫn là cách phân trang phổ biến nhất. Để áp dụng cache cho kiểu phân trang này thì chắc nhiều bạn đã sử dụng đoạn code sau:
const articleCache = new NodeCache(); async function getArticles(offset = 0, limit = 2) { const cacheKey = `articles:${offset}:${limit}`; let articles; // Check if cache has data if ( articleCache.has(cacheKey) ) { articles = articleCache.get(cacheKey); } else { // Populatearticle data from database articles = await Article.find() .limit(limit) .skip(offset) .exec() // Putarticle data to cache and set TTL to 60s articleCache.set(cacheKey, articles, 60); } return articles;
}
Ở đây mình sử dụng chính param truyền vào của từng trang để cache. Tuy nhiên dù có sử dụng cache hay không thì vẫn có khả năng xảy ra tình trạng sau:
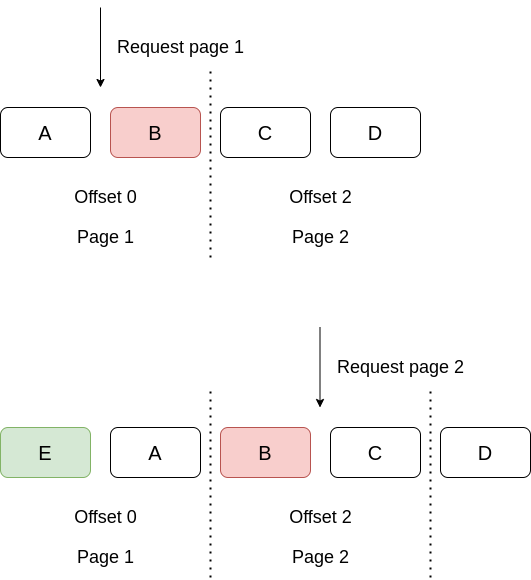
~> Như vậy nếu có 1 item E được thêm vào trang 1 (trong khi user đã request trang 1), vậy thì khi user xem trang tiếp theo, rất có thể toàn bộ các item đã bị dịch xuống dưới và item B sẽ bị duplicate khi xuất hiện trên cả 2 trang.
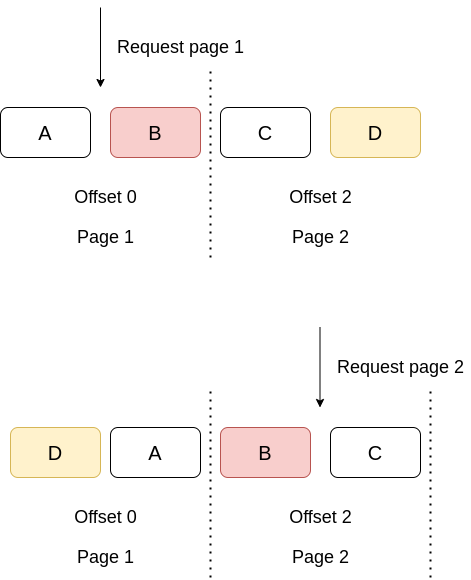
~> Trong trường hợp này, nếu item D được update và đẩy lên trang 1, vậy thì user sẽ không nhìn thấy item D ở trang nào cả, trong khi item B thì lại vẫn bị duplicate.
Có rất nhiều các trường hợp khác liên quan đến thêm sửa xóa, update thứ tự,... cái list này và làm cho nó sai lệch. Vậy ta phải làm sao?
Một vài hướng đi
Bài toán phân trang không phải là bài toán của caching bởi vì kể cả không dùng cache mà dùng trực tiếp DB thì vẫn sẽ gặp. Tuy nhiên caching có thể khiến cho tình hình sai lệch trầm trọng hơn nếu không sử dụng đúng cách. Mình đã từng thử 1 số hướng đi sau:
Đổi cách phân trang dựa theo item cuối cùng
Đây là cách được người ta khuyên dùng với các hệ thống phân trang hiện đại. Tức là việc phân trang sẽ có 1 tiêu chí sort nào đó, và các bạn sử dụng giá trị sort đó ở item cuối cùng làm query cho trang tiếp theo. Ví dụ như minh đổi query trang 2 thành như sau:
articles = await Article.find({_id: {$gt: 'B'}}) .limit(2) .exec()
Lúc này item B cũng sẽ không bị duplicate ở các trang sau nữa.
Điểm cần lưu ý: Cách này chỉ có tác dụng khi việc phân trang của bạn có trường được sort không thay đổi (kiểu sort theo id, created_at,...). Nếu nó thay đổi thì việc duplicate data hay thiếu data vẫn có thể xảy ra.
Lưu lại list id user đã xem
Với cách này, app frontend của bạn khi fetch dữ liệu từng trang sẽ lưu lại 1 danh sách những id mà user đã có. Nếu các page tiếp theo có id đã từng lấy thì sẽ tự động ẩn đi. Đây là cách giải quyết cho trường hợp item B bị duplicate trên các trang khác nhau. Mặc dù nghe nông dân nhưng cũng phát huy tác dụng kha khá. Tuy nhiên mình không khuyến khích sử dụng cách này, vì nó gây gánh nặng cho frontend của bạn và nhiều khi làm cho data trang mới của bạn bị loại bỏ đi rất nhiều item gây lỗi frontend. (ví dụ page có 10 item nhưng khi load tới page 5 thì cả 10 item đều đã từng hiện hữu, nên số item thêm vào là 0)
Hãy coi đây như là biện pháp phòng ngừa cuối cùng chứ đừng lạm dụng. Strip đi 1-2 item thì còn được chứ lớn hơn thì là lỗi của backend rồi.
Gửi lên backend list id user đã xem
1 biến thể khác của việc lưu lại id user đã xem chính là: gửi lên list id đó cho backend, và backend sẽ tự động strip những data đó khỏi kết quả trả về bằng cách lấy thừa data trong từng page. Ví dụ 1 page của mình có 10 item, vậy thì mình sẽ query với limit 13 để có 3 item dự phòng cho việc strip bớt dữ liệu.
Điểm cần lưu ý: well, 1-2 page thì còn làm được, chứ số page mà lớn, list id mà dài là cũng khốn nạn các bạn ạ. 2 phương pháp liên quan tới ID này thường sẽ được áp dụng nếu các bạn đoán trước người dùng sẽ chỉ xem 1-3 page đầu tiên.
Cache lại data tĩnh
Để đảm bảo performance của hệ thống thì mình cũng vẫn phải chia cái data phân trang này thành phần tĩnh và phần động. Trong đó phần tĩnh thường là content, description, title, detail, meta,... của từng item. Thông thường thì việc update dữ liệu chi tiết của 1 item sẽ xảy ra ít, do đó nó được coi là phần tĩnh. Phần động ở đây sẽ thường là thứ tự trong sắp xếp phân trang.
~> Nếu không thể cache được toàn bộ, chí ít hãy cache nội dung của từng item bằng id còn việc sắp xếp thứ tự phân trang (theo id) sẽ cho phép gọi thẳng tới datasource. Phương pháp này phù hợp với những hệ thống kiểu micro-service, khi mà nội dung từng item được quản lý tại 1 service, data feed (cái list item) được quản lý tại 1 service khác.
Điểm cần lưu ý: Việc merge cache item bằng nhiều ids có thể sẽ phức tạp.
Prefetch các page tiếp theo
Ngay khi user request page đầu tiên thì 1 background job sẽ được trigger để xử lý các page tiếp theo (2, 3, 4,...) và cache lại kết quả từng page. Điều này giúp cho trải nghiệm của 1 user trở nên đồng nhất hơn do các bạn đã tạo ra 1 bản chụp (snapshot) lại item trong các page ngay tại thời điểm user request đầu tiên.
Hướng đi này có nhiều cách implement tùy thuộc vào từng hệ thống.
- Nếu view của các user là đồng nhất thì có thể prefetch bằng cronjob, hoặc cache key bằng block time (ví dụ request lúc 10h04 thì làm tròn time thành 10h00 để lấy làm cache key). Tại 1 thời điểm sẽ có thể tồn tại nhiều biến thể của list tùy thuộc vào thời điểm user request page đầu tiên.
- Nếu view của các user là khác nhau (personalize) thì có thể sinh ra 1 cái request_id ngẫu nhiên cho page đầu tiên để làm cache key, sau đó các page sau sử dụng request_id từ page 1 để lấy data trả về. Nếu user refresh toàn bộ trang (get lại page 1) thì sẽ có 1 view list khác với request_id khác (tương tự FB)
Điểm cần lưu ý: Việc tạo ra bao nhiêu page tiếp theo phụ thuộc hoàn toàn vào việc bạn đánh giá user của mình sẽ thường xem bao nhiêu page. Prefetch nhiều page có thể tốn rất nhiều memory mà không bao giờ được dùng tới. Cách này thường được áp dụng kết hợp với cache lại data tĩnh để chỉ prefetch ra 1 list id mà thôi.
Các bạn có thể dùng 1, 2 hoặc kết hợp nhiều phương pháp để dung hòa mối tương quan giữa tính nhất quán và tính tươi mới của dữ liệu. Hãy chọn dựa trên đánh giá cụ thể hệ thống của bản thân. Rất có thểphương pháp này chỉ phù hợp với hệ thống của mình chứ không phù hợp với hệ thống của các bạn.
Vấn đề thứ ba: Thundering herd & Cache stampede
Đây là vấn đề xảy ra với các hệ thống cache on demand mà các bạn sẽ gặp (nếu có điều kiện). Vẫn là đoạn code phía trên thôi:
const articleCache = new NodeCache(); async function getArticleById(id) { const cacheKey = `article:${id}`; let article; // Check if cache has data if ( articleCache.has(cacheKey) ) { article = articleCache.get(cacheKey); } else { // Populatearticle data from database article = await Article.findById(id); // Putarticle data to cache and set TTL to 60s articleCache.set(cacheKey, article, 60); } return article;
}
Mọi chuyện không có gì phải bàn nếu mà request tới hệ thống của các bạn là tuần tự hết cái nọ tới cái kia. Nhưng trớ trêu thay là hệ thống bình thường không như vậy. Rất nhiều request có thể cùng tới 1 lúc. Và hãy tưởng tượng dòng code await Article.findById(id) ở trên phải mất vài giây để chạy. Khi đó request trước chưa kịp cache lại kết quả request sau đã tới, và lại miss, lại gọi DB,...
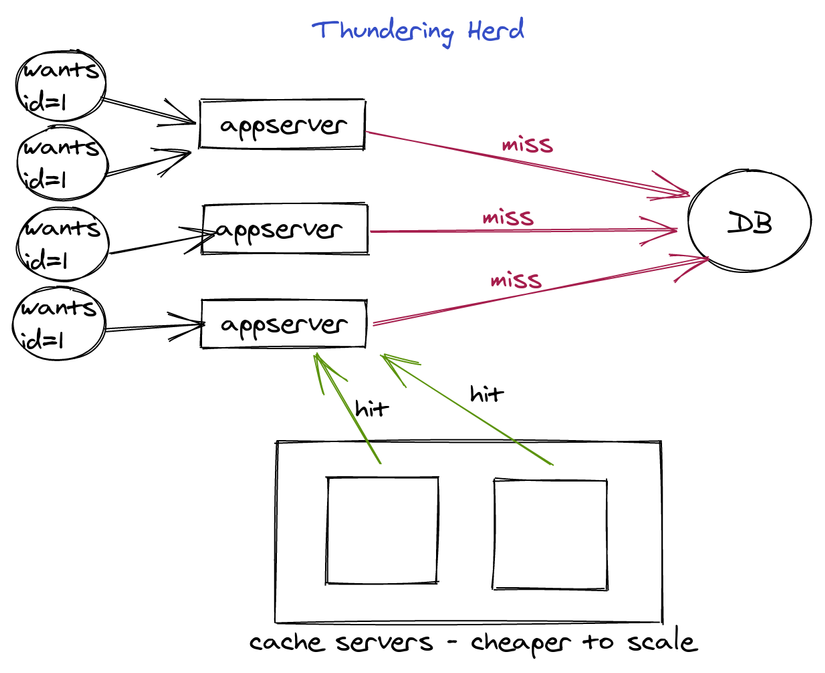
Bọn mình đã dính tình trạng này ngay trong những ngày đầu ra mắt sản phẩm, khi tối ưu lúc đó đơn giản chỉ là thêm 1 lớp cache vào các endpoint chậm y như đoạn code trên chứ chưa có gì cao siêu. Mình nhớ lúc đó bọn mình đã dùng 1 query random để lấy data, và data đó lấy mất 3s. Mặc dù data trả về giống nhau và được cache cho mọi user, tuy nhiên quá nhiều request tới hệ thống đúng cái lúc cache miss đã khiến DB của bọn mình quá tải. Tới lúc đó những người nông dân như bọn mình mới biết tới cái vụ thundering herd này.

Cách xử lý xem ra đơn giản tới mức khó tin, hoặc là bọn mình đã vá víu nó theo cách đơn giản tới khó tin:
- Setup cronjob chạy định kỳ để refresh cache trước khi cache hết hạn (warmup cache). Như vậy thì toàn bộ request từ client sẽ được cache và không xảy ra tình trạng cache miss dẫn tới thundering herd. (Thật ra cách này chỉ work với đúng request đó của bọn mình thôi, vì 1 request dùng cho mọi user và có thể warmup được trước)
Ngoài ra thì thế giới người ta làm nhiều cách cao siêu khác để xử lý vấn đề này. Có thể kể đến vài cái như:
- Cache promise: cache lại lời hứa trả kết quả chứ không cache result. Đây là cách được mấy ông to kiểu FB hay xài.
- Lock/debounce and retry: lock việc populate cache và implement retry khi không claim được lock.
- Random TTL: Implement random TTL giúp hệ thống không bị miss cache đồng loạt (do cache TTL giống nhau giữa các key). Cách này được youtube sử dụng.
Khắc phục với cache kiểu warmup các thứ chỉ là phần ngọn. Nếu có thểhãy tối ưu DB đểchiếc query 3s kia không xảy ra =)))
Vấn đề thứ tư: Cache penetration với empty data
Trường hợp này thì các bạn cũng không hay để ý, vì nó có thể phát sinh từ 1 lỗi code nho nhỏ, hoặc sẽ gặp trong các trường hợp hệ thống bị tấn công. Hãy thử sửa lại đoạn code từ đầu chương trình và xem điều gì có thể xảy ra
const articleCache = new NodeCache(); async function getArticleById(id) { const cacheKey = `article:${id}`; let article = articleCache.get(cacheKey); if (!article) { // Populatearticle data from database article = await Article.findById(id); // Putarticle data to cache and set TTL to 60s articleCache.set(cacheKey, article, 60); } return article;
}
Các bạn hãy lưu ý dòng if (!article). Đây là kiểu code được rất nhiều người trong chúng ta sử dụng (trong đó có cả mình) để check 1 item có dữ liệu hay không. Không may là việc check như này không phân biệt được database không có dữ liệu và cache không có dữ liệu. Nếu user truyền lên 1 id không tồn tại thì tất cả mọi request chứa id đó đều đi trực tiếp vào database.
Điều này có thể gặp trong trường hợp bình thường là item đó bị xóa (và user vẫn còn link). Để khắc phục vấn đề này hãy phân biệt rõ: database không có dữ liệu (data = empty) và cache miss (data = null, undefined,...) trong code và cache cả empty data luôn.
Một tình huống xấu hơn mà mình đã gặp là bị tấn công ddos, attacker sẽ request random id không tồn tại để bypass hệ thống cache của mình dẫn tới DB quá tải. Cái này tương đối khó chống, mình chỉ có thể dựa vào 1 số pattern tấn công để phòng chống với các biện pháp rate-limit, detect sớm dự vào số request lỗi,...
Tuy nhiên có 1 hướng mình có đọc được nhưng chưa thử đó là dùng các thuật toán lọc gần đúng như BloomFilter để cache lại toàn bộ hash của ID có trong DB. Do đó khi 1 id mới request vào hệ thống sẽ có thể check được id này có thể có trong DB không rồi mới thực hiện request tới DB. Đây là 1 hướng đi khả thi bởi BloomFilter có tốc độ cao, sử dụng memory tương đối nhỏ, cũng như tính chất không bao giờ có false negative (item X có trong DB nhưng lại báo không có). Nó cũng giống như xét nghiệm sàng lọc Covid-19 nhưng mà xịn xò hơn, chỉ có dương tính giả chứ không bao giờ có âm tính giả vậy.
Tổng kết
Phew, bài viết cũng dài rồi chắc mình sẽ dừng lại ở đây. Tổng kết lại với 4 vấn đề trong bài và 1 số hướng đi để các bạn giải quyết:
- Stale cache và cách giữ data tươi mới
- Paginated cache và cách đảm bảo trải nghiệm nhất quán
- Cache stampede và cách làm nóng cache
- Cache penetration và cách bảo vệ hệ thống khỏi code lỗi cũng như attacker
Cảm ơn mọi người đã theo dõi. Bài viết tới mình sẽ trở lại với series Performance Optimization Guideline với bài viết tiếp theo về cache: Caching optimization - Con đường lắm chông gai nhé.
Một số tài liệu
Thật ra để viết chuỗi bài này thì mình đọc nhiều lắm nhưng chỉ khi nào nhớ mới lưu lại link thôi nên có vài cái dưới đây các bạn tham khảo nhé:
- https://igotanoffer.com/blogs/tech/caching-system-design-interview#writing-policies
- https://docs.microsoft.com/en-us/azure/architecture/best-practices/caching
- https://github.com/donnemartin/system-design-primer#cache
- https://medium.com/@nikhilranjan/a-solution-for-thundering-heard-problem-in-node-js-30a1618edc7a
- https://www.eximiaco.tech/en/2019/05/28/the-thundering-herd-problem/
- https://doordash.engineering/2018/08/03/avoiding-cache-stampede-at-doordash/
- https://medium.com/@mena.meseha/3-major-problems-and-solutions-in-the-cache-world-155ecae41d4f
- https://www.freecodecamp.org/news/how-to-implement-cacheable-pagination-of-frequently-changing-content-c8ddc8269e81/
- https://aws.amazon.com/builders-library/caching-challenges-and-strategies/
- https://medium.datadriveninvestor.com/all-things-caching-use-cases-benefits-strategies-choosing-a-caching-technology-exploring-fa6c1f2e93aa
Hết rồi. Mình ít đọc sách lắm nên đừng hỏi mình sách nhớ. 