Tổng quan
- Ảo giác (Hallucination) trong text generation là hiện tượng mô hình AI tạo/ sinh ra các văn bản, mặc dù thường ngữ pháp chính xác và nghe thì có vẻ hợp lý, nhưng không dựa trên đầu vào được cung cấp hoặc thậm chí có thể không chính xác về mặt thực tế. Vấn đề này đặc biệt phổ biến trong các hệ thống như GPT-3, nơi các chi tiết được tạo ra có thể lệch lạc hoặc thậm chí mâu thuẫn với đầu vào. Gần đây, các mô hình như ChatGPT ra đời, hay mới đây là các mô hình khác như Gemeni, GPT-4, GPT-4o thì vấn đề ảo giác vẫn luôn nhức nhối và hiện hữu.
- Vấn đề ảo giác bắt nguồn từ những nguyên nhân nào?
-
- Dữ liệu training chưa đủ: Việc mô hình chưa tiếp xúc với dữ liệu đa dạng trong quá trình đào tạo có thể không thiết lập mối tương quan chính xác giữa đầu vào và đầu ra phù hợp, dẫn đến nội dung ảo giác.
-
- Mô hình bị overfitting: Overfit với dữ liệu đào tạo có thể khiến mô hình tạo ra đầu ra phản ánh tập hợp đào tạo nhưng không phù hợp với đầu vào mới hoặc khác đi một chút.
-
- Giám sát không đủ (Inadequate Supervision): Không có hướng dẫn thích hợp, mô hình có thể dựa quá nhiều vào logic nội tại của nó, dẫn đến đầu ra có mang tính "ảo giác" cao.
-
- Giới hạn knowledge: Mô hình ngôn ngữ tự nhiên như ChatGPT, GPT4, ... được huấn luyện với kho tri thức giới hạn tới 1 ngày nào đó và do đó nó sẽ không biết về bất kỳ thông tin nào sau ngày bị cutoff knowledge để training đó. Vì vậy, nó có thể trả lời câu hỏi của bạn với thông tin lỗi thời không còn còn phù hợp, mới được cập nhật.
-
- Vấn đề ảo giác trong việc sinh nội dung bởi LLMs cho ta thấy được sự cần thiết phải sàng lọc liên tục để nâng cao độ tin cậy của hệ thống AI trong các tình huống thực tế. Tuy nhiên, nó cũng mở ra cánh cửa cho những nghiên cứu tiên phong trong lĩnh vực trí tuệ nhân tạo và xử lý ngôn ngữ tự nhiên.
- Trong bài viết này, chúng ta sẽ cùng tìm hiểu về những chiến lược, cách thức để giải quyết hay giảm thiểu tác động của vấn đề hallucination ở các giai đoạn khác nhau trong quy trình phát triển mô hình LLM.
- Training
- Prompting
- Post-process sau quá trình sinh (Post-Response Generation)
Training
- Chúng ta sẽ bắt đầu bằng cách xem xét cách mà chúng ta có thể giảm thiểu ảo giác ngay từ giai đoạn training mô hình LLM.
Reinforcement Learning from Human Feedback (RLHF)
- Tương tự như Human-in-loop, RLHF có thể giúp giảm thiểu ảo giác nhờ feedback của human (người). Bằng cách thu thập dữ liệu mà human rank các reponses khác nhau do mô hình LLM tạo ra dựa trên chất lượng, sự kỳ vọng, ưa thích của người đánh giá, mô hình sẽ học cách điều chỉnh kết quả đầu ra của mình để phù hợp hơn với mong đợi của người hơn.
- Ý tưởng đằng sau việc sử dụng RLHF nhờ feedback của Con người (RLHF) để giảm ảo giác là vì con người là tác nhân có thể nhận biết và cung cấp phản hồi về độ chính xác và mức độ liên quan của các responses của mô hình LLM. Bằng cách đưa quá trình feedback của người vào quá trình huấn luyện, mô hình có thể học cách phân biệt giữa thông tin chính xác và không chính xác, giảm khả năng xuất hiện ảo giác. Ngoài ra, RLHF có thể giúp mô hình hiểu rõ, nhận biết hậu quả của nó khi cung cấp những vấn đề sai lệch và giúp cải thiện khả năng tạo ra các phản hồi liên quan và đúng sự thật.
Prompting
- Prompting là một kỹ thuật quan trọng trong việc tương tác với các mô hình ngôn ngữ lớn (LLM) sau khi chúng đã được huấn luyện. Đây cũng là một bước đầu tiên trong việc hiểu và giảm thiểu hiện tượng "hallucination" (ảo giác), tức là khi mô hình tạo ra thông tin không chính xác hoặc không có cơ sở trong thực tế.
Retrieval Augmented Generation (RAG)
- RAG (Retrieval Augmented Generation) giúp loại bỏ hiện tượng "hallucination" trong các mô hình ngôn ngữ lớn (LLM) bằng cách cung cấp cho chúng thêm thông tin cụ thể về ngữ cảnh trong quá trình tạo văn bản. Hallucination xảy ra khi một LLM tạo ra các phản hồi dựa trên các mẫu đã học từ dữ liệu huấn luyện thay vì dựa vào ki ến thức thực tế. Điều này xảy ra khi mô hình thiếu thông tin cụ thể về lĩnh vực hoặc gặp khó khăn trong việc nhận ra giới hạn của kiến thức của mình.
- RAG giải quyết vấn đề này bằng cách tích hợp các nguồn kiến thức bên ngoài (external knowledge) vào quá trình tạo văn bản. Nó cho phép LLM truy cập vào dữ liệu mới nhất hoặc cụ thể về ngữ cảnh từ một cơ sở dữ liệu bên ngoài, dữ liệu này sẽ được truy xuất và cung cấp cho mô hình khi tạo phản hồi. Bằng cách này, RAG đưa thêm ngữ cảnh vào lời nhắc, giúp LLM hiểu rõ hơn về chủ đề và giảm khả năng xảy ra hiện tượng hallucination.
- Ví dụ, trong trường hợp của một chatbot được thiết kế để cung cấp thông tin về xe hơi, RAG có thể truy xuất chi tiết sản phẩm cụ thể và thông tin ngữ cảnh từ một cơ sở dữ liệu bên ngoài để bổ sung cho đầu vào của người dùng. Kết quả là, LLM nhận được một lời nhắc toàn diện và chi tiết hơn, cho phép nó tạo ra các phản hồi chính xác và liên quan hơn.
- Hơn nữa, RAG có thể được kết hợp với các kỹ thuật thiết kế lời nhắc tiên tiến, chẳng hạn như cơ sở dữ liệu vector, để cải thiện hiệu suất của LLMs. Bằng cách tận dụng các phương pháp này, các công ty có thể sử dụng LLMs với dữ liệu nội bộ hoặc dữ liệu từ bên thứ ba một cách hiệu quả, đảm bảo rằng các phản hồi được tạo ra không chỉ mạch lạc mà còn chính xác về mặt thực tế.
Nói chung, RAG là một phương pháp giá trị để giảm thiểu tình trạng "ảo giác" trong LLMs, cho phép chúng tạo ra các câu trả lời đáng tin cậy và thông tin hơn nhờ việc bổ sung khả năng của chúng với các nguồn kiến thức bên ngoài (external knowledge).
Contextual Prompting
- Trapping LLM “Hallucinations” Using Tagged Context Prompts của Đại học Maryland sử dụng một kỹ thuật gắn thẻ nguồn (tagging sources) vào các lời nhắc ngữ cảnh cung cấp cho các mô hình ngôn ngữ lớn (LLMs) để giảm hiện tượng "ảo giác".
- Giải thích chi tiết hơn, tức là
- Các ngữ cảnh được cung cấp cho LLM cùng với câu hỏi là các bản tóm tắt của các bài viết trên Wikipedia, các phần sách, v.v.
- Các đoạn ngữ cảnh này được gắn thẻ (tags) bằng cách chèn các định danh duy nhất như “(source 1234)” hoặc “(source 4567)” vào cuối các câu.
- Ví dụ:
- “Paris là thủ đô của Pháp. (source 1234)”
- “Pháp nằm ở Tây Âu. (source 4567)”
- Các thẻ nguồn này là các số duy nhất tương ứng với các câu cụ thể trong đoạn ngữ cảnh gốc.
- Khi prompting được cung cấp câu hỏi và ngữ cảnh đã được gắn thẻ (tagged context) cho LLM, phương pháp của paper này cũng thêm instruction ví dụ như yêu cầu “Cung cấp chi tiết và bao gồm các nguồn trong câu trả lời (Provide details and include sources in the answer).”
- Kết quả là, LLM được guide để có các tham chiếu đến các nguồn đã gắn thẻ này khi tạo ra phản hồi.
- Các tags được cung cấp cũng là một cách để kiểm tra xem phản hồi của LLM có dựa trên các nguồn ngữ cảnh đã cho hay không.
- Nếu phản hồi chứa các source tags khớp, điều đó chỉ ra rằng LLM đã dựa vào ngữ cảnh được cung cấp thay vì có khả năng xảy ra "ảo giác".
- Các tác giả nhận thấy rằng kỹ thuật tagging này giảm các phản hồi "ảo giác" khoảng 99% so với khi không có ngữ cảnh.
Chain of Verification
- Meta AI cũng giới thiệu paper nhằm giảm hiện tượng "ảo giác" bằng cách đề xuất CoVe (Chain of Verification). CoVe tạo ra một vài câu hỏi kiểm tra/ xác nhận (verification) để hỏi, sau đó thực hiện các câu hỏi này để kiểm tra sự đồng thuận. Hình ảnh dưới đây từ bài báo gốc giúp hiển thị khái niệm này. (Bạn có thể xem thêm ở bài viết Prompting Engineer 2 mình viết về kỹ thuật này.
- CoVe yêu cầu LLM thực hiện nhiều bước sau khi tạo ra phản hồi ban đầu:
-
- Tạo phản hồi cơ bản cho truy vấn. Điều này có thể chứa các sai sót hoặc "ảo giác".
-
- Lập chiến lược verify (planning) - LLM tạo ra một bộ câu hỏi kiểm tra để xác thực công việc của chính nó.
-
- Thực hiện verify - LLM trả lời các câu hỏi kiểm tra một cách độc lập.
-
- Tạo ra phản hồi cuối cùng - Chỉnh sửa phản hồi ban đầu dựa trên kết quả kiểm tra.
-
- Các câu hỏi verify thường được trả lời chính xác hơn so với các sự thật được nêu trong các đoạn văn dài.
- Một số biến thể khác nhau của CoVe kiểm soát attention trong quá trình kiểm tra để tránh lặp lại thông tin sai:
-
- Join CoVe:
- Một prompt duy nhất (single prompt) cho planning và trả lời câu hỏi.
- Một prompt duy nhất chứa truy vấn (query), phản hồi ban đầu (baseline response), câu hỏi verify (verification questions) và câu trả lời (answers).
- Attention có thể tập trung vào toàn bộ ngữ cảnh (context) bao gồm cả phản hồi ban đầu (baseline response) có thể chứa thông tin sai.
- Dễ lặp lại những vấn đề "ảo giác" tương tự khi trả lời câu hỏi.
-
- Two-Step CoVe:
- Prompt riêng biệt cho planning dựa trên baseline response.
- Prompt riêng biệt cho trả lời các questions mà context không chứa baseline response.
- Tránh việc attention trực tiếp vào baseline response có thể chứa thông tin sai.
- Nhưng attention vẫn có thể attend vào tất cả các câu hỏi và câu trả lời.
-
- Factored CoVe:
- Mỗi câu hỏi được trả lời hoàn toàn độc lập.
- Prompt hoàn toàn độc lập cho mỗi câu hỏi verify.
- Không attend đến bất kỳ ngữ cảnh nào khác bao gồm cả baseline response.
- Tránh sự can thiệp, kết nối giữa các câu hỏi.
-
- Factor+Revise:
- Kiểm tra chéo cụ thể giữa câu hỏi và câu trả lời so với các facts ban đầu.
- Thêm prompt để kiểm tra chéo giữa câu hỏi và câu trả lời so với các facts ban đầu.
- Attention đến cả các facts ban đầu và câu hỏi & câu trả lời.
- Đánh dấu các điểm không nhất quán cho phản hồi cuối cùng.
- Lưu ý rằng các phương pháp này không được sử dụng song song. Chúng là các biến thể khác nhau của CoVe.
-
Tóm lại, CoVe yêu cầu mô hình có khả năng tự kiểm tra (verify) các phản hồi của mình bằng cách lập kế hoạch, chiến lược (planning) và trả lời các câu hỏi tập trung vào yêu cầu cụ thể, tránh việc điều kiện hóa vào các phản hồi có thể sai của chính mình. Điều này chứng minh giảm "ảo giác" trong nhiều nhiệm vụ khác nhau.
Model
- Bây giờ, chúng ta thử tiến sâu tìm hiểu vào mô hình và xem xét các nghiên cứu khác nhau về cách giảm thiểu ảo giác xem như thế nào.
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
- Microsoft giới thiệu một phương pháp mới gọi là Decoding by Contrasting Layers (DoLa), nhằm giảm thiểu hiện tượng "hallucination" trong các mô hình ngôn ngữ lớn (LLMs) mà không cần tới quá trình huấn luyện hoặc truy xuất (retrieval) thông tin. Kỹ thuật này dựa trên vấn đề mà chúng ta biết rằng knowledge thực tế trong LLMs chủ yếu được encode trong các layer của kiến trúc transformers.
- Trong quá trình tạo văn bản đầu ra, DoLa không dựa vào việc lựa chọn cứng nhắc một premature layer (là một trong những lớp đầu tiên hoặc lớp sớm hơn trong kiến trúc transformer) để tương phản. Thay vào đó, nó chủ động lựa chọn lớp premature layer phù hợp cho việc giải mã của từng token. Cách DoLa xác định lớp này là bằng cách tính toán độ lệch Jensen-Shannon (JSD) giữa phân phối đầu ra của premature layer và mature layers (là lớp cuối cùng trong kiến trúc của mô hình). JSD đóng vai trò là thước đo sự khác biệt giữa hai phân phối xác suất. Logic cơ bản là chọn lớp tiền kỳ có JSD lớn nhất khi được so sánh với lớp trưởng thành, nhằm tối đa hóa sự tương phản giữa kiến thức thực tế và xu hướng ngôn ngữ được gói gọn trong các lớp này.
- Trái ngược với mature layers, premature layers ít có khả năng nắm bắt kiến thức thực tế và ngữ cảnh toàn diện. Thay vào đó, chúng tập trung vào việc xử lý các mẫu ngôn ngữ cơ bản và các cấu trúc cú pháp. Các lớp mature layers nằm ở giai đoạn cuối của kiến trúc transformer và thường có khả năng nắm bắt kiến thức phức tạp và ngữ nghĩa toàn diện hơn.
- Chúng ta cùng phân tích chi tiết về chức năng của nó:
-
- Đối với mỗi token được giải mã, DoLa chọn động một layer premature bằng cách xác định lớp nào có phân bố đầu ra khác biệt nhất (theo JSD) so với phân bố của mature layer.
-
- JSD cao hơn cho thấy sự khác biệt rõ rệt hơn giữa nội dung thực tế và ngôn ngữ được mã hóa trong hai layers.
-
- Premature layer biểu thị các mẫu (patterns) của ngôn ngữ cơ bản hơn, trong khi mature layer đại diện nhiều hơn cho knowledge thực tế.
-
- DoLa sau đó tính toán phân bố xác suất của token tiếp theo bằng cách so sánh các logit output của mature layer và premature layer được chọn. Cụ thể, điều này liên quan đến việc trừ các xác suất log của premature layer từ các xác suất log của mature layer.
-
- Kết quả là, phân bố xác suất được tạo ra sẽ làm nhấn mạnh những thông tin thực tế trong khi giảm bớt các patterns đơn thuần.
-
- Phương pháp này rất linh hoạt. Đối với các token tương đối đơn giản và nơi mà phân bố giữa các lớp giống nhau (biểu hiện qua JSD thấp hơn), các lớp đầu tiên có thể được chọn làm premature layer. Ngược lại, đối với các token đòi hỏi kiến thức thực tế phức tạp, một layer premature cao hơn có thể được chọn để tăng cường sự khác biệt với mature layer.
- Về mặt thực nghiệm, khi DoLa được thử nghiệm trên các nhiệm vụ khác nhau như hỏi đáp trắc nghiệm, hỏi đáp mở và tạo văn bản, phương pháp này đã cho thấy những cải thiện đáng kể về tính xác thực và độ chính xác, vượt qua các phương pháp giải mã truyền thống và các kỹ thuật giải mã tương phản khác. Ngoài ra, DoLa chỉ thêm một lượng nhỏ chi phí tính toán trong giai đoạn suy luận, làm cho nó trở thành một phương pháp nhẹ nhưng hiệu quả.
- Về cơ bản, DoLa cung cấp một phương pháp động để so sánh kiến thức được mã hóa trong các lớp transformer nhằm giảm thiểu hiện tượng ảo giác, và khả năng lựa chọn layer premature phù hợp cho mỗi token là yếu tố trung tâm của hiệu quả của nó.
- Phương pháp được DoLa sử dụng, như đã mô tả, bao gồm việc so sánh các đầu ra giữa một layer premature và một layer mature. Layer mature, thường là lớp cuối cùng trong mô hình, được cho là mã hóa nhiều kiến thức thực tế hơn, trong khi các layer premature, ở giai đoạn đầu của mạng, chứa các patterns ngôn ngữ cơ bản hơn.
- Lý do cho việc chọn động một premature layer (thay vì lớp mature) nằm ở chính mục tiêu của phương pháp:
- 1.Cơ chế tương phản: Bằng cách so sánh đầu ra của hai lớp (premature và mature), DoLa nhằm mục đích khuếch đại thông tin thực tế được mã hóa trong lớp mature trong khi giảm bớt các mẫu ngôn ngữ cơ bản trong lớp premature.
-
- Khả năng thích ứng động: Trong khi lớp mature vẫn nhất quán (vì luôn là lớp cuối cùng), việc chọn một lớp premature động cung cấp khả năng thích ứng. Đối với các token hoặc ngữ cảnh khác nhau, sự khác biệt giữa lớp mature và một lớp premature cụ thể có thể rõ rệt hơn, dẫn đến độ phân kỳ Jensen-Shannon cao hơn. Bằng cách chọn các lớp premature khác nhau cho các token khác nhau, DoLa có thể tối đa hóa sự khác biệt này tốt hơn.
- 3.Highlight thông tin thực tế: Các đầu ra của lớp mature đã được mong đợi là thực tế hơn. Giá trị của việc chọn lớp premature nằm ở việc so sánh nó với lớp mature. Điều này càng nhấn mạnh nội dung thực tế trong các đầu ra của lớp mature.
-
- Tính linh hoạt: Phạm vi các đầu ra có thể từ các lớp premature cung cấp một phổ các mẫu ngôn ngữ. Bằng cách có khả năng chọn từ phổ này, DoLa có thể thích ứng so sánh các loại mẫu ngôn ngữ khác nhau với kiến thức thực tế trong lớp mature, tùy thuộc vào ngữ cảnh.
- Về cơ bản, layer mature hoạt động như một điểm tham chiếu nhất quán, trong khi việc chọn premature layer cho phép mô hình thích ứng nhấn mạnh nội dung thực tế hơn các mẫu ngôn ngữ, từ đó nhằm giảm thiểu hiện tượng ảo giác và cải thiện độ chính xác thực tế của nội dung được tạo ra.
Giảm Thiểu Hiện Tượng Ảo Giác Sau Khi Tạo Câu Trả Lời (Post-Response Generation)
Giảm Thiểu Hiện Tượng Ảo Giác của Mô Hình Ngôn Ngữ Bằng Sự Căn Chỉnh Tương Tác Giữa Question và Knowledge
- Source Paper: https://arxiv.org/pdf/2305.13669.pdf
- MixAlign là framework mới được thiết kế để tạo điều kiện tương tác liền mạch giữa người dùng và cơ sở dữ liệu kiến thức. Điểm mạnh cốt lõi của nó nằm ở việc đảm bảo các queries của người dùng chính xác phản ánh thông tin được lưu trữ trong cơ sở dữ liệu kiến thức. Thành phần quan trọng trong thiết kế của MixAlign là việc bao gồm các can thiệp của con người, được tích hợp một cách cẩn thận để giảm thiểu hiện tượng ảo giác.
- Khi nhận được truy vấn từ người dùng, MixAlign sử dụng mô hình ngôn ngữ để tinh chỉnh truy vấn này, đảm bảo nó phản ánh chính xác các thuộc tính được mô tả trong sơ đồ cơ sở dữ liệu kiến thức. Sử dụng truy vấn đã được tinh chỉnh, hệ thống trích xuất các đoạn bằng chứng liên quan. Tuy nhiên, khi đối mặt với nhiều câu trả lời tiềm năng có thể gây mơ hồ, MixAlign kích hoạt cơ chế tập trung vào con người của nó.
- Trong giai đoạn này, MixAlign xác định thuộc tính nổi bật nhất để phân biệt các ứng viên. Tận dụng thuộc tính này, mô hình ngôn ngữ sẽ xây dựng một câu hỏi làm rõ mục tiêu. Ví dụ, nếu "mùa" xuất hiện như là thuộc tính phân biệt, nó có thể đặt câu hỏi như, "Bạn đang đề cập đến mùa nào?" Phản hồi của người dùng sau đó sẽ làm rõ truy vấn, xóa bỏ những mơ hồ xung quanh các ứng viên.
- Sự tương tác hợp tác này, trong đó những hiểu biết của con người là then chốt, sau đó được tích hợp lại vào hệ thống. Được trang bị sự căn chỉnh đã được tinh chỉnh này, mô hình ngôn ngữ sẽ tạo ra một câu trả lời cuối cùng chi tiết và chính xác.
- Về cơ bản, MixAlign kết hợp các quy trình tự động với các can thiệp kịp thời của con người. Bằng cách này, nó giải quyết các mơ hồ tiềm ẩn ngay từ khi mới xuất hiện, vượt qua một rào cản lớn được quan sát thấy trong các hệ thống tạo nội dung hỗ trợ truy xuất truyền thống và hình ảnh dưới đây từ bài báo gốc minh họa điều đó.
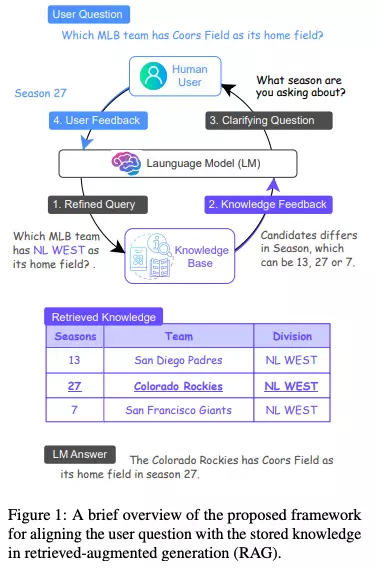
Human-in-the-loop
- Nói chung, việc sử dụng nguồn lực từ con người để review xác thực đầu ra LLM có thể giúp giảm thiểu tác động của ảo giác và cải thiện chất lượng cũng như độ tin cậy tổng thể của văn bản được tạo, nhưng cũng đòi hỏi kèm theo về nguồn chi phí khổng lồ.
Các nghiên cứu liên quan tới vấn đề Hallucination
FACTSCORE: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
- Source paper: https://arxiv.org/abs/2305.14251
- Bài báo này của tác giả Min và cộng sự từ Đại học Washington, Đại học Massachusetts Amherst, Viện Nghiên cứu AI Allen, và Meta AI tập trung vào việc đánh giá độ chính xác thực tế của văn bản dài được tạo ra bởi các mô hình ngôn ngữ lớn (LMs).
- Bài báo giới thiệu FACTSCORE, một phương pháp đánh giá mới đo lường độ chính xác thực tế của văn bản được tạo ra bởi các LMs. Nó phân tách một văn bản thành các sự kiện nguyên tử và tính toán tỷ lệ phần trăm của những sự kiện này được hỗ trợ bởi nguồn kiến thức đáng tin cậy. Phương pháp này đặc biệt cần thiết vì văn bản thường chứa hỗn hợp thông tin được hỗ trợ và không được hỗ trợ, khiến cho việc đánh giá chất lượng theo kiểu nhị phân trở nên không đủ.
- FACTSCORE giải quyết hai ý tưởng chính: sử dụng các sự kiện nguyên tử làm đơn vị để đánh giá và đánh giá độ chính xác thực tế dựa trên một nguồn kiến thức cụ thể. Nó định nghĩa một sự kiện nguyên tử là một câu ngắn chứa một thông tin duy nhất. Cách tiếp cận này cho phép đánh giá độ chính xác thực tế chi tiết hơn so với các phương pháp trước đây. Bài báo sử dụng tiểu sử của những người làm cơ sở để đánh giá do tính khách quan của chúng và bao gồm nhiều quốc tịch, nghề nghiệp, và mức độ hiếm gặp khác nhau.
- Bạn có thể xem hình ảnh dưới đây từ bài báo cho thấy tổng quan về FACTSCORE, một tỷ lệ các sự kiện nguyên tử (các mẩu thông tin) được hỗ trợ bởi một nguồn kiến thức nhất định. FACTSCORE cho phép đánh giá độ chính xác thực tế chi tiết hơn, ví dụ, trong hình, mô hình đứng đầu đạt được điểm số 66.7% và mô hình đứng dưới đạt 10.0%, trong khi các công trình trước đây sẽ chỉ định 0.0 cho cả hai. FACTSCORE có thể dựa trên đánh giá của con người, hoặc được tự động hóa, cho phép đánh giá một tập hợp lớn các LMs mà không cần nỗ lực từ con người.
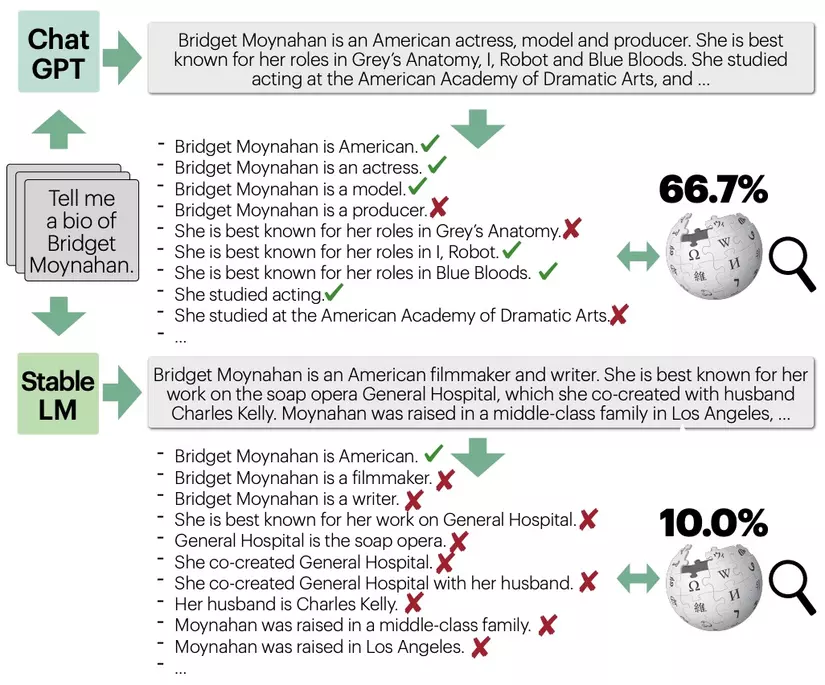
- Bộ estimator tự động FACTSCORE của họ đầu tiên chia một thế hệ thành một loạt các sự kiện nguyên tử và sau đó kiểm tra từng cái với nguồn tri thức đã cho. Họ sử dụng LLAMA 7B được huấn luyện trên Super Natural Instructions và ChatGPT như là một LMEVAL, và các công cụ truy xuất dựa trên T5 tổng quát để truy xuất đoạn văn.
- Bài báo đánh giá ba mô hình ngôn ngữ thương mại hàng đầu: InstructGPT, ChatGPT, và PerplexityAI. Các mô hình này gặp khó khăn với lỗi chính xác thực tế, với điểm FACTSCORE lần lượt là 42%, 58%, và 71%. Nghiên cứu nhấn mạnh rằng độ chính xác thực tế của các mô hình này giảm đáng kể khi độ hiếm của các thực thể được thảo luận trong văn bản tăng lên.
- Để giải quyết tính tốn thời gian và tốn kém của việc đánh giá bằng con người, các tác giả đề xuất một mô hình tự động để ước lượng FACTSCORE. Mô hình này phân tích văn bản thành các sự kiện nguyên tử và kiểm tra từng cái với nguồn tri thức, gần như tương đương với FACTSCORE với sai số dưới 2%. Điều này cho phép đánh giá một tập lớn các mô hình ngôn ngữ mới mà không cần nỗ lực thủ công từ con người.
- Bài báo cũng trình bày ứng dụng của bộ ước lượng tự động này bằng cách đánh giá 12 mô hình ngôn ngữ mới được phát hành gần đây, cung cấp cái nhìn sâu sắc về độ chính xác thực tế của chúng. Phương pháp này có thể tốn $65K nếu được đánh giá bởi con người, nhấn mạnh tính tiết kiệm chi phí của phương pháp tự động.
- Cuối cùng, bài báo đề xuất các công việc tương lai để nâng cao FACTSCORE, bao gồm việc xem xét các khía cạnh khác của tính chính xác thực tế như recall (phạm vi thông tin thực tế), cải thiện bộ ước lượng để gần đúng hơn với độ chính xác thực tế, và sử dụng FACTSCORE để chỉnh sửa các thế hệ của mô hình.
- Tổng thể thì FACTSCORE cho thấy một tiến bộ đáng kể trong việc đánh giá độ chính xác thực tế của văn bản được tạo ra bởi các mô hình ngôn ngữ, cung cấp một phương pháp chi tiết và tiết kiệm chi phí để đánh giá độ chính xác của văn bản dài.
G-Eval: NLG Evaluation Using GPT-4 with Better Human Alignment
- Source paper: https://arxiv.org/abs/2303.16634
- Source code: https://github.com/nlpyang/geval
- Chất lượng của các văn bản được tạo ra bởi các hệ thống tạo ngôn ngữ tự nhiên (NLG) rất khó đo lường tự động. Các chỉ số dựa trên tham chiếu thông thường, như BLEU và ROUGE, đã được chứng minh là có mối tương quan tương đối thấp với đánh giá của con người, đặc biệt đối với các nhiệm vụ đòi hỏi sự sáng tạo và đa dạng. Các nghiên cứu gần đây đề xuất sử dụng các mô hình ngôn ngữ lớn (LLM) như các chỉ số không dựa trên tham chiếu để đánh giá NLG, với lợi ích là có thể áp dụng cho các nhiệm vụ mới không có tham chiếu từ con người. Tuy nhiên, các bộ đánh giá dựa trên LLM này vẫn có mức độ tương đồng với con người thấp hơn so với các bộ đánh giá trung bình cỡ vừa.
- Bài báo này của Liu et al. giới thiệu G-Eval, một khung sử dụng các mô hình ngôn ngữ lớn với chuỗi suy nghĩ (CoT) và một mô hình điền vào mẫu, để đánh giá chất lượng của các kết quả NLG.
- Table bên dưới từ bài báo minh họa khung tổng thể của G-Eval. Đầu tiên, họ nhập phần Giới thiệu Nhiệm vụ và Tiêu chí Đánh giá (evaluation criteria) vào LLM, và yêu cầu nó tạo ra một chuỗi CoT của các Bước Đánh giá (evaluation steps) chi tiết. Sau đó, sử dụng yêu cầu này cùng với chuỗi suy nghĩ đã tạo để đánh giá các kết quả NLG theo mô hình điền vào mẫu. Cuối cùng, sử dụng tổng hợp có trọng số xác suất của các điểm đầu ra làm điểm số cuối cùng.
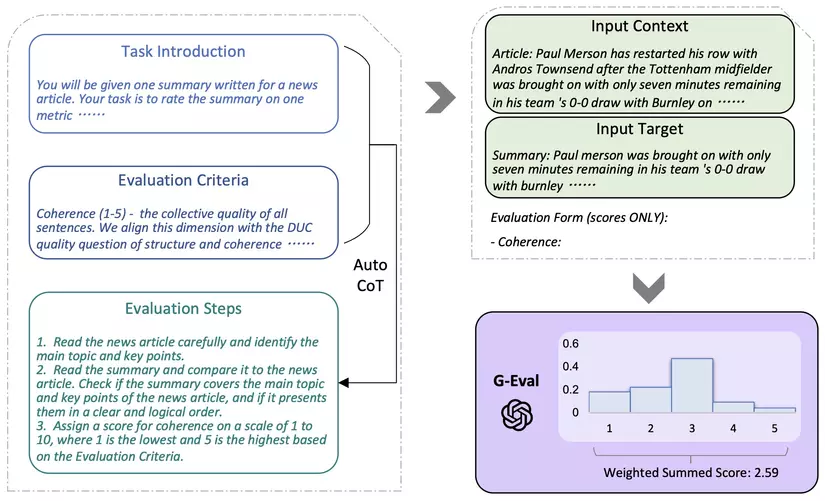
- Trong paper, họ cũng thực nghiệm với hai nhiệm vụ tạo văn bản, bao gồm tóm tắt văn bản (text summarization) và tạo đoạn hội thoại (dialogue generation) và cho thấy rằng G-Eval với mô hình nền tảng GPT-4 đạt được độ tương quan Spearman là 0.514 với đánh giá của con người trong nhiệm vụ tóm tắt văn bản, vượt trội hơn tất cả các phương pháp trước đây với một khoảng cách khá lớn.
- Họ cũng đề xuất phân tích sơ bộ về hành vi của việc đánh giá dựa trên LLM và nêu những vấn đề là việc đánh giá dựa trên LLM có thể thiên vị, ưu ái cho các văn bản do LLM tạo ra.