Bài viết này tổng hợp những kiến thức mà mình tìm hiểu về cơ chế Attention và ứng dụng của nó trong bài toán NMT (Neural Machine Translation)
Ah shiet, here we go again
Dẫn nhập về mô hình RNN Encoder-Decoder truyền thống
Để vào món chính là Attention thì chúng ta cần đá quá 1 chút về kiến trúc mô hình RNN Encoder-Decoder truyền thống.
Qua cái tên thì chúng ra có thể dễ dàng nhận ra mô hình này gồm 2 thành phần RNN đóng 2 vai trò khác nhau:
- Encoder: Encode câu đầu vào ở ngôn ngữ A thành 1 context vector (context vector dịch ra hơi khoai
 các bạn cứ hiểu đại khái là 1 cái vector đại diện cho nội dung của câu thôi). Tức là tóm gọn mọi nội dung của câu đầu vào thành 1 vector duy nhất.
các bạn cứ hiểu đại khái là 1 cái vector đại diện cho nội dung của câu thôi). Tức là tóm gọn mọi nội dung của câu đầu vào thành 1 vector duy nhất. - Decoder: Decode ra các từ tương ứng trong ngôn ngữ B qua từng time step sử dụng context vector sinh ra từ Encoder cùng với hidden state và các từ trước đó.
Các bạn có thể nhìn hình minh họa này để dễ hình dung:
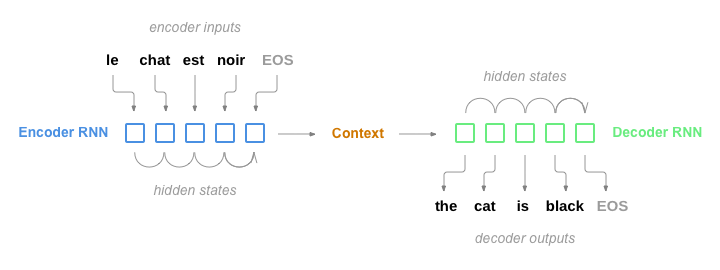 Ở đây ta có thể thấy 2 vấn đề của mô hình RNN Encoder-Decoder truyền thống:
Ở đây ta có thể thấy 2 vấn đề của mô hình RNN Encoder-Decoder truyền thống:
- Do sử dụng 1 context vector có độ dài cố định để nén toàn bộ thông tin câu đầu vào như trên, nếu gặp câu đầu vào quá dài thì việc bị nén như vậy có thể sẽ mất mát vài thông tin.
- Việc context vector là cố định ở mọi time step khiến cho Decoder luôn nhìn thấy 1 lượng thông tin duy nhất từ context vector , nên sẽ luôn dựa vào thông tin đó để trích xuất các thông tin liên quan, mặc dù mỗi time step có thể sẽ có các thành phần cần thiết khác nhau cần dùng đến. Điều đó sẽ ảnh hưởng đến độ chính xác của mô hình.
Một ví dụ so sánh mà mình nghĩ ra, có thể hơi khập khiễng và không hoàn hảo, nhưng mà kệ đi, trên đời làm gì có thứ gì hoàn hảo đâu:
- Giả sử như Decoder đóng vai trò ban giám khảo trong một cuộc thi hoa hậu, dễ thấy mỗi vòng thi sẽ có các tiêu chuẩn khác nhau cần phải chấm cho các thí sinh. Nhưng nếu Decoder là mạng RNN Encoder-Decoder truyền thống thì mỗi vòng sẽ chỉ biết 1 lượng thông tin cố định, và dựa vào đó để chấm, giả dụ là cho các thí sinh đi qua Encoder để trích xuất thông tin và đầu ra cuối cùng của Encoder sinh ra lượng thông tin liên quan đến vòng 1 các thí sinh. Mọi việc sẽ diễn ra kiểu:
- Vòng gửi xe, nhìn vòng 1 mà chấm điểm, oke hợp lý!
- Vòng áo tắm cũng nhìn vòng 1 mà chấm, well có vẻ vẫn khá hợp lý.
- Tiếp theo, đến vòng tranh biện, lại nhìn vòng 1 mà chấm ??? Có vẻ mọi chuyện đang dần sai, việc chỉ nhìn thấy 1 lượng thông tin nhất định như nhau các vòng sẽ khiến cho việc chấm điểm trở thành thảm họa.
- Ta có thể khắc phục việc này như sau: ta không lấy chỉ thông tin cuối cùng từ Encoder mà ta sẽ lấy tất cả các thông tin mà Encoder trích xuất ra, rồi để đấy, khi nào đến vòng thi thì ta sẽ lấy mỗi thứ 1 ít theo tỉ lệ, khuấy khuấy trộn trộn, và thế là mỗi vòng thi ta sẽ có lượng thông tin hữu ích khác nhau để giám khảo Decoder chấm điểm cho dễ.
- Và nôm na đó là cách mà cơ chế Attention hoạt động.
Attention
Khái niệm về kỹ thuật Attention lần đầu tiên được giới thiệu bởi Bahdanau vào năm 2015 để giải quyết vấn đề cho bài toán NMT sử dụng mô hình RNN Encoder-Decoder kể trên.
Khi sử dụng cơ chế Attention, Decoder sẽ có cơ chế tập trung vào các phần khác nhau của đầu vào tại mỗi time step khác nhau.
Đây là mô hình RNN Encoder-Decoder truyền thống không sử dụng Attention, phần Decoder sẽ nhận đầu vào là 1 context vector với độ dài cố định từ output của layer cuối cùng của Encoder
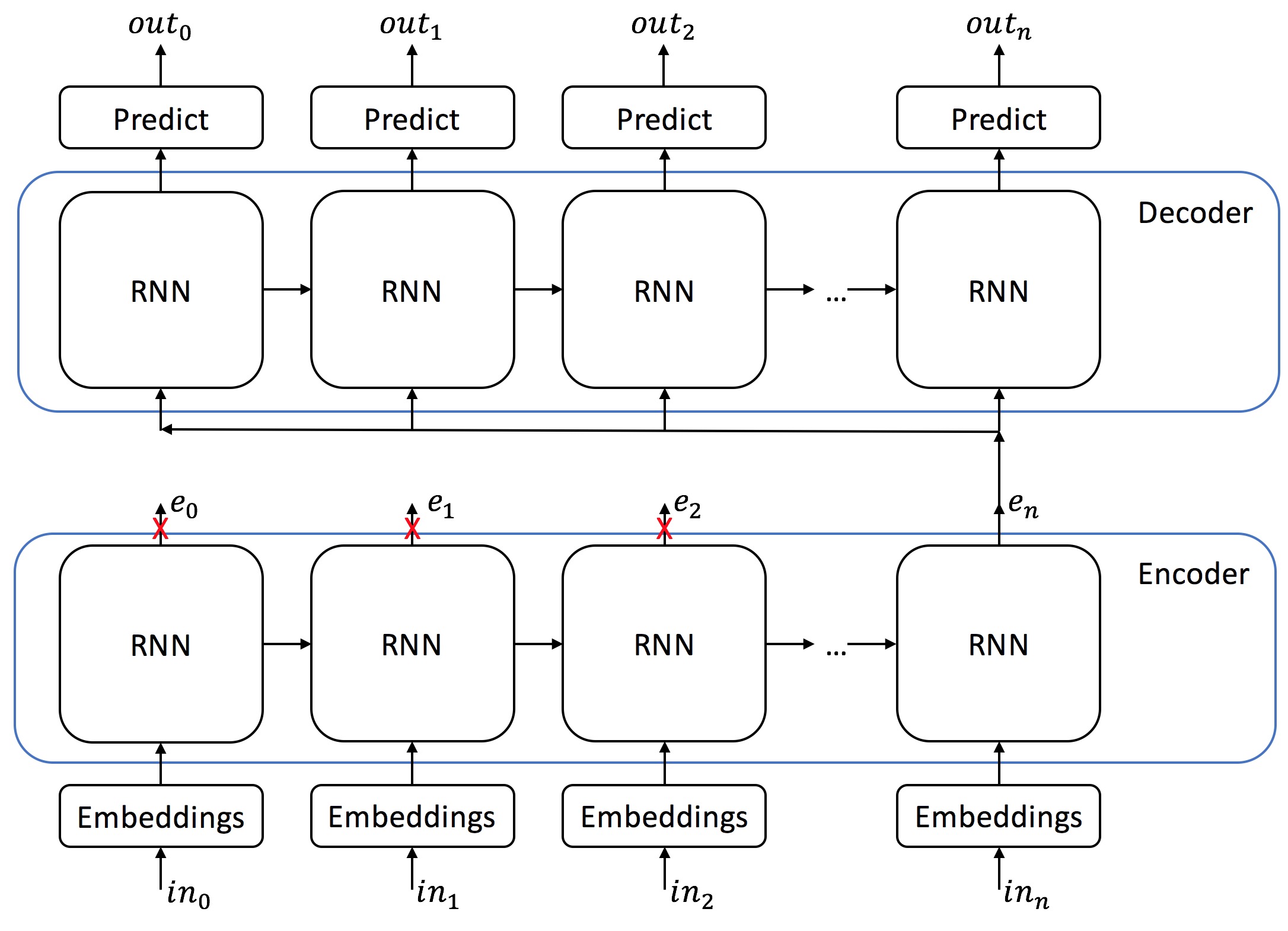
Còn đây là sau khi có thêm Attention, lúc này context vector sẽ không chỉ là output của layer cuối cùng của Encoder, mà nó sẽ được tổng hợp từ các output của từng cell của Encoder.
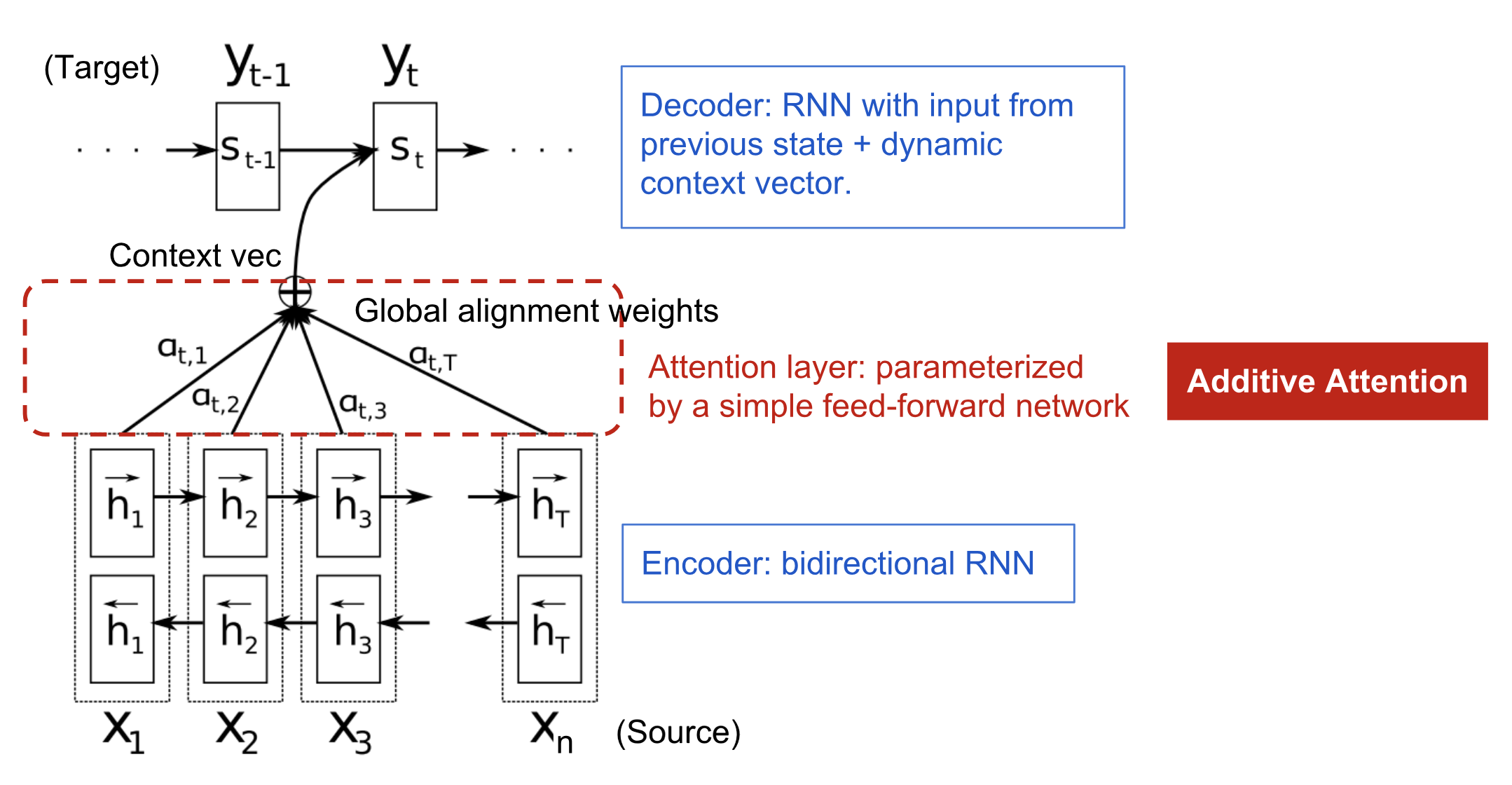
Tổng hợp thành context vector thì sẽ kiểu như này, trong đó các trọng số mô hình sẽ tự học được qua từng time step, chứ không phải làm bằng cơm, hay chưa!
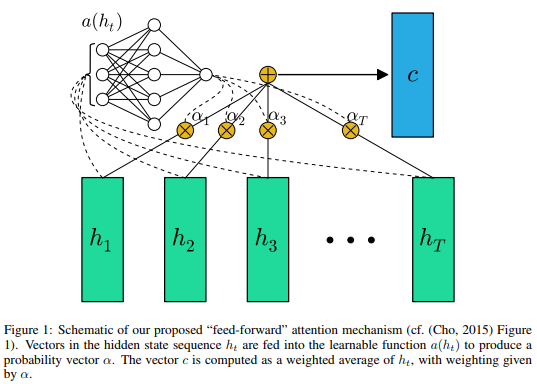
Nhờ việc tính context vector như vậy thì sẽ giải quyết được 2 vấn đề mà mô hình RNN Encoder-Decoder truyền thống gặp phải:
- Do lúc này context vector là vector động chứ không cố định nên sẽ luôn khái quát được toàn bộ thông tin của input mà cóc cần quan tâm input dài ngắn bao nhiêu
- Mỗi time step Decoder sẽ nhìn thấy các thông tin cần thiết khác nhau từ context vector chứ không nhìn chán 1 nội dung lặp đi lặp lại mãi như trước.
Mình chỉ nói nôm na vậy chứ sẽ không đi sâu vào các công thức, cách tính chi tiết các bước thì bạn có thể tìm đọc tại đây
Nhờ vào cách tính context vector như vậy trước khi đưa vào Encoder, mô hình sẽ có khả năng tập trung vào các phần quan trọng của input (với bài toán NMT là câu ở ngôn ngữ A cần dịch sang ngôn ngữ B đó) để có thể đưa ra các kết quả chính xác hơn!
Kết
Hy vọng với những kiến thức do mình tổng hợp được trình bày dưới góc nhìn hơi ngô nghê của newbie thì các bạn sẽ hiểu Attention là gì và tại sao lại dùng Attention. Theo mình thấy cơ chế Attention không hề phức tạp nhưng đem lại hiệu quả rất cao vì đã giải quyết được 2 vấn đề mà mô hình RNN Encoder-Decoder truyền thống gặp phải , và còn có thể huấn luyện mô hình end-to-end!
Bạn đọc hãy thoải mái góp ý dưới phần bình luận nếu thấy khó hiểu hoặc phát hiện ra sai sót của mình khi viết bài. Bởi đây là bài blog đầu tiên của mình nên sẽ không tránh khỏi những sai sót.
Hẹn gặp lại các bạn lần (có thể rất lâu) sau!