1. Dẫn nhập
Ở bài trước, chúng ta đã tìm hiểu về sự ra đời, nguyên lý hoạt động và gọi tên được các giai đoạn của 1 Compiler.
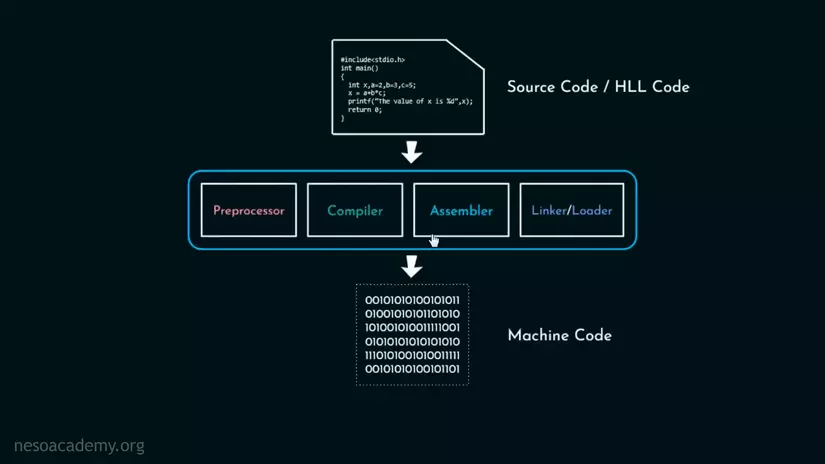 Còn trong bài này, ta sẽ đào sâu hơn 1 tý về cách mà Compiler sẽ "nhai" Pure HLL và nhả ra Assembly.
Còn trong bài này, ta sẽ đào sâu hơn 1 tý về cách mà Compiler sẽ "nhai" Pure HLL và nhả ra Assembly.
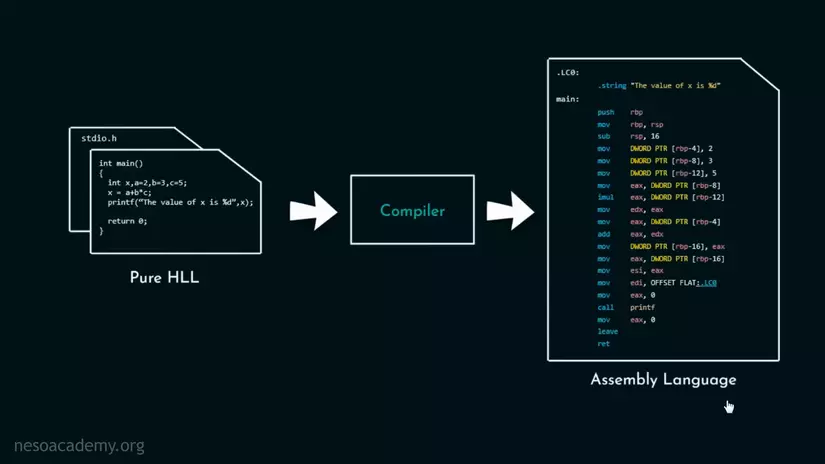 Nhưng nếu dùng cả chương trình trên làm ví dụ thì bài viết sẽ rất dài cũng như nó sẽ khá dư thừa nên chúng ta sẽ chỉ lấy phép gán biến dưới đây để tìm hiểu. Chúng ta sẽ cùng đi với x qua cuộc hành trình trở thành những đoạn code Assembly.
Nhưng nếu dùng cả chương trình trên làm ví dụ thì bài viết sẽ rất dài cũng như nó sẽ khá dư thừa nên chúng ta sẽ chỉ lấy phép gán biến dưới đây để tìm hiểu. Chúng ta sẽ cùng đi với x qua cuộc hành trình trở thành những đoạn code Assembly.
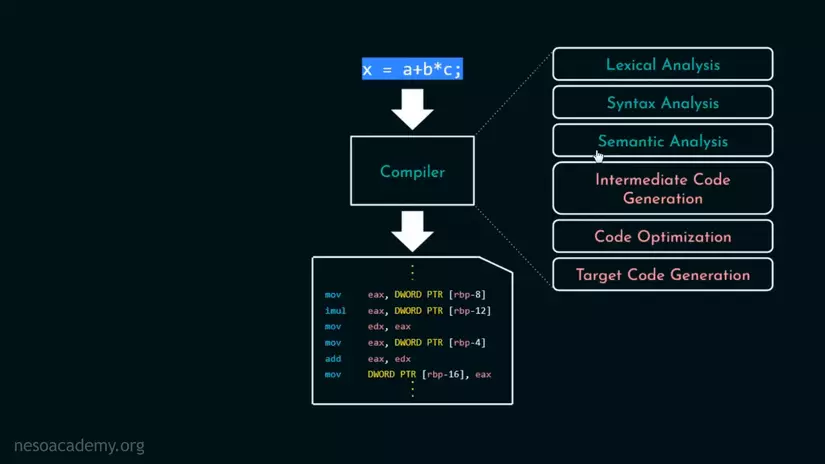
2. Lexical Analysis/Tokenization
Trong 6 giai đoạn làm việc của Compiler, Lexical Analysis là cái đầu tiên và sẽ được đảm nhiệm bởi 1 Lexical Analyzer(gọi tắt là Lexer)/Tokenizer. Công việc của Tokenizer, đúng như cái tên là biến code của bạn thành những token với cấu trúc 1 lexeme(từ vựng, xem ví dụ để hiểu rõ hơn) : 1 token(nghĩa của lexeme)
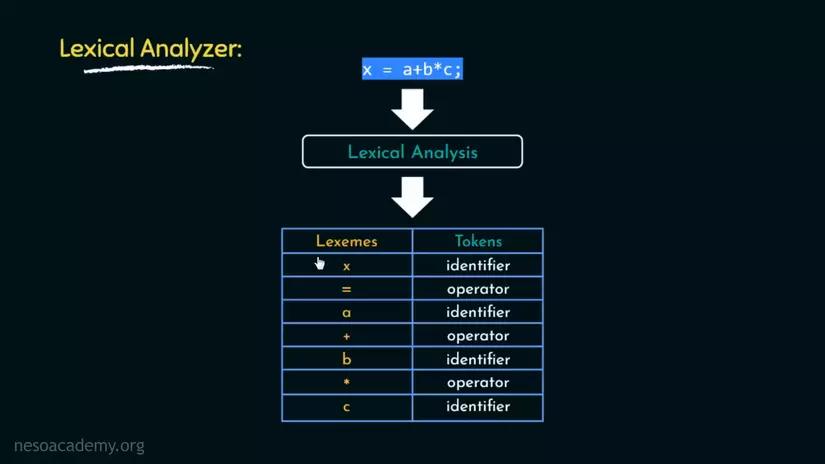 Như bạn có thể thấy, x = a+b*c , nói dễ hiểu là đã được tách ra thành những từ riêng biệt. Identifier là những gì bạn định nghĩa còn Operator là toán tử.
Như bạn có thể thấy, x = a+b*c , nói dễ hiểu là đã được tách ra thành những từ riêng biệt. Identifier là những gì bạn định nghĩa còn Operator là toán tử.
Vậy Lexer đã làm như thế nào? Tất nhiên Lexer không như bạn, nó sẽ không thể hiểu được ngữ nghĩa theo cách thông thường, nó cần những logic, quy tắc.
Câu trả lời là:
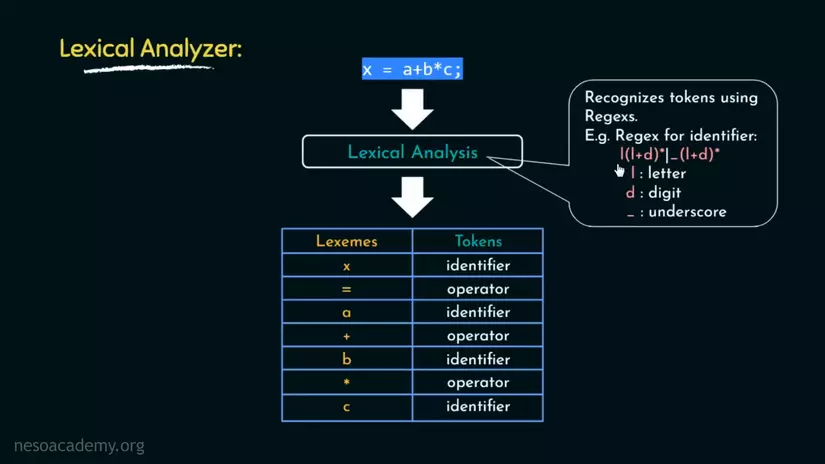 Đây là ví dụ cho lexer trong video, những quy tắc có thể sẽ do bạn định nghĩa(ngôn ngữ của bạn mà). Lưu ý là chúng ta không hẳn là dùng regex để thực thi lexer, ở đây chỉ dùng để mô tả ngắn gọn thôi.
Đây là ví dụ cho lexer trong video, những quy tắc có thể sẽ do bạn định nghĩa(ngôn ngữ của bạn mà). Lưu ý là chúng ta không hẳn là dùng regex để thực thi lexer, ở đây chỉ dùng để mô tả ngắn gọn thôi.
Sau đây là minh họa cho đoạn regex trên bằng equivalent finite automata(có thể giải thích là đồ thị của 1 công việc tự động nơi mà lượng state/trạng thái là có hạn và có chung 1 đích đến).
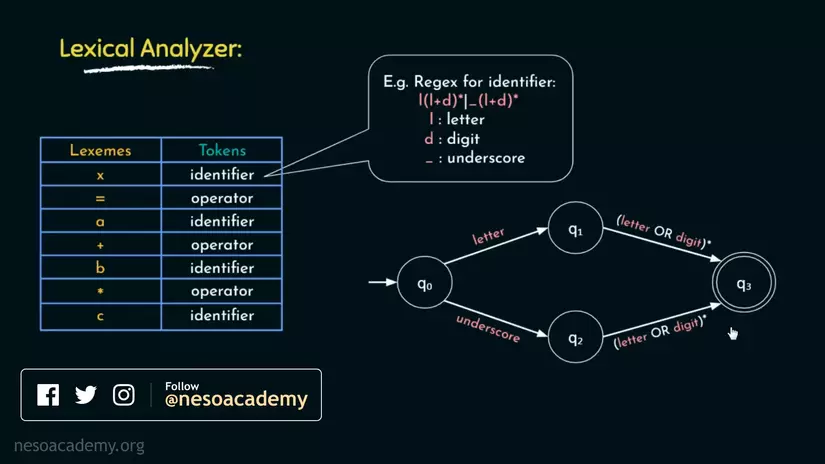 Giải thích:
Input sẽ chạy vào q0
Giải thích:
Input sẽ chạy vào q0
- nếu ký tự đầu tiên là 1 chữ cái sẽ chạy vào q1
- lấy tất chữ số và chữ cái phía sau cho tới khi gặp 1 ký tự khác chữ cái và chữ số rồi chạy vào q3
- nếu ký tự đầu tiên là dấu gạch dưới _ thì sẽ chạy vào q2
- lấy tất chữ số và chữ cái phía sau cho tới khi gặp 1 ký tự khác chữ cái và chữ số rồi chạy vào q3
Và chắc mọi người đều biết rằng, chúng ta sẽ không thể đặt 1 identifier(tên biến, tên hàm, tên class,...) bắt đầu bằng 1 chữ số trong hầu hết các ngôn ngữ. Đây là chính là logic đã từ chối việc đó.
3. Syntax Analysis
Chú ý: Cách làm việc ở phần này rất khó để giải thích vì thế bạn nên xem qua video.
"Syntax analysis, also known as parsing, is a process in compiler design where the compiler checks if the source code follows the grammatical rules of the programming language. This is typically the second stage of the compilation process, following lexical analysis." - Geeksforgeeks.org
Syntax Analysis, còn được biết đến là Parsing là 1 quá trình của compiler design, trong giai đoạn này compiler sẽ kiểm tra xem source code của bạn có tuân theo quy tắc ngữ pháp của ngôn ngữ lập trình hay không. Đây thường là giai đoạn thứ 2 trong quá trình biên dịch, nằm ngay sau Lexical Analysis.
Syntax Analyzer sử dụng ngữ pháp loại 2, Context-free grammar(Cfg).
"Context-free grammars (CFGs) are used to describe context-free languages. A context-free grammar is a set of recursive rules used to generate patterns of strings" - brilliant.org
Context-free grammars(ngữ pháp không ngữ cảnh) được dùng để mô tả những ngôn ngữ không ngữ cảnh. Một context-free grammars là 1 tập hợp của những "luật đệ quy"? dùng để tạo ra các mẫu chuỗi.
Chắc hẳn là bạn chẳng hiểu gì xấc sau khi đọc qua những dòng này. Mình cũng thế, vì vậy ta sẽ đi ngay tới ví dụ. S -> id ... trong hình là cfg production rules(nói chung nó là quy tắc) để xây dựng nên parse tree, sẽ là thứ ta muốn có sau giai đoạn Syntax Analysis.
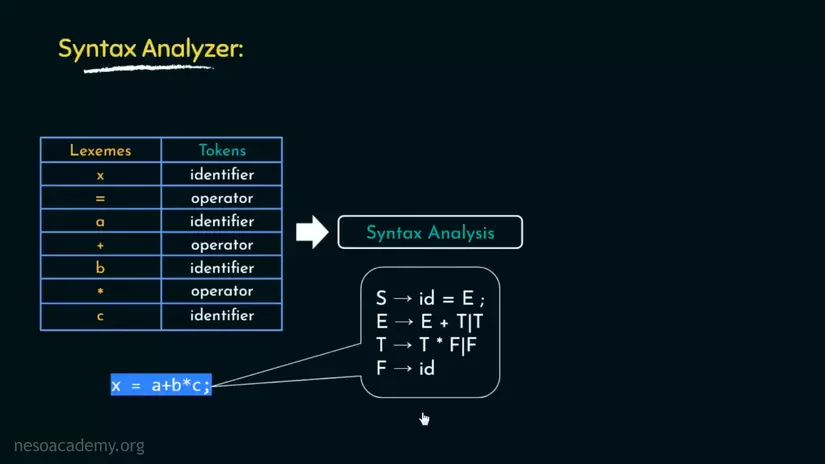 Chúng ta sẽ đi qua từng dòng, nhưng trước hết mình sẽ nhắc bạn nhớ rằng, đây là luật để phép gán biến tuân theo, không phải ngược lại.
Chúng ta sẽ đi qua từng dòng, nhưng trước hết mình sẽ nhắc bạn nhớ rằng, đây là luật để phép gán biến tuân theo, không phải ngược lại.
Dòng đầu tiên S -> id = E ; .Nghĩa là S có thể được viết lại thành id = E ;. Và id là identifier, ở đây là x. E sẽ là expression(sự thể hiện, bạn cũng có thể hiểu nó như là giá trị của id) của id.
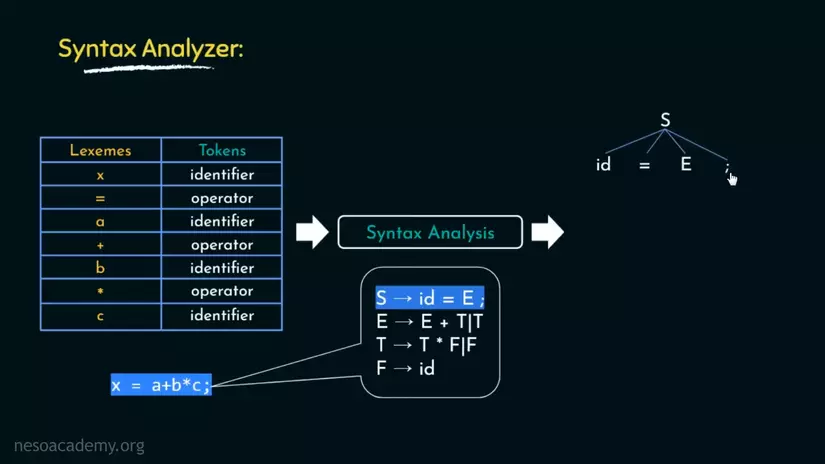 Dòng tiếp theo, E -> E + T. Nghĩa là E có thể được viết lại thành E + T. T ở đây là Term(thuật ngữ?)
Dòng tiếp theo, E -> E + T. Nghĩa là E có thể được viết lại thành E + T. T ở đây là Term(thuật ngữ?)
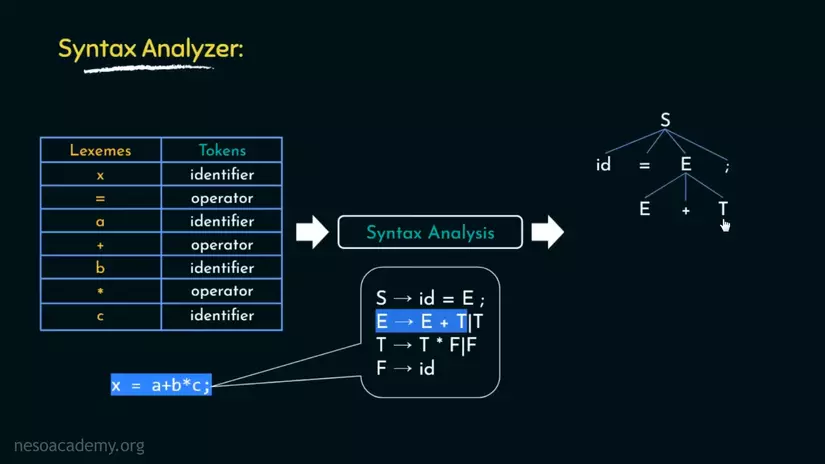 Nhưng ở đây, đầy đủ của dòng này là E -> E + T | T. Vì vậy E cũng có thể được viết lại là T.
Nhưng ở đây, đầy đủ của dòng này là E -> E + T | T. Vì vậy E cũng có thể được viết lại là T.
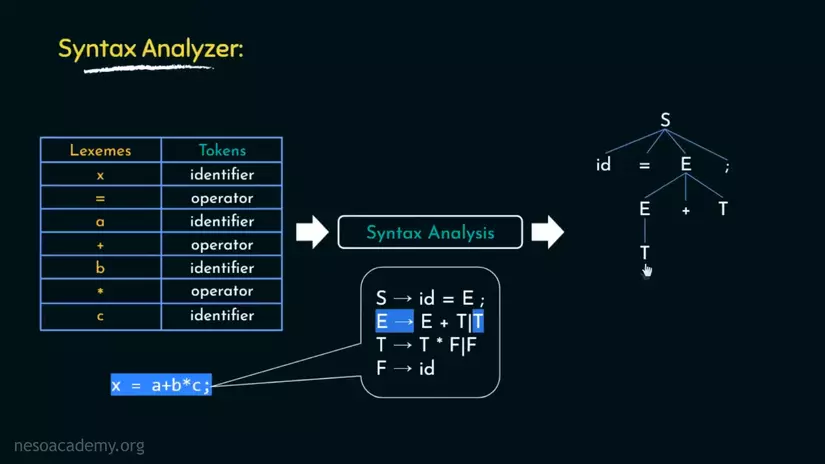 Dòng tiếp theo, T -> T * F | F. F ở đây là factor(nhân tố?). Kết quả chúng ta thu được.
Dòng tiếp theo, T -> T * F | F. F ở đây là factor(nhân tố?). Kết quả chúng ta thu được.
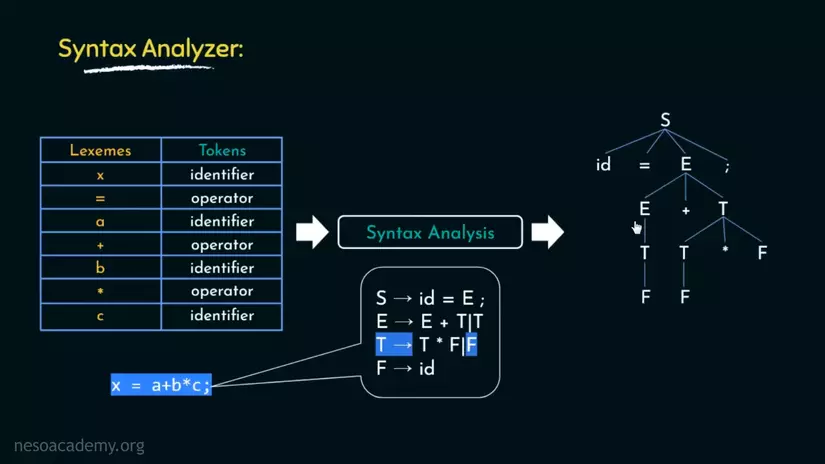 Cuối cùng, F -> id. Nghĩa là tất cả F được viết lại id.
Cuối cùng, F -> id. Nghĩa là tất cả F được viết lại id.
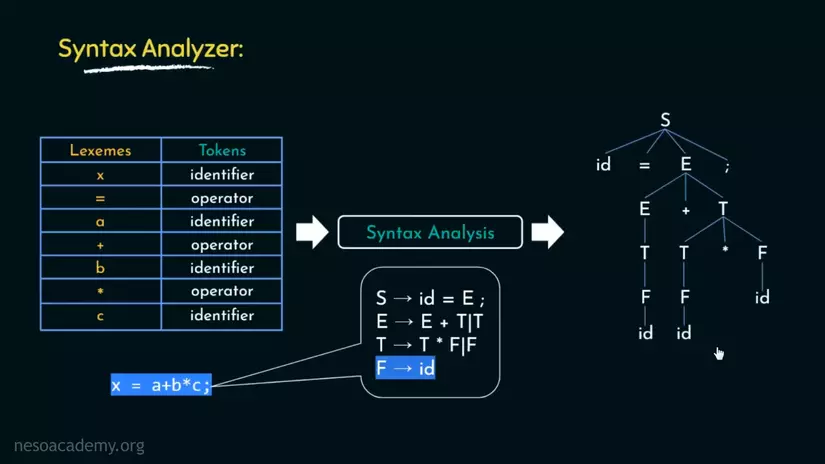
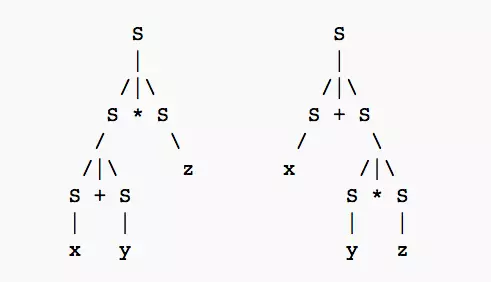
Trước khi thu "trái" từ Parse tree, chúng ta sẽ nói 1 chút về những quy tắc từ nảy giờ. id, *, =, +, ; là terminals(được hiểu là phiên bản cuối cùng, tức là không thể viết lại thành thứ khác). còn những chữ viết hoa là non-terminals(có thể được viết lại).
Quy tắc để "hái trái cây" là chúng ta sẽ "hái" từ trên xuống dưới, và từ trái sang phải(lấy phiên bản cuối cùng). Theo quy luật đó, chúng ta sẽ thu được:
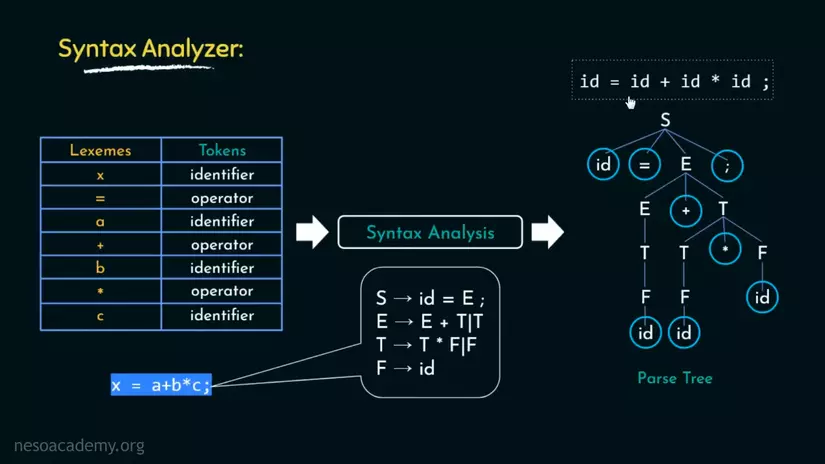
4. Semantic Analysis
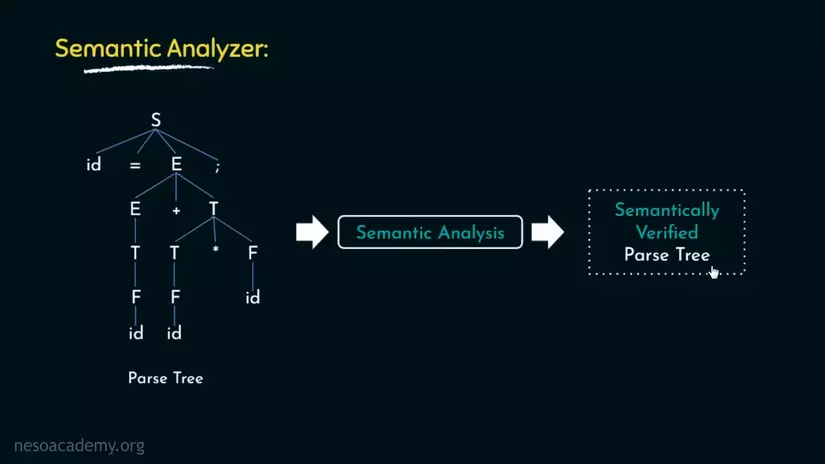
Sau khi có được Parse Tree mà Syntax Analyzer đã "trồng", là lúc mà Semantic(ngữ nghĩa) Analyzer sẽ tiếp quản công việc. Công việc của Semantic Analyzer là kiểm tra(nếu có lỗi thì nó sẽ báo lỗi và dừng luôn nên không thay đổi gì) Parse Tree thành Semantically Verified Parse Tree(đơn giản là 1 cái tên khác của Parse Tree).
Semantic Analyzer là thứ chịu trách nhiệm cho kiểm tra kiểu dữ liệu(Type checking, ràng buộc mảng(Array bound, kiểu như đặt ra giới hạn cho mảng hay là cho mảng 1 vùng nhớ trên RAM) và kiểm tra tính đúng đắn của phạm vi(Checking the correctness of scope resolution).
 Ví dụ, những Identifier được đánh dấu xanh có thể là hằng số, còn Identifier được đánh dấu đỏ, vì phía sau nó là Toán tử gán bằng nên nó không thể là hằng.
Ví dụ, những Identifier được đánh dấu xanh có thể là hằng số, còn Identifier được đánh dấu đỏ, vì phía sau nó là Toán tử gán bằng nên nó không thể là hằng.
Ở đây khi Semantic Analyzer đã nhận diện Id đỏ là 1 biến, nó sẽ kiểm tra để báo lỗi khi sai kiểu dữ liệu, biến chưa được khai báo, khai báo nhiều biến cùng tên trong 1 phạm vi, truy cập biến không nằm trong phạm vi và sự không nhất quán giữa tham số thực sự(actual) và hình thức(formal)(ví dụ trong 1 hàm, tham số khi bạn khai báo hàm là hình thức còn tham số truyền vào khi gọi hàm là thực sự),...
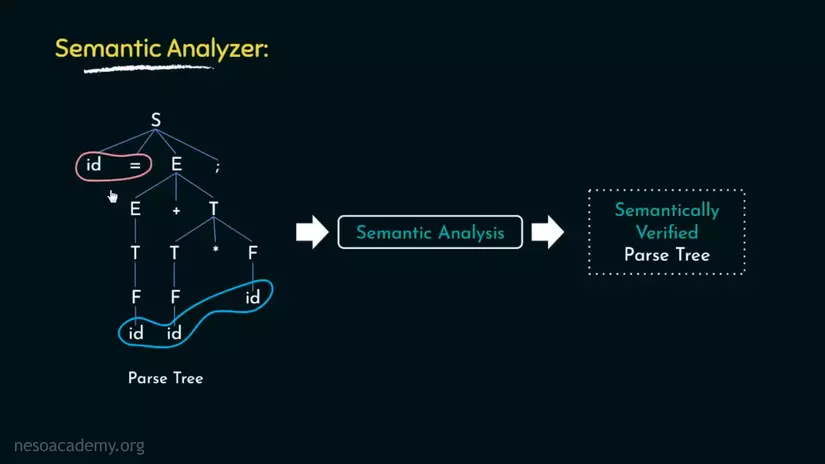
Tóm lại, Semantic Analyzer sẽ xem xét ý nghĩa và kiểm tra Parse Tree có được từ Syntax Analyzer.
5. Intermediate Code Generate
Tiếp theo là giai đoạn cuối cùng trong Front-end của Compiler, Intermediate(Trung gian) Code Generate.
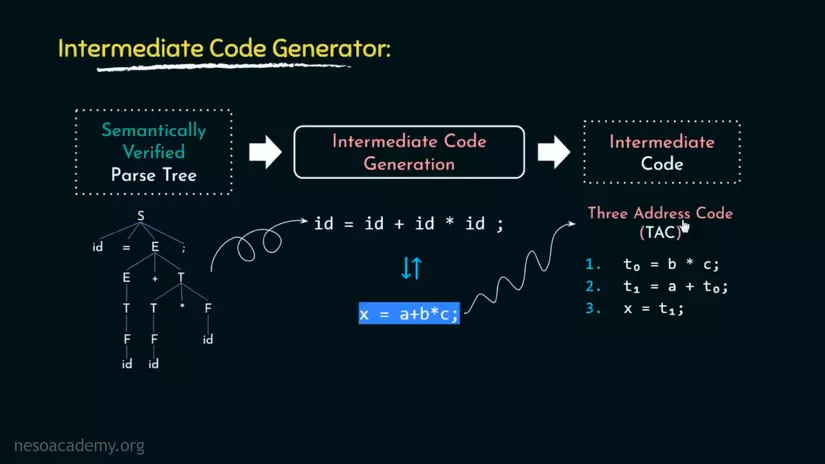
 Trong hình dưới đây, ở vị trí đầu tiên là Verified Parse Tree. Kế đến là kết quả thu được khi "hái trái" từ Parse Tree, nhìn nó tương tự như đoạn code gốc của chúng ta. Và cuối cùng là đoạn mã trung gian sử dụng Three Adress Code(TAC, mã 3 địa chỉ(ở đây là địa chỉ của 3 biến), vì phép tính kia không thể được chạy trực tiếp trên 1 địa chỉ bằng Assembly khi phải thao tác với RAM).
Trong hình dưới đây, ở vị trí đầu tiên là Verified Parse Tree. Kế đến là kết quả thu được khi "hái trái" từ Parse Tree, nhìn nó tương tự như đoạn code gốc của chúng ta. Và cuối cùng là đoạn mã trung gian sử dụng Three Adress Code(TAC, mã 3 địa chỉ(ở đây là địa chỉ của 3 biến), vì phép tính kia không thể được chạy trực tiếp trên 1 địa chỉ bằng Assembly khi phải thao tác với RAM).
Nếu bạn quan sát kĩ Parse Tree thì có thể thấy rằng mức độ ưu tiên của các phép tính đi từ dưới lên và trong TAC thì nó cũng được tính dần theo độ ưu tiên đó.
Vậy là chúng ta đã xong những gia đoạn của Front-end, và kết quả cuối cùng là Intermediate Code(sẽ được viết tắt là IC). Và tiếp theo là từ IC sang Target Code(loại mã mục tiêu), thứ sẽ thay đổi tùy vào nền tảng hệ điều hành.
6. Code Optimization
Tiếp theo là đến lượt Code Optimizer đứng trước máy quay. Về cơ bản, IC sau khi bước qua Code Optimizer sẽ trở thành Optimized Code(sẽ viết tắt là OC). Code Optimizer có thể phụ thuộc hoặc không phụ thuộc vào phần cứng, chúng ta sẽ cùng quan sát chi tiết cả 2 dạng sau.
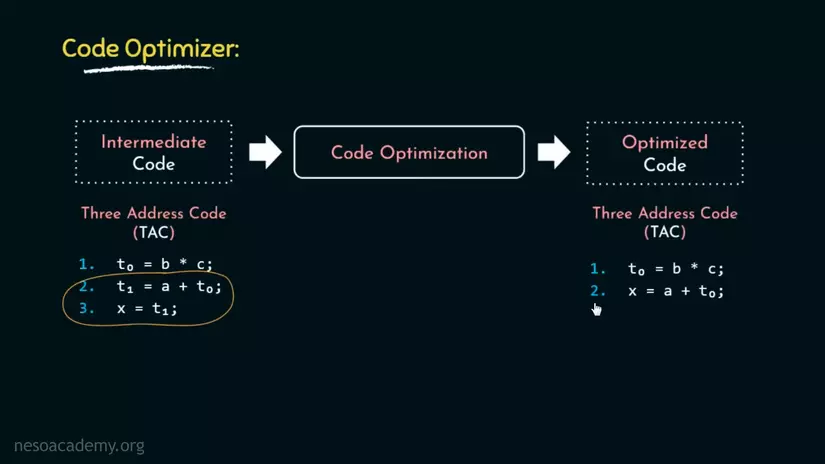
 Để dễ hiểu hơn thì đây là ví dụ. Trong đoạn TAC dưới đây, bạn có thể thấy rằng x được gán bằng T1, nhưng chúng ta hoàn toàn có thể gán thẳng x = a + T0(giá trị của T1), nó sẽ làm đoạn IC của chúng ta ngắn đi 1 dòng, có vẻ ít nhưng nếu cả 1 chương trình lớn thì đây quả thực là 1 sự tối ưu đáng kể. Và tóm lại, đó là những gì Code Optimizer sẽ làm.
Để dễ hiểu hơn thì đây là ví dụ. Trong đoạn TAC dưới đây, bạn có thể thấy rằng x được gán bằng T1, nhưng chúng ta hoàn toàn có thể gán thẳng x = a + T0(giá trị của T1), nó sẽ làm đoạn IC của chúng ta ngắn đi 1 dòng, có vẻ ít nhưng nếu cả 1 chương trình lớn thì đây quả thực là 1 sự tối ưu đáng kể. Và tóm lại, đó là những gì Code Optimizer sẽ làm.
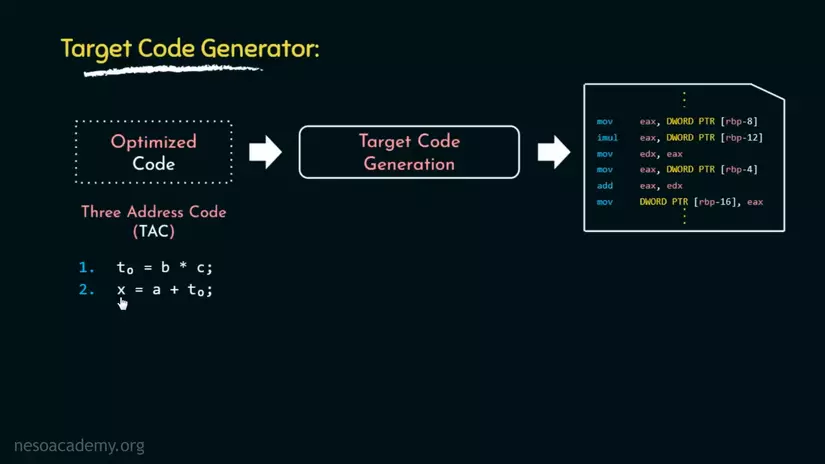
7. Target Code Generate
Cuối cùng, Target Code Generate là giai đoạn sẽ chuyển OC trực tiếp sang Target Code(ở đây là Assembly). Trong ví dụ của chúng ta, kết quả là đoạn Assembly này, trong đó 2 dòng đầu dùng cho T0, còn lại là cho x(Hãy tự tìm hiểu về Assembly để hiểu chi tiết đoạn code dưới đây làm gì).
8. Công cụ để thực thi các giai đoạn
Chú ý: để xem giải thích thì bạn nên tự đọc tài liệu hoặc xem video, mình chỉ đưa ra tên công cụ.
FLEX(Lexical Analysis)
YACC(Syntax Analyzer)
Lance C Compiler(Toàn bộ Front-end)
9. Kết
Đáng lẽ bài viết này đã xong sớm hơn, nhưng bỗng dưng cứ định viết là lại có việc bận cũng như hiện tại mình vẫn còn đang học cuối cấp. Với lại...
 Đây với mình thực sự là 1 tin rất vui, có càng nhiều người đọc bài của mình thì mình lại càng có thêm động lực để viết bài nâng cao kiến thức. Lại còn ngay ngày 20 tháng 10. Một ngày rất ý nghĩa đối với những người phụ nữ Việt Nam. Vì bài viết tiếp theo chắc là sẽ không kịp ngày đó nên mình xin chúc sớm ngày Phụ nữ Việt Nam, chúc các cô, bác, chị, em có 1 ngày 20 tháng 10 vui vẻ. Cuối lời xin cảm ơn vì đã đọc hết bài viết này của mình!
Đây với mình thực sự là 1 tin rất vui, có càng nhiều người đọc bài của mình thì mình lại càng có thêm động lực để viết bài nâng cao kiến thức. Lại còn ngay ngày 20 tháng 10. Một ngày rất ý nghĩa đối với những người phụ nữ Việt Nam. Vì bài viết tiếp theo chắc là sẽ không kịp ngày đó nên mình xin chúc sớm ngày Phụ nữ Việt Nam, chúc các cô, bác, chị, em có 1 ngày 20 tháng 10 vui vẻ. Cuối lời xin cảm ơn vì đã đọc hết bài viết này của mình!