Tiếp nối trong phần đầu tiên về các khái niệm cơ bản của Data Analytics, trong phần này, mình sẽ tập trung về các kiểu dữ liệu, levels của dữ liệu và tổng quan trực quan hóa dữ liệu, mỗi kiểu trực quan sẽ phù hợp với từng kiểu dữ liệu và mục đích khác nhau. Mời các bạn đọc cùng trao đổi nhé
Một số thuật ngữ, thông số trong thống kê và Data Analytics
Trước hết mình sẽ điểm qua một vài từ khóa cơ bản sẽ gặp nhiều trong Data Science nói chung.
- Observation: Một hàng hoặc bản ghi đơn lẻ của dữ liệu trong database, liên quan đến một sự kiện hoặc dữ liệu đơn lẻ được ghi lại tại một thời điểm. Ví dụ 1 bảng trong database có rất nhiều hàng, mỗi hàng có nhiều biến, và mỗi hàng là 1 observation. Nó cũng có thể đc gọi là a case, record, pattern or row
- Data sampling: Là một kỹ thuật phân tích thống kê bằng cách lựa chọn và phân tích một tập con đại diện của những điểm dữ liệu. Mục tiêu là xác định mẫu hành vi và xu hướng trong một lượng lớn dữ liệu được khảo sát. Sample được lựa chọn ngẫu nhiên K observation, K đc gọi là sample size
- Mean (Trung bình): Giá trị trung bình của dl, sử dụng để lấy xu hướng trung tâm của dữ liệu được đề cập
- Variance (phương sai): Tổng bình phương của sự khác biệt giữa các điểm dữ liệu và giá trị Mean. Nó đưa ra thước đo về cách dữ liệu phân phối chính nó về giá trị trung bình.
- Standard deviation (độ lệch chuẩn): Căn bậc 2 của phương sai, là thước đo mức độ mà dữ liệu thay đổi so với giá trị trung bình, nó cho biết mức độ chặt chẽ của tất cả các ví dụ được nhóm xung quanh giá trị trung bình trong một tập hợp dữ liệu.
Các kiểu dữ liệu
Sẽ có 3 kiểu dữ liệu chính mà các bạn sẽ hay bắt gặp, đó là
- Structured data: Dữ liệu được xử lý, lưu trữ và tổ chức lại theo format nhất định. Ví dụ: vị trí công việc, lương, thông tin nhân viên, …
- Unstructured data: Dữ liệu mà bị thiếu về các cấu trúc cụ thể. Ví dụ như Email,
- Semi-Structured data: Dữ liệu gồm cả Structured và Unstructured. Ví dụ như CSV, Json documents, …
80% dữ liệu doanh nghiệp là unstructured: documents, video, email, images, … Dữ liệu phi cấu trúc thường dài dòng hoặc nặng về văn bản, nhưng cũng có thể bao gồm dữ liệu như ngày, số, …
Vĩ mô hơn chút xíu, dữ liệu còn có thể phân làm 2 nhóm lớn
- Quantitative data:
- Dữ liệu đếm được, đo lường được và thể hiện bằng các con số
- Structured data
- Ví dụ: Người cao 1m7, 2 quả ổi giá 20k
- Qualitative data:
- Phân loại đối tượng dựa trên thuộc tính, mang tính mô tả và khái niệm
- Có thể được quan sát nhưng không được đo lường
- Cung cấp cái nhìn sâu sắc về một vấn đề
- Unstructured data
- Ví dụ: Da người màu trắng, sống ở Mỹ và có thể cần thuốc hỗ trợ vì quá gầy
Trong Business, nói một cách đơn giản, dữ liệu định lượng (quantitative data) giúp bạn có được những con số để chứng minh những điểm chung của nghiên cứu. Trong khi dữ liệu định tính (qualitative data) mang đến cho bạn các chi tiết và độ sâu để hiểu ý nghĩa đầy đủ của dữ liệu cũng như hiểu sâu về thị trường, khách hàng.
Phân cấp các levels của dữ liệu để đo lường hiệu quả
Data levels of measurement: Là việc phân loại mô tả bản chất của thông tin dựa trên những giá trị được gán cho biến.
Tại sao các mức đo lường lại quan trọng:
- Nó quyết định loại phân tích thống kê mà bạn có thể thực hiện.
- Do đó, nó ảnh hưởng đến cả bản chất và chiều sâu của thông tin chi tiết mà bạn có thể thu thập được từ dữ liệu của mình.
- Một số thử nghiệm thống kê chỉ có thể được thực hiện khi sử dụng các mức đo lường chính xác hơn
Do đó, điều cần thiết là lập kế hoạch trước về cách bạn sẽ thu thập và đo lường dữ liệu của mình.
Có 4 Levels của dữ liệu trong đo lường:
- Nominal
- Ordinal
- Interval
- Ratio
Dưới đây là bảng phân biệt 4 levels này, sẽ có khái niệm "true zero" khá khó hiểu, mình sẽ giải thích phía bên dưới nhé ^^
| Nominal | Ordinal | Interval | Ratio |
|---|---|---|---|
| Dữ liệu chỉ có thể được phân loại | Dữ liệu có thể được phân loại và xếp hạng | Dữ liệu có thể được phân loại, xếp hạng và cách đều nhau | Dữ liệu có thể được phân loại, xếp hạng, cách đều nhau và có “true zero”. |
| Có thể phân loại dữ liệu của mình bằng cách gắn nhãn chúng, nhưng không có thứ tự giữa các nhãn | Có thể phân loại và xếp hạng dữ liệu theo thứ tự, nhưng không thể nói bất cứ điều gì về khoảng cách giữa các thứ hạng | Có thể phân loại , xếp hạng và suy ra các khoảng bằng nhau giữa các điểm dữ liệu lân cận, nhưng không có “true zero”. | Có thể phân loại , xếp hạng và suy ra các khoảng bằng nhau giữa các điểm dữ liệu lân cận và có một “true zero” |
| Ví dụ cần phân loại dữ liệu con người thành 2 giới tính, có thể sử dụng chữ cái F cho nữ và M cho nam | 5 vận động viên đoạt huy chương Olympic hàng đầu, nhưng thang điểm này không cho bạn biết họ gần hay xa về số lần giành chiến thắng | Thu nhập một người, nhiệt độ (the độ C và F) | Trọng lượng tính bằng gam (liên tục); Số lượng nhân viên tại một công ty (rời rạc); Tốc độ tính bằng dặm trên giờ (liên tục) |
- “Zero true” (meaningful zero): tức dữ liệu có có số 0 mang ý nghĩa. Nghĩa là, giá trị bằng 0 trên ratio có nghĩa là không có biến bạn đang đo lường (Nghe rối quá, đọc tiếp ví dụ bên dưới thôi bạn ơi).
- Điểm yếu của thang đo Interval là điểm 0 chỉ là điểm giả định, không mang giá trị tuyệt đối.
- Ví dụ như 0° C không phải là không có nhiệt độ mà là tại nhiệt độ đó nước từ thể rắn chuyển sang thể lỏng. Ví dụ, 50° C mặc dù lớn gấp năm lần so với 10° C, nhưng không thể hiện nhiệt độ gấp năm lần.
- Với thước đo Ratio, nếu bạn có số lượng dân số bằng 0, điều này có nghĩa là không có người! Nếu bạn có 0 đô la có nghĩa là bạn không có sức mua, nhưng nếu bạn có 4 đô la, bạn có sức mua gấp đôi so với một người có 2 đô la.
- Một điều đặc biệt là do sự tồn tại của giá trị 0 thực, thang Ratio không có giá trị âm.
Trực quan hóa dữ liệu để đưa ra quyết định
Trực quan hóa dữ liệu (Data Visualization)
DA đề cập đến biểu diễn dữ liệu sử dụng biểu đồ, đồ thị, giúp người dùng trong việc đưa ra quyết định để có kết quả tốt nhất, nó cũng giúp trả lời đầy đủ điều kiện cho các câu hỏi business.
Để giúp người điều hành đưa ra quyết định, trực quan hóa dl phải đảm bảo 1 số yêu cầu sau
- Đơn giản
- Rõ ràng
- Trực giác
- Khuôn mẫu
- Bắt kịp xu hướng
Tầm quan trọng của DA:
- Xem và hiểu các xu hướng dữ liệu hay ngoại lệ (outliers)
- Biểu đồ, đồ thị thân thiện người dùng, giúp doanh nghiệp dễ dàng đưa ra các quyết định phù hợp nhờ việc có thể thấy các mô hình, xu hướng và mối tương quan trong dữ liệu được phân tích
- Cho phép người dùng tổ chức và trình bày dữ liệu lớn một cách trực quan
DA trong khám phá & phân tích dữ liệu (Exploratory data analytics - EDA) là bước đầu tiên để bước sang việc mô hình hóa: Nhận thông tin chi tiết về tập dữ liệu -> hiểu một số tác động quan trọng ảnh hưởng đến tập dữ liệu -> phát hiện nếu có bất kì outliers trong tập dữ liệu -> kiểm tra các giả định cơ bản của tập dữ liệu
EDA có thể có hoặc không được sử dụng trong một mô hình thống kê, nhưng nó chủ yếu cho ta thấy trước những gì dữ liệu có thể cho cta biết ngoài mô hình chính thống.
Một số biểu đồ trực quan hóa thường được sử dụng
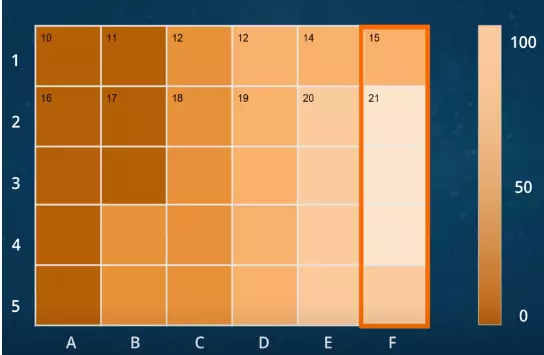
Heatmap
- Biểu đồ trực quan hóa dữ liệu thông qua các biến thể
- Sử dụng phổ màu ấm đến mát để trực quan hóa dữ liệu
- Đo lường mối quan hệ giữa nhiều biến và sức mạnh của các mối quan hệ đó thông qua màu sắc
- Cái nhìn trực quan về mối tương quan
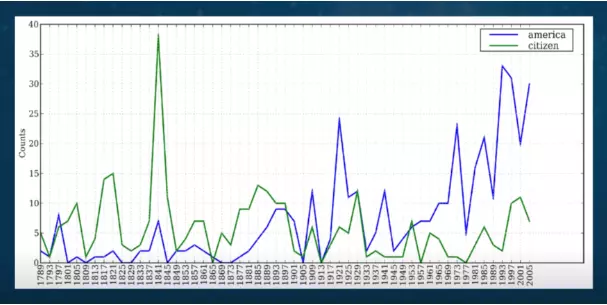
Frequency distribution plot
Hay còn gọi là Biểu đồ tần suất
- Đo tần suất của một sự kiện, tức số lần sự kiện xảy ra trong một lần quan sát
- Hiển thị số lượng quan sát trong vòng một khoảng thời gian nhất định
- Dạng bảng, biểu đồ đường, biểu đồ điểm, biểu đồ hình tròn
- Mục đích để kiểm tra hoặc minh họa dữ liệu được thu thập trong một mẫu
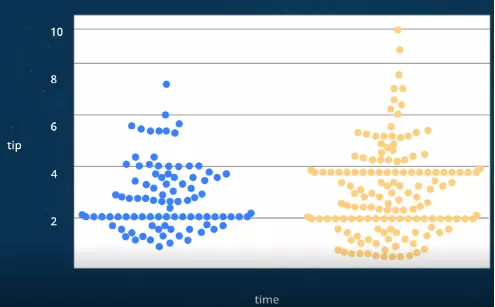
Swarm plot
- Có thể thể hiện tốt hơn sự phân bố của các quan sát
- Chỉ hoạt động tốt với các tập dữ liệu tương đối nhỏ
- Là một loại biểu đồ phân tán được sử dụng để biểu thị các giá trị phân loại. Nó tránh được sự chồng chéo của các điểm
Dashboard-Based Visualization
- Cung cấp thời gian thực đối với việc trực quan hóa dữ liệu
- Theo dõi, phân tích và hiển thị các điểm dữ liệu
- Được tùy chỉnh để phù hợp với yêu cầu cụ thể
- Về kỹ thuật (backend), Dashboard kết nối với dữ liệu, nhưng trên giao diện hiển thị tất cả dữ này dưới dạng bảng, biểu đồ, …
- Cho phép các doanh nghiệp theo dõi và có những quyết định sáng suốt, nhanh chóng kịp thời
- Các bước cho trực quan hóa dựa trên bảng điều khiển:
- Phân tích đối tượng mục tiêu: ai sẽ sử dụng dữ liệu để đưa ra quyết định
- Xác định các thông số kinh doanh chính (tức các thông số đánh giá độ hiệu quả)
- Hiểu rõ những gì sẽ là mục tiêu hoặc mục tiêu cuối cùng của Dashboard
- Xây dựng Dashboard
- Nâng cao, cải tiến Dashboard dựa trên trải nghiệm khách hàng