Chào các bạn, không biết hồi trước khi học tiếng Anh các bạn có từng "phát điên lên" với bài trọng âm không? Mình thì có, tuy ở trường có được học một số quy tắc đánh trọng âm, nhưng đau lòng thay, tiếng Anh, như mọi loại ngôn ngữ khác, luôn luôn có ngoại lệ. Tính mình thì không thích những thứ không suy ra được bằng logic nên tuy yêu thương môn tiếng Anh thắm thiết nhưng khi ôn thi đại học gần như mình luôn liệt bài trọng âm vào dạng "câu 10 điểm" và không bao giờ cố để làm những câu này cả.
Hôm trước khi ngồi dạy thêm cho đứa em thì mình bỗng ngồi nghĩ là, liệu các quy tắc trọng âm trong tiếng Anh có phải là thứ mà một model machine learning có thể học được hay không? Vậy thì chúng mình cùng tìm hiểu qua bài viết này nhé!
Vì đang học tensorflow nên trong bài này mình sẽ sử dụng các thư viện của tensorflow để thử xem.
1. Dataset
Trong bài này mình sử dụng bộ data The CMU Pronouncing Dictionary của Carnegie Mellon University. Đây là một bộ từ điển phát âm cho tiếng Anh Mỹ, bao gồm trên 134,000 từ và phát âm của chúng theo ARPAbet phoneme set, thường được sử dụng cho nhận diện và tổng hợp giọng nói (speech recognition and synthesis).
Dưới đây một số ví dụ về cách phiên âm của CMU Pronouncing Dictionary
ACCOUNT => AH0 K AW1 N T LIQUIDITY => L IH0 K W IH1 D AH0 T IY0 TELESCOPE => T EH1 L AH0 S K OW2 P
Như vậy qua cách phiên âm của 1 từ chúng ta sẽ biết được số âm tiết của từ đó (qua số nguyên âm) và trọng âm của từ nằm ở đâu (những nguyên âm được đánh số 1 đằng sau - primary stress)
vowels = ['AA ', 'AE ', 'AH ', 'AO ', 'AW ', 'AY ', 'EH ', 'ER ', 'EY ', 'IH ', 'IY ', 'OW ', 'OY ', 'UH ', 'UW ']
Chi tiết các bạn có thể tham khảo thêm tại link: http://www.speech.cs.cmu.edu/cgi-bin/cmudict
Như vậy đầu vào trong mô hình của mình sẽ là một từ bất kỳ trong tiếng Anh và output là trọng âm của từ nằm ở âm tiết thứ mấy. Do không tìm được bộ data nào khác nên model của mình sẽ chỉ học trên thứ tự sắp xếp các chữ cái của từ thôi thay vì cả từ loại như ngày xưa chúng mình học theo quy tắc đánh trọng âm.
2. Chuẩn bị dataset
Trong bài này mình sẽ sử dụng tf.data - một API của tensorlfow dùng để xây dựng một input pipepline cho model machine learning. tf.data giúp hỗ trợ xử lý lượng lớn dữ liệu, đọc dữ liệu từ các data formats khác nhau và thực hiện các bước chuyển đổi (transform) dữ liệu phức tạp. API này bao gồm một abstraction là tf.data.Dataset đại diện cho một chuỗi các phần tử, thường là mỗi phần tử tương ứng với một training example ~ một cặp tensor: input - label. Điểm tiện lợi hơn nữa là từ tensorflow 2.0, chúng ta có thể trực tiếp dùng tf.data.Dataset như một input khi dùng model.fit trong Keras.

Argument của method fit trong tf.keras.Model
Input của mình được đọc từ file text, ngoài ra có thể tạo dataset từ một list python (tf.data.Dataset.from_tensor_slices), từ các bản ghi dưới dạng TFRecord (tf.data.TFRecordDataset), hoặc từ một list file (tf.data.Dataset.list_files)
dataset = tf.data.TextLineDataset(["/content/drive/My Drive/eng.txt"])
Mỗi phần tử trong dataset của mình là một string tensor có dạng như sau:
> tf.Tensor(b'ABANDON AH0 B AE1 N D AH0 N', shape=(), dtype=string)
Để có thể pass dataset này vào trong model.fit, mình cần biến đổi mỗi phần tử trong dataset về dạng tuple gồm một cặp (input, target).
> ('ABANDON', 2)
Rất may là tf.data API có cung cấp rất nhiều method giúp mình làm điều này.
Để cho đơn giản, trước hết mình sẽ lọc bớt các từ có chứa các ký tự đặc biệt ví dụ như dấu nháy, gạch ngang, vv. Chúng ta có thể dùng dataset.filter(predicate) với predicate là một function nhằm map một phần tử trong dataset với một kết quả True hoặc False. Ví dụ muốn lọc các phần tử nhỏ hơn 3 trong dataset ta có thể làm như sau:
dataset = dataset.filter(lambda x: x < 3)
hoặc
def filter_fn(x): return tf.math.equal(x, 1)
dataset = dataset.filter(filter_fn)
Tuy nhiên do hàm filter_fn của mình có sử dụng những biểu thức, hàm mà không phải là một Tensorflow operation nên mình không thể trực tiếp truyền vào như trên mà phải thông qua một hàm tf.py_function nữa nhằm "đóng gói" function Python thành một Tensorflow operation để tính toán trên TensorFlow graph.
# filter: elminate lines that contain special characters
def filter_fn(x): s = x.numpy().decode('utf-8') pos = s.find(' ') s1 = s[0:pos] return re.match("^[A-Z]+$", s1) != None # => trả ra True nếu trong từ tiếng Anh không có ký tự đặc biệt
def tf_filter(x): return tf.py_function(filter_fn, [x], tf.bool) # => áp dụng hàm filter_fn lên một list Tensor object, kết quả trả về là tf.bool
dataset = dataset.filter(tf_filter) Tiếp theo mình sẽ thực hiện tách string ban đầu lấy từ file ra thành một tuple gồm 1 từ tiếng Anh và trọng âm tương ứng của nó dùng method map. Tương tự như filter , method này sẽ apply hàm map_fn vào từng phần tử trong dataset, và trả về một dataset mới bao gồm các phần tử đã được transform theo đúng thứ tự. map_fn có thể dùng để thay đổi cả value cũng như cấu trúc của một phần tử trong dataset.
# map1: return a tuple of input word as a string and its corresponding stress vowels = ['AA ', 'AE ', 'AH ', 'AO ', 'AW ', 'AY ', 'EH ', 'ER ', 'EY ', 'IH ', 'IY ', 'OW ', 'OY ', 'UH ', 'UW ', 'AA0', 'AE0', 'AH0', 'AO0', 'AW0', 'AY0', 'EH0', 'ER0', 'EY0', 'IH0', 'IY0', 'OW0', 'OY0', 'UH0', 'UW0', 'AA1', 'AE1', 'AH1', 'AO1', 'AW1', 'AY1', 'EH1', 'ER1', 'EY1', 'IH1', 'IY1', 'OW1', 'OY1', 'UH1', 'UW1', 'AA2', 'AE2', 'AH2', 'AO2', 'AW2', 'AY2', 'EH2', 'ER2', 'EY2', 'IH2', 'IY2', 'OW2', 'OY2', 'UH2', 'UW2']
vowels_with_stress = ['AA1', 'AE1', 'AH1', 'AO1', 'AW1', 'AY1', 'EH1', 'ER1', 'EY1', 'IH1', 'IY1', 'OW1', 'OY1', 'UH1', 'UW1'] def map_fn(x): s = x.numpy().decode('utf-8') pos = s.find(' ') s1 = s[0:pos] s2 = s[pos+2: len(s)] mark = '' l = len(s2) for j in range(0,l-2): for k in range(2,l): s3 = s2[j:k+1] if s3 in vowels_with_stress: mark += 'S' break elif s3 in vowels: mark += 's' stress = mark.find('S') + 1 return (s1, stress)
def tf_map(x): return tf.py_function(map_fn, [x], (tf.string, tf.int64))
dataset = dataset.map(tf_map)
Kết quả, phần tử mới được transform có dạng như sau:
> (<tf.Tensor: shape=(), dtype=string, numpy=b'ABANDON'>, <tf.Tensor: shape=(), dtype=int64, numpy=2>)
>> Từ: ABANDON; trọng âm nằm ở âm tiết thứ 2
Tiếp theo, để thực hiện encode input và xây dựng output layer cho mô hình, mình cần phải tìm xem từ dài nhất có trong bộ từ điển là từ nào và có tất cả bao nhiêu trọng âm. Do vậy mình sẽ phải duyệt qua tất cả các phần tử trong dataset một lượt dù thủ tục này khá tốn thời gian. Nhân tiện mình cũng sẽ "tranh thủ" đếm luôn số phần tử có trong dataset do tf.data.TextLineDataset sẽ trả về unknown shape, tức là chỉ khi toàn bộ dataset được chạy qua hết một lần, chúng ta mới biết được nó có bao nhiêu phần tử.
# calculate total length of dataset, maximum length of the input examples, number of stress available
max_len = 0
output_labels = 0
dataset_len = 0 for element in dataset.as_numpy_iterator(): word = element[0].decode('utf-8') stress = element[1] if len(word) > max_len: max_len = len(word) if output_labels < stress: output_labels+= 1 dataset_len += 1
print(dataset_len, max_len, output_labels)
Kết quả:
> dataset_len: 200632 >> max_len: 34 >>> output_labels: 8
Sau đó mình sẽ thực hiện one-hot encoding với input và label: Từ dài nhất trong từ điển của mình có 34 ký tự và bộ từ điển có các trọng âm nằm ở vị trí từ 1 đến 8. Như vậy một từ input sẽ được encode thành một vector có 34x26 = 884 phần tử với mỗi chữ cái tương ứng với một one hot vector 26 phần tử, nếu số chữ cái của từ nhỏ hơn 34 thì toàn bộ phần còn lại sẽ là 0. Tương tự thì mỗi labels thể hiện trọng âm của từ tương ứng sẽ trở thành một one hot vector có 8 phần tử.
# one-hot encode for inputs
alphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
abcdict = {}
for i in alphabet: temp = np.zeros([26,], dtype = np.float32) temp[alphabet.find(i)] = 1 abcdict[i] = temp
def encodex(word): w = word.numpy().decode('utf-8').upper() res = np.array([], dtype = int) temp = np.zeros([(max_len - len(w))*26,], dtype = np.float32) for i in w: res = np.append(res, np.array(abcdict[i])) res = np.append(res, temp) res = tf.convert_to_tensor(res) return(res) # one-hot encode for labels
stress_list = []
for i in range(0, output_labels): stress_list.append(i)
encodey = tf.one_hot(stress_list, len(stress_list), on_value = 1, dtype = tf.int32)
Theo hướng dẫn để đạt performance tốt hơn với tf.data API trên trang chủ của Tensorflow (link), mình thêm một bước cache dataset vào sau bước map cuối cùng. Khi lưu một dataset vào bộ nhớ cache, những bước transformation trước khi cache (mở file, đọc dữ liệu) sẽ chỉ phải thực hiện một lần duy nhất trong epoch đầu tiên. Nhưng epoch tiếp theo sẽ sử dụng lại dữ liệu đã được cached.
# mapping
def enc_fn(a, b): return (encodex(a), encodey[b-1])
def tf_enc(a, b): return tf.py_function(enc_fn, (a, b), (tf.int64, tf.int64))
dataset = dataset.map(tf_enc)
dataset = dataset.cache()
Như đã nói ở trên, dataset được đọc từ tf.data.TextLineDataset sẽ trả về unknown shape and rank, do vậy để đưa được vào mô hình, mình cần phải set lại shape cho nó. Đồng thời mình sẽ tạo batch dữ liệu và thực hiện bước prefetching. Hiểu đơn giản thì prefetching giúp thực hiện song song hai quá trình, training và load dữ liệu. Ví dụ khi model đang thực hiện bước training thứ n thì input pipeline sẽ thực hiện đọc data cho bước thứ n+1. Nhờ vậy chúng ta có thể giảm thiểu thời gian training cũng như tối ưu hóa được hiệu suất cho GPU (trong khi GPU training thì CPU load dữ liệu, thay vì train xong một bước thì GPU lại phải đợi CPU xử lý xong)
Các bạn có thể đọc chi tiết hơn về prefetch tại đây.
Ngoài ra trên viblo cũng có một bài viết giải thích khá chi tiết: Chuẩn bị dữ liệu với Tensorflow Dataset
def set_shapes(a, b): a = tf.reshape(a, (-1, max_len*26, 1)) b = tf.reshape(b, (-1, 8)) return a, b BATCH_SIZE = 32
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.map(set_shapes)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE) 3. Chia tập train/ val/ test
Do đặc thù của bộ Dataset mình dùng là ở dạng từ điển, xếp theo thứ tự alphabet và có nhiều từ được lặp lại chỉ thay đổi một phần theo loại từ (ví dụ PRODUCE - PRODUCT - PRODUCTS - PRODUCTION, vv.) nên mình sẽ không shuffle trước mà chia ra tập train/ validation/ test rồi mới shuffle tập train để tránh việc mô hình chỉ ghi nhớ những từ có sẵn.
API tf.data có hỗ trợ shuffling. Lưu ý là để shuffle hiệu quả nhất thì buffer_size cần lớn hơn hoặc bằng size của dataset. Ngoài ra bạn có thể thêm argument reshuffle_each_iteration=True để thực hiện shuffle lại sau mỗi epoch. (đây là tính năng mới kể từ TF 2.0, trước đó nếu muốn thứ tự shuffle thay đổi thì phải dùng bước repeat)
# train/ val/ test splitting
def split_dataset(dataset: tf.data.Dataset, validation_data_fraction: float, test_data_fraction: float): a = round(dataset_len/BATCH_SIZE*(1-validation_data_fraction - test_data_fraction)) b = round(dataset_len/BATCH_SIZE*(1 - test_data_fraction)) dataset = dataset.enumerate() train_dataset = dataset.filter(lambda f, data: f <= a) validation_dataset = dataset.filter(lambda f, data: (f > a and f <= b)) test_dataset = dataset.filter(lambda f, data: f > b) # remove enumeration train_dataset = train_dataset.map(lambda f, data: data) validation_dataset = validation_dataset.map(lambda f, data: data) test_dataset = test_dataset.map(lambda f, data: data) return train_dataset, validation_dataset, test_dataset train_ds, val_ds, test_ds = split_dataset(dataset, 0.2, 0.1)
train_ds = train_ds.shuffle(round(dataset_len/batch_size*0.7), reshuffle_each_iteration=True) 4. Model
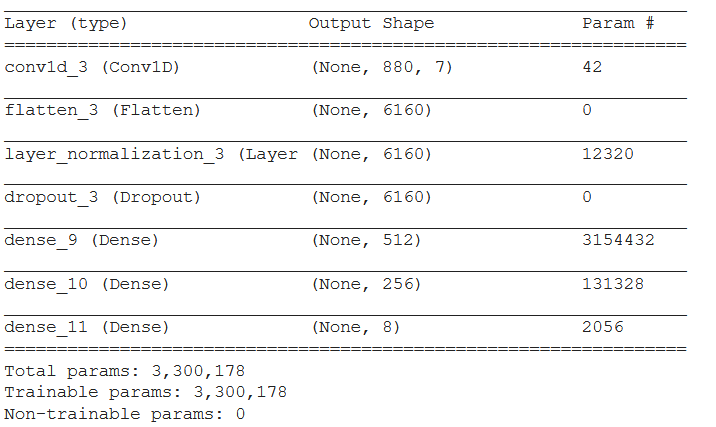
Trong bài này mình sẽ dùng một mạng neural network đơn giản gồm 2 hidden layer.
Input là một one-hot vector gồm 884 phần tử đại diện cho từ tiếng Anh.
Output là một vector 8 phần tử tương ứng với xác suất trọng âm của từ đó nằm ở từng vị trí từ 1-8.
Do vector input của mình là một sparse vector nên mình thêm một lớp convolutional layer 1D rồi flatten nó ra để kết nối với lớp dense. Cụ thể như sau:
model = Sequential()
model.add(Conv1D(filters=7, kernel_size=5, input_shape=(884, 1), activation=activations.relu))
model.add(Flatten())
model.add(LayerNormalization(axis=1 , center=True , scale=True))
model.add(Dropout(0.5))
model.add(Dense(512, activation=activations.relu))
model.add(Dense(256, activation=activations.relu))
model.add(Dense(output_labels, activation=activations.softmax))
model.summary()
Ngoài ra mình cũng kết hợp với một số Callbacks API của Keras khi training để tối ưu thời gian và tránh overfitting:
early_stopping = keras.callbacks.EarlyStopping(patience=20)
model_checkpoint = keras.callbacks.ModelCheckpoint( "my_checkpoint", save_best_only=True) Chạy thử nào
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc']) history = model.fit(train_ds, epochs=100, validation_data= val_ds, callbacks=[model_checkpoint, early_stopping]) best_model_accuracy = history.history['acc'][np.argmin(history.history['loss'])]
best_model_accuracy
Sau 32 epochs, mô hình của mình đạt accuracy là 92.7% trên tập train và 91.8% trên tập validation. Accuracy cao nhất đạt được trên tập train là 94.5%

Evaluate trên tập test:
model1 = keras.models.load_model("my_checkpoint")
model1.evaluate(test_ds)
Kết quả: 86.9% trên tập test
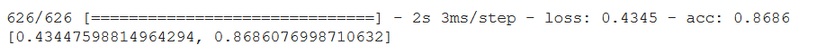
Mình sẽ thử lấy ra một vài kết quả để trông cho trực quan:
prediction = model1.predict(test_ds) test_ds1 = test_ds.unbatch()
abcdict2 = {}
for key, value in abcdict.items(): abcdict2[np.array_str(value)] = key def decodex (x : tf.Tensor): res = '' x = tf.reshape(x, (-1, 26)).numpy() for i in range(0, np.size(x, 0)): if np.array_str(x[i]) in abcdict2.keys(): res += abcdict2[np.array_str(x[i])] return res i = 0
for element in test_ds1: res_comp = 'RIGHT' if np.argmax(element[1])+1 != np.argmax(prediction[i])+1: res_comp = 'WRONG' print(decodex(element[0]), np.argmax(element[1])+1, np.argmax(prediction[i])+1, res_comp) i+=1
Một vài "đáp án":
WHODUNITS 2 2 RIGHT
WESTERNIZATION 4 4 RIGHT
YESTERDAY 1 1 RIGHT
XENOPHOBIA 3 3 RIGHT WOLVERINE 3 1 WRONG
WHATSOEVER 3 1 WRONG
WHITECOTTON 1 3 WRONG
WIDEN 1 2 WRONG
Kết luận
Như vậy trong bài viết này mình đã dùng API tf.data của Tensorflow để xây dựng một input pipeline và đưa vào mô hình machine learning dùng Keras để đoán trọng âm của một từ tiếng Anh. Kết quả đạt được là gần 87% trên tập test, con số tuy không cao nhưng đủ để mình đưa ra kết luận là dùng machine learning có thể "học" được một phần nào đó các quy tắc trọng âm tiếng Anh chỉ dựa trên phân phối các chữ cái trong từ. Nếu kết hợp với loại từ thì mình nghĩ sẽ có được độ chính xác cao hơn, tuy nhiên phần đó chắc phải để lại cho tương lai nếu có dịp.
Mình cũng chỉ mới bắt đầu với machine learning nói chung và tensorflow nói riêng chưa lâu lắm, nên nếu có sai sót rất mong nhận được góp ý từ các bạn.