Định dạng text là một định dạng vô cùng phổ biến cả trên HDFS hay bất cứ đâu. Dữ liệu file text được trình bày thành từng dòng, mỗi dòng có thể coi như một bản ghi và đánh dấu kết thúc bằng kí tự "\n" (kí tự xuống dòng). Ưu điểm của file text là nhẹ, tuy nhiên nó lại có nhược điểm là đọc ghi chậm và không thể chia nhỏ các tệp.

Apache Parquet là một định dạng lưu trữ cột có sẵn cho bất kỳ dự án nào trong hệ sinh thái Hadoop, bất kể lựa chọn khung xử lý dữ liệu, mô hình dữ liệu hoặc ngôn ngữ lập trình. Thay vì lưu trữ dữ liệu bằng các hàng liền kề với nhau, parquet có thể lưu trữ dữ liệu bởi các cột liền kề nhau. Vì vậy dữ liệu được phân vùng theo cả chiều ngang và dọc. Apache parquet khắc phục các nhược điểm của file text, giảm thời gian I/O, nén tốt hơn do dữ liệu tổ chức theo cột,...
Xem thêm : Free hosting, domain trọn đời, phù hợp cho sinh viên
Bài viết này mình sẽ nói tới việc đọc dữ liệu từ 1 file text và ghi lại dữ liệu vừa đọc được vào một file parquet trên hdfs sử dụng Spark. Trên hdfs nha chứ không phải là local disk nên trước khi làm các bạn phải start hdfs trước.
Nói chung lnhững phần khác là lâu thôi chứ tất cả những gì liên quan tới Spark thì cực kì đơn giản và nhanh chóng.
Đọc dữ liệu từ file text sử dụng Spark
Trước hết là ta có một bộ dữ liệu với file text : sample_text, là các file .dat ở trong thư mục này. Dữ liệu được biểu diễn trên các dòng, mỗi dòng là biểu diễn các thuộc tính của một đối tượng cách nhau bởi kí tự "\t". Để biết theo thứ tự thì các thuộc tính tương ứng là gì thì ta để ý file model log.txt được ghi như sau :
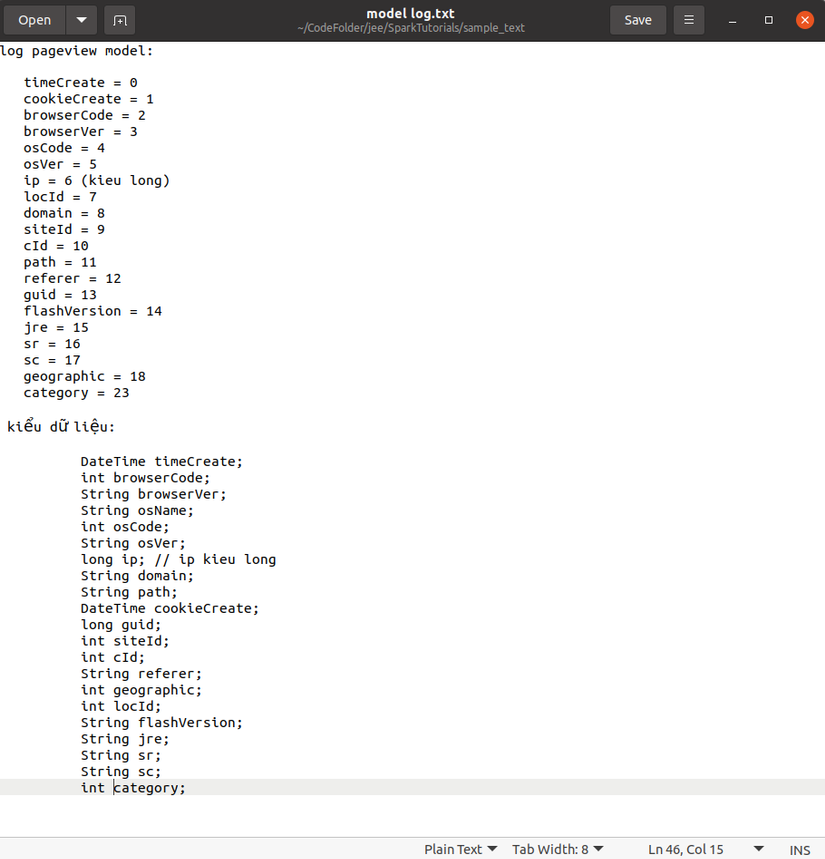
Từ file này ta có thể thấy là thuộc tính đầu tiên được định nghĩa trên mỗi dòng là timeCreate, tiếp theo là cookieCreate,... và kiểu dữ liệu của các thuộc tính đã được định nghĩa sẵn bên dưới ( như timeCreate và cookieCreate sẽ là Date).
Từ thông tin này ta có thể tạo ngay một đối tượng ModelLog có những thuộc tính trên để lưu trữ dữ liệu từ các file text này như sau :
private Date timeCreate;
private int browserCode;
private String browserVer;
private String osName;
private int osCode;
private String osVer;
private long ip;
private String domain;
private String path;
private Date cookieCreate;
private long guid;
private int siteId;
private int cId;
private String referer;
private int geographic;
private int locId;
private String flashVersion;
private String jre;
private String sr;
private String sc;
private String category;
Để đọc được dữ liệu từ file text trên thì ta sẽ khai báo một JavaSparkContext và duyệt từng dòng để lây đối tượng và lưu nó vào một listModelLog như sau :
SparkConf conf = new SparkConf().setAppName("Read file text from HDFS").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile(pathFile); for(String line : lines.collect()) { ModelLog model = splitLine(line); listModelLog.add(model);
}
Hàm splitLine sẽ bóc tách từng thuộc tính một của đối tượng được viết cách nhau bởi kí tự "\t" :
String[] tokenizer = line.split("\t"); Date timeCreate = new SimpleDateFormat("dd-MM-yyyy hh:mm:ss").parse(tokenizer[0]);
Date cookieCreate = new SimpleDateFormat("dd-MM-yyyy hh:mm:ss").parse(tokenizer[1]);
int browserCode = Integer.parseInt(tokenizer[2]);
String browserVer = tokenizer[3];
int osCode = Integer.parseInt(tokenizer[4]);
String osVer = tokenizer[5];
long ip = Long.parseLong(tokenizer[6]);
int locId = Integer.parseInt(tokenizer[7]);
String domain = tokenizer[8];
int siteId = Integer.parseInt(tokenizer[9]);
int cId = Integer.parseInt(tokenizer[10]);
String path = tokenizer[11];
String referer = tokenizer[12];
long guid = Long.parseLong(tokenizer[13]);
String flashVersion = tokenizer[14];
String jre = tokenizer[15];
String sr = tokenizer[16];
String sc = tokenizer[17];
int geographic = Integer.parseInt(tokenizer[18]);
String category = tokenizer[23];
String osName = tokenizer[5]; ModelLog tmpModelLog = new ModelLog(timeCreate, browserCode, browserVer, osName, osCode, osVer, ip, domain, path, cookieCreate, guid, siteId, cId, referer, geographic, locId, flashVersion, jre, sr, sc, category); return tmpModelLog;
Vậy sau khi chạy xong là chúng ta đã có listModelLog lấy được toàn bộ dữ liệu trong file text. Mình cũng thấy là bài viết hơi hơi dài mà dài thì dẫn tới nhàm chán nên thôi phần ghi dữ liệu ra file parquet sử dụng Spark mình sẽ viết một bài khác ở phần sau nha.
Xem tiếp phần sau : TẠI ĐÂY
Tham khảo : https://www.tailieubkhn.com/