
Ở phần 2 này, chúng ta sẽ tìm hiểu sâu hơn về Elasticsearch. Nội dung sẽ chia thành 2 phần chính:
- Cấu trúc của Elasticsearch
- Cơ chế hoạt động CRUD
- Xử lý dữ liệu trong Elasticsearch (Rất quan trọng)
Nếu có gì thắc mắc hoặc chưa rõ, mọi người có thể để lại ý kiến góp ý dưới bình luận giúp mình nhé.
1. Cấu trúc của Elasticsearch
a. Elasticsearch Cluster
Trong phần trước khi cài đặt, chúng ta chỉ cài một Node Elasticsearch, tuy nhiên nếu đầy đủ, Elasticsearch sẽ là một cụm Node phân chia làm các công việc khác nhau. Nếu bạn nào sử dụng Kubernetes (K8s), sẽ thấy rõ ở helm charts của Elasticsearch tại đây: https://github.com/helm/charts/blob/master/stable/elasticsearch/values.yaml
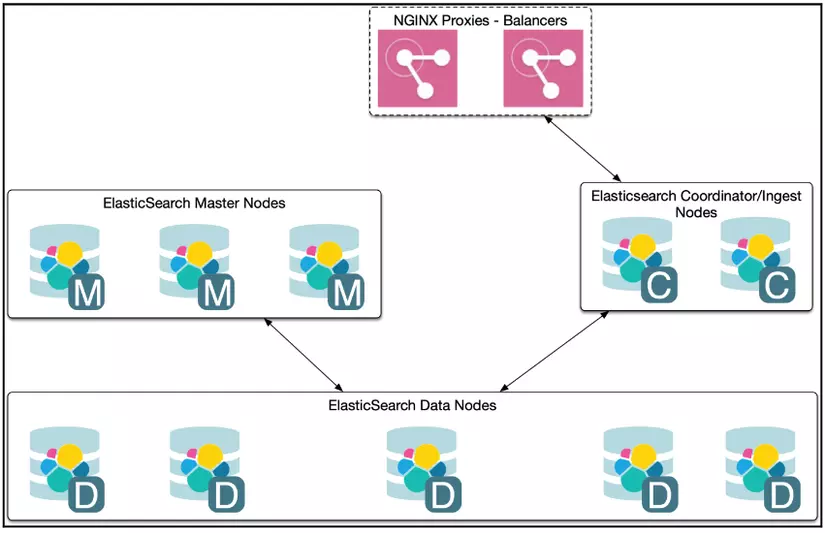 Trong đó:
Trong đó:
- Master Node: Quản lý mọi hoạt động, trạng thái của cụm.
- Data Node: Nơi lưu trữ dữ liệu.
- Coordinator/Ingest Node hoặc Client Node: Điều phối, tương tác kết nối với Client.
Tất nhiên khi hoạt động, một Node sẽ phải đảm nhận nhiều vị trí (không khác gì công việc của chúng ta tại dự án, có thể vừa là Dev vừa kiêm Tester, BA,.. nếu nhân lực không đủ).
Elasticsearch xem là thuộc loại NoSQL, là hệ thống quản lý dữ liệu không quan hệ, và mỗi hệ cơ sở dữ liệu lại có 1 số khái niệm và tên gọi các thành phần khác nhau, nên mình có xây dựng ra bảng so sánh mang tính chất tương đối như dưới đây.
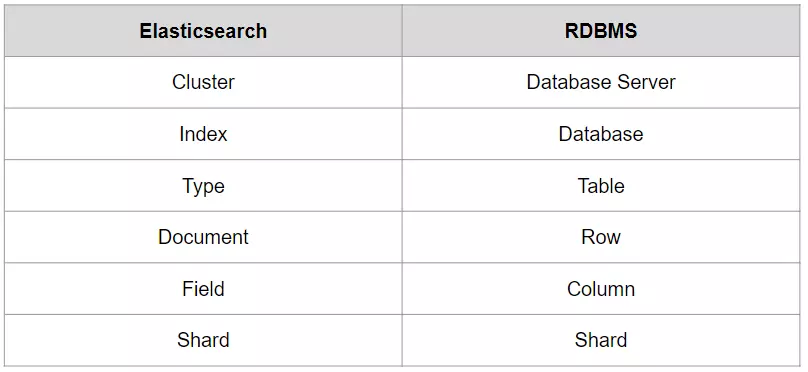
Lưu ý: Theo mình biết, ở Elasticsearch 7.x trở lên, 1 Index chỉ còn 1 Type (tương ứng với 1 Table). Ngoài ra các bạn sẽ thấy Index tương đương với 1 Database trong SQL, nên cẩn thận kẻo lẫn với index là đánh chỉ mục nhé!
b. Sharding
Nhiều người sử dụng Elasticsearch hay bất kỳ CSDL nào mà không chú ý tới Sharding. Có một câu chuyện do anh đồng nghiệp của mình kể rằng trước đây, ở công ty XYZ của anh đấy hệ thống đang chạy ổn định bỗng dưng bị treo, chậm, thậm chí không kết nối được với Database. Sau một hồi tìm hiểu nguyên nhân, phát hiện ra rằng dung lượng lưu trữ database lên tới 500GB dữ liệu, gây hiện tượng quá tải cho server. Đến khi đó, công ty XYZ này mới bắt đầu thực hiện Sharding dữ liệu.
Hiểu đơn giản Sharding giải quyết vấn đề bằng cách chia dữ liệu thành các phần nhỏ hơn có tên là Shard . Vì vậy, một Shard sẽ chứa một tập hợp con dữ liệu và bản thân nó có đầy đủ chức năng và độc lập.
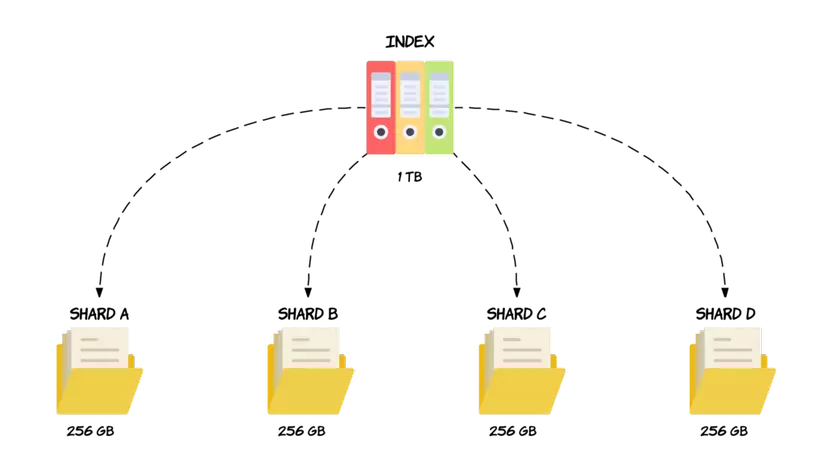
Nhờ đó, chúng có thể được lưu trữ các Shard này trên bất kỳ Node nào trong cụm. Vì vậy, trong trường hợp của ví dụ trên ảnh, chúng tôi có thể chia 1 TB dữ liệu thành bốn Shard, mỗi Shard chứa 256 GB dữ liệu và sau đó có thể được phân phối trên hai Node, hoặc hơn nếu như chúng ta muốn bổ sung thêm Node mới vào cụm, giúp scale hệ thống một cách dễ dàng.
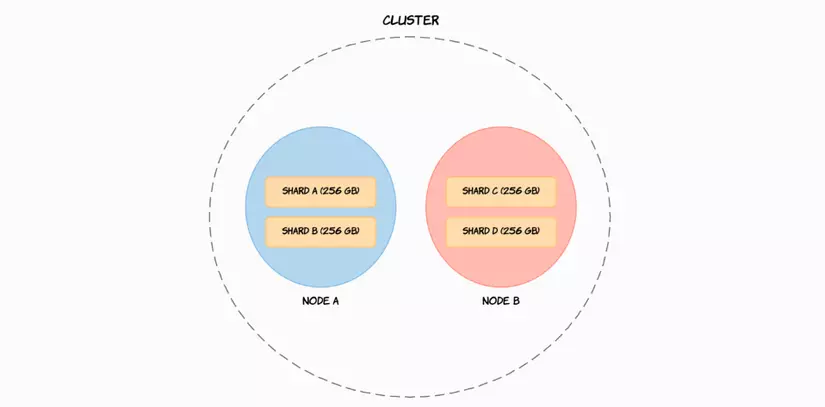
Một hệ thống luôn cần đảm bảo tính HA (High Availability) và HS (High Scalability). Elasticsearch Cluster cùng với Sharding đã đảm bảo được tính HS. Vậy HA đã được giải quyết như thế nào?
Đối với Elasticsearch, Shard chia làm 2 loại: Primary Shard và Replica Shard.
- Primary Shard: Là dữ liệu gốc của hệ thống. Tại 1 thời điểm, mỗi dữ liệu của Elasticsearch chỉ nằm trên 1 Primary Shard.
- Replica Share: Là dữ liệu sao chép của Primary Share. Có thể tồn tại nhiều dữ liệu được sao chép. (Giống như bản gốc chỉ có 1, còn photo ra được thành bao nhiêu bản cũng được).
Ví dụ cho các bạn dễ hình dung như sau:
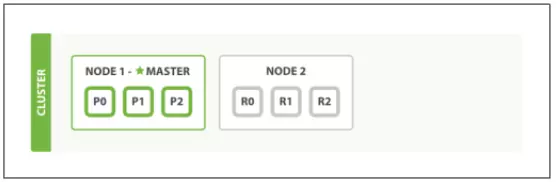
- Giả sử chúng ta có cụm Elasticsearch, tạm thời chỉ có 1 Node duy nhất.

- Chúng ta tạo 1 Index, cấu hình Shard=3, dữ liệu đã chia thành 3 Primary Shard, ký hiệu là P0, P1, P2.
 3. Để đảm bảo dữ liệu toàn vẹn, chúng ta join thêm 1 Node nữa vào trong cụm. Cấu hình Replica=1 để tạo ra 1 bộ dữ liệu copy từ các Primary Shard (R0, R1, R2).
3. Để đảm bảo dữ liệu toàn vẹn, chúng ta join thêm 1 Node nữa vào trong cụm. Cấu hình Replica=1 để tạo ra 1 bộ dữ liệu copy từ các Primary Shard (R0, R1, R2).
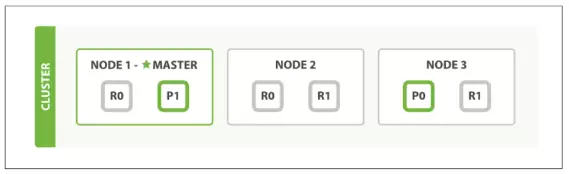
 4. 2 Node vẫn chưa đủ yên tâm, chúng ta lại mua thêm 1 Node nữa để thêm vào cụm. Các Shard đã phân bố lại trên cụm.
4. 2 Node vẫn chưa đủ yên tâm, chúng ta lại mua thêm 1 Node nữa để thêm vào cụm. Các Shard đã phân bố lại trên cụm.
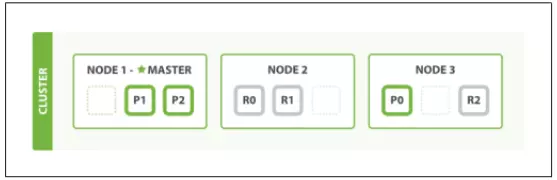
- Tiếp tục tăng Replica từ 1 lên 2, các Replica đã tiếp tục nhân bản lên 1 lần nữa.
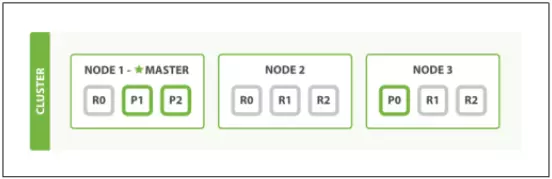
- Để kiểm tra hệ thống, Node 1 (Master Node) sẽ bị tắt đi. Chuyện gì sẽ xảy ra?
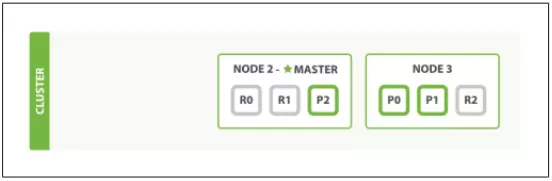
Khi này Master Node đã được chuyển sang cho Node 2. Primary Shard là P1, P2 từ Node 1 cũng đã được chuyển sang cho R1 tại Node 3 và R2 tại Node 2, để bảo đảm cụm luôn luôn có Master Node và đầy đủ các Primary Shard của dữ liệu.
Cũng dễ hiểu chứ nhỉ? 😄 Chúng ta sang phần tiếp theo nhé.
2. Cơ chế hoạt động CRUD
Nghe CRUD thì có thể các bạn mới tiếp xúc với Database cứ nghĩ là khái niệm gì lạ lẫm, nhưng thực ra nó là viết tắt của:
- CREATE
- READ
- UPDATE
- DELETE
Để hiểu về cơ chế hoạt động, mình sẽ giải thích bằng việc trả lời các câu hỏi nhé.
Câu hỏi 1:
Khi thêm 1 Document (1 bản ghi) vào Index, có nghĩa là dữ liệu sẽ được lưu tại Shard. Vậy cơ chế phân chia dữ liệu vào các Shard như thế nào?

Trả lời: Điểm đầu tiên chắc chắn với mọi người nó không phải là sử dụng Random rồi. Cơ chế mặc định trong Elasticsearch là sử dụng công thức:
shard = hash(routing) % number_of_primary_shards
Trong đó:
- routing: Giá trị sử dụng để định tuyến, mặc định sẽ là trường _id
- number_of_primary_shards: Số lượng Primary Shard (ở ví dụ này là Shard=3)
Câu hỏi 2:
Dữ liệu từ Primary Shard đã tương tác với Replica Shard như thế nào?
Trả lời: Dữ liệu tất nhiên sẽ phải đảm bảo đồng nhất giữa tất cả các Shard.
-
Đối với Create, Update, Delete:
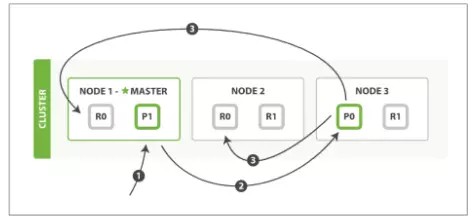
- Client gửi yêu cầu Create, Update, Delete tới Master Node.
- Master Node hash theo _id. Xác định dữ liệu sẽ thuộc Primary Shard P0.
- Sau khi đã xử lý xong ở P0. Thông báo sẽ được gửi đồng thời tới các Replica Shard là R0 (Ở Node 1 và Node 2).
- Sau tất cả, kết quả thành công sẽ được trả về cho Client.
-
Đối với Read:
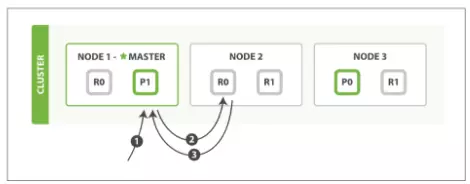
- Client gửi yêu cầu Truy vấn dữ liệu tới Master Node.
- Master Node hash theo _id, xác định dữ liệu đang được lưu trữ ở Shard 0.
- Master Node dựa theo tình hình chịu tải từ các Node, điều hướng truy vấn tới 1 Node chứa dữ liệu, ở đây là chọn R0 tại Node 2.
- Node 2 thực hiện truy vấn dữ liệu và trả kết quả về.
Câu hỏi 3:
Xử lý từng dữ liệu thì có vẻ hiểu rồi đó, nhưng cơ chế xử lý nhiều cùng 1 lúc thì khác gì không?
Trả lời: Cơ chế thực ra cũng không khác nhiều so với xử lý đơn.
-
Đối với Read:
- MGET APIs: Nhiều dữ liệu cũng xử lý tương tự, tuy nhiên sẽ tạo ra các luồng xử lý song song.
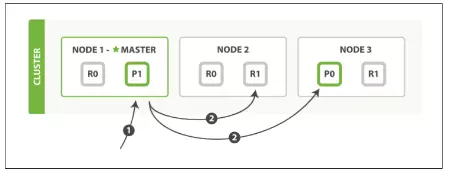
- Client gửi mget requests tới Master Node.
- Master Node tạo multi-get request tới các share tương ứng trên các Data Node.
- Sau tất cả, tổng hợp kết quả trả về Client.
-
Đối với Create, Update, Delete:
- BULK APIs
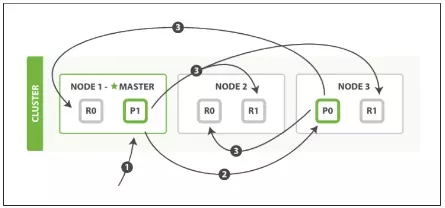
- Client gửi bulk request tới Master Node.
- Master Node tạo 1 bulk request trên mỗi shard, sau đó chuyển requests tương ứng đến Primary Shard.
- Tại mỗi Primary Shard, sau khi xử lý thành công. Gửi request(n) đến Replica Shards, đồng thời xử lý tiếp request(n+1).
- Khi tất cả các Shard thành công. Master Node tổng hợp lại và gửi kết quả về Client.
3. Xử lý dữ liệu trong Elasticsearch
Đây là phần rất quan trọng, nó ảnh hưởng trực tiếp tới việc bạn có sử dụng Elasticsearch đúng và hiệu quả hay không.
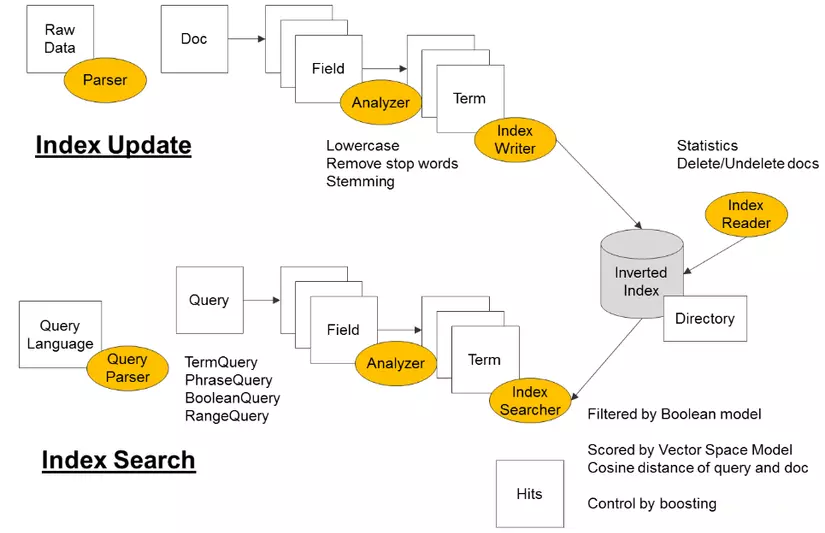
Đầu tiên, phải nói lại rằng Elasticsearch sử dụng Inverted index (chỉ mục đảo ngược là một chỉ mục cơ sở dữ liệu lưu trữ ánh xạ từ nội dung, chẳng hạn như từ hoặc số, đến các vị trí của nó trong bảng hoặc trong tài liệu hoặc tập hợp tài liệu - Theo Wikipedia 😆 )
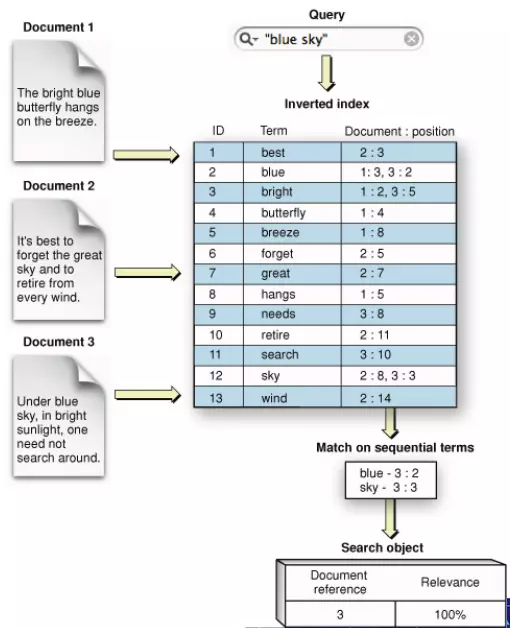
Hiểu đơn giản như ví dụ sau:
- Sau khi loại bỏ những từ ít ý nghĩa (a, an, every, for, from, the,...) các từ quan trọng được giữ lại (term) sẽ được lưu trữ lại. Như ở hình trên, bright được lưu lại là 1:2, 3:5 (document:position) có nghĩa là xuất hiện ở document 1, vị trí thứ 2 và document 3, vị trí thứ 5.
- Khi có truy vấn full-text search, ví dụ tìm xem document nào có chứa "blue sky", từ tìm kiếm cũng được tách ra theo term tương ứng là blue và sky. Dựa vào bảng Inverted index, ta thấy blue nằm ở document 1 và document 3, sky nằm ở document 2 và document 3. Từ đó kết quả trả về cụm "blue sky" được tìm thấy tại document 3.
Đến đây bạn đã hiệu được Term là gì, cũng như cơ bản về quy trình lập chỉ mục của Elasticsearch. Quy trình này được gọi là Analyzer:
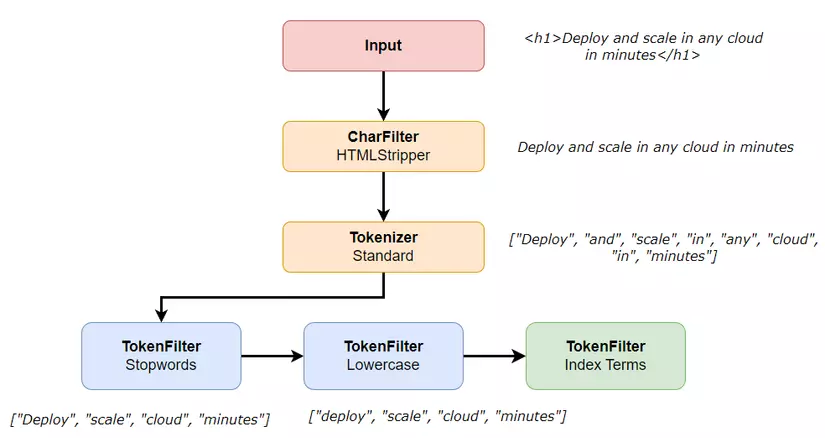
Việc phân tách ra thành các Term được mô tả như hình trên, phần quan trọng nhất chính là Tokenizer, bởi vì cách tách từ như thế nào, tách hết hay phân biệt từ đơn, từ phức, tên riêng,... sẽ ảnh hưởng đến việc truy vấn của chúng ta. Dưới đây là một số bộ Tokenizer phổ biến:
Text: “The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.”
Standard Tokenizer: Bộ tiêu chuẩn, phù hợp với hầu hết lại văn bản. Thường bỏ hết dấu câu.
- [ The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog's, bone ]
Lowercase Tokenizer: Bộ phân tách khi gặp ký tự không phải chữ cái, và chuyển về viết thường.
- [ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]
Classic Tokenizer: Bộ tiêu chuẩn sử dụng cho Tiếng Anh.
- [ The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog's, bone ]
Keyword Tokenizer: “Noop” Tokenizer vì xem text nhập vào là 1 term duy nhất.
VN Tokenizer: Bộ phân tách từ Tiếng Việt, bạn có thể tham khảo plugin của anh DuyDo trên github.
Mọi người có thể chạy thử analyzer qua API của Elasticsearch để tìm hiểu thêm nhé.
GET http://localhost:9200/_analyze
{ "analyzer" : "standard", "text" : "Quick Brown Foxes!"
}
-----
Tổng kết lại, sau bài viết này chúng ta đã hiểu về cách hoạt động của Elasticsearch trong việc quản lý dữ liệu. Mọi người nên nắm được các khái niệm về Index, Shard, Replica, Analyzer, Tokenizer, Term đê chuẩn bị cho phần tiếp theo nhé.