1. AI là gì?
AI là từ viết tắt của Artificial Intelligence, hay còn gọi là Trí tuệ nhân tạo. Có rất nhiều cách định nghĩa thuật ngữ này, nhưng một cách đơn giản nhất là bạn có thể hiểu trí tuệ nhân tạo là lĩnh vực nghiên cứu và phát triển các hệ thống máy tính có khả năng thực hiện những nhiệm vụ thông minh giống như con người. Một điều mà nhiều người, đặc biệt là những người ngoài ngành, thường nhầm tưởng về AI là họ nghĩ rằng AI phải là một thứ gì đó rất cao siêu, giống như những con robot có khả năng di chuyển, vận động, suy nghĩ và có cảm xúc như con người. Đây là những hình ảnh mà các bộ phim khoa học viễn tưởng của Hollywood đã gieo vào đầu chúng ta. Tuy nhiên, thực tế lại không như vậy. Không chỉ những con robot có hành vi giống con người hay những ứng dụng AI như Chat GPT hay Mid Journey mới được coi là AI. Ngay cả những ứng dụng đơn giản hơn, ví dụ như một mô hình dự đoán nhiệt độ ngoài trời hay dự đoán xem một người có mắc bệnh hay không, cũng được xem là AI. Suy cho cùng, AI là trí tuệ nhân tạo, không phải là trí tuệ siêu phàm hay siêu nhiên.
2. Machine Learning - học máy
Machine Learning (tiếng Việt: Học máy) là một lĩnh vực con của AI, tập trung vào việc giúp máy tính có khả năng tự học hỏi từ dữ liệu mà không cần phải được lập trình cụ thể. Sự khác biệt giữa lập trình cụ thể và không cụ thể nằm ở việc cách hệ thống học hỏi và xử lý thông tin. Ví dụ, nếu bạn muốn xây dựng một mô hình AI để phát hiện xem một giao dịch ngân hàng có phải là lừa đảo hay không, và bạn định nghĩa một vài quy tắc cố định như: "Nếu giao dịch xuất phát từ nước ngoài và có giá trị lớn hơn 100.000 đô thì đó là lừa đảo", đây là lập trình cụ thể. Máy tính không cần phân tích gì thêm ngoài việc tuân theo các quy tắc bạn đã đặt ra. Thì đây không phải là Machine Learning. Ngược lại, nếu bạn huấn luyện một mô hình AI dựa trên các dữ liệu giao dịch ngân hàng đã thu thập trong quá khứ, gồm cả giao dịch bình thường và lừa đảo, để mô hình tự học và tìm ra đặc điểm riêng biệt của chúng, thì đây là lập trình không cụ thể, hay Machine Learning
3. Deep Learning
Deep Learning (Học sâu) là một lĩnh vực con của Machine Learning, sử dụng các thuật toán lấy cảm hứng từ cấu trúc và chức năng của não người, được gọi là Mạng thần kinh nhân tạo (Artificial Neural Networks). Deep Learning đã đem lại nhiều thành tựu nổi bật trong AI, như ChatGPT và Mid Journey, đều là sản phẩm của Deep Learning.
4. Neural Network
Neural Network (Mạng thần kinh nhân tạo) là mô hình tính toán lấy cảm hứng từ cấu trúc não của con người, bao gồm các đơn vị tính toán gọi là neuron kết nối với nhau thành từng lớp. Trong nhiều tài liệu, người ta thường dùng hai thuật ngữ Deep Learning và Neural Network như nhau, nhưng thực chất, Deep Learning là lĩnh vực nghiên cứu, còn Neural Network là kiến trúc mô hình.
5. Data
Data (Dữ liệu) là các thông tin hoặc giá trị được thu thập từ nhiều nguồn khác nhau. Dữ liệu có thể tồn tại ở dạng thô (chưa qua xử lý) hoặc dạng tinh (đã qua xử lý). Dữ liệu tồn tại xung quanh chúng ta rất nhiều và ở muôn hình vạn trạng. Nhắn tin với bạn bè, đó là dữ liệu. Khi Bạn đi mua hàng và nhận được hoá đơn, đó cũng là dữ liệu. Những tấm ảnh bạn chụp cũng là dữ liệu, tuy nhiên để dữ liệu dạng hình ảnh trở nên hữu ích thì chúng ta cần thêm 1 vài bước xử lý nữa. À những kiến thức này được mình tham khảo từ những Video của anh Việt Nguyễn AI. Anh ấy là Senior AI Engineer tại Đức.
6. Dataset
Dataset (Tập dữ liệu) là tập hợp có cấu trúc của nhiều mẫu dữ liệu, được tổ chức và sắp xếp
để sử dụng cho một mục đích nhất định.
Thường là để huấn luyện và đánh giá một mô hình học máy hoặc một mô hình học sâu.
Ví dụ, Bạn có thể có dữ liệu về điểm thi của học sinh của một trường, mỗi một hàng tương ứng
với một học sinh, trường có bao nhiêu học sinh thì tập dữ liệu này sẽ có chừng ấy hàng.
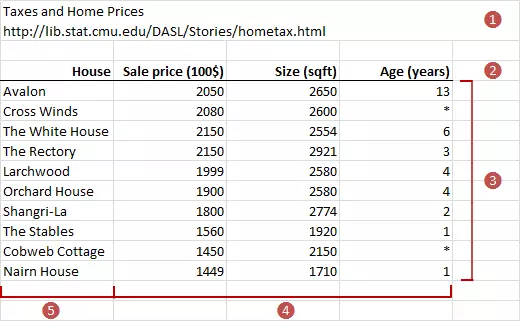
7. Feature
Feature (Đặc trưng) là các thuộc tính hay đặc điểm của dữ liệu mà mô hình sẽ sử dụng để học
hỏi và đưa ra dự đoán.
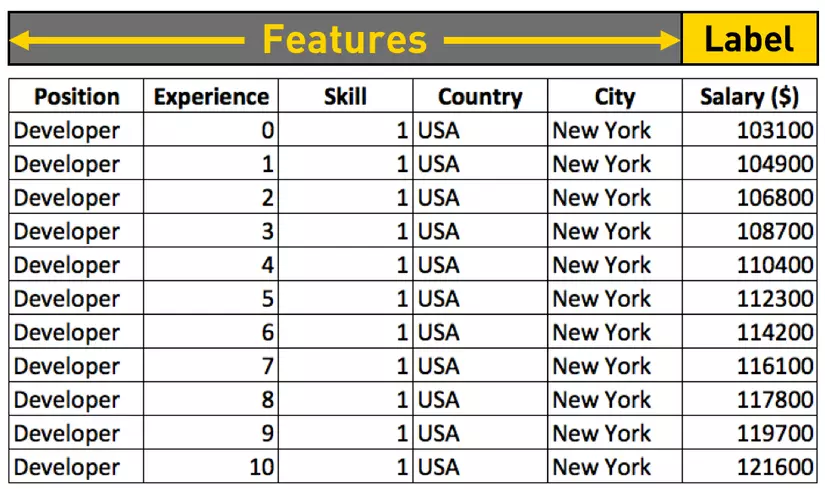 Thường trong các cột dữ liệu dạng Bảng, thì ngoài các cột mà mô hình phải đưa ra dự đoán, thì
mỗi một cột còn lại, sẽ là một Feature.
Thường trong các cột dữ liệu dạng Bảng, thì ngoài các cột mà mô hình phải đưa ra dự đoán, thì
mỗi một cột còn lại, sẽ là một Feature.
8. Label
Label (Nhãn) là thông tin mô tả về dữ liệu, là kết quả mà mô hình cần dự đoán.
Ví dụ chúng ta có một tập dữ liệu dùng để huấn luyện mô hình dự đoán nhiệt độ ngoài trời.
Trong tập dữ liệu này chúng ta sẽ có rất nhiều cột với các thông tin khác nhau như: Ngày, độ
ẩm, lượng mưa, nhiệt độ. Cột nhiệt độ chính là Label.
#  Hiểu một cách đơn giản, tập dữ liệu có Label là gì, thì mô hình được huấn luyện với tập dữ liệu
này, có thể dự đoán được giá trị của Label đó.
Hiểu một cách đơn giản, tập dữ liệu có Label là gì, thì mô hình được huấn luyện với tập dữ liệu
này, có thể dự đoán được giá trị của Label đó.
9. Sample
Sample (Mẫu) là một điểm dữ liệu cụ thể trong tập dữ liệu. Mỗi mẫu bao gồm các đặc trưng và
nhãn tương ứng.
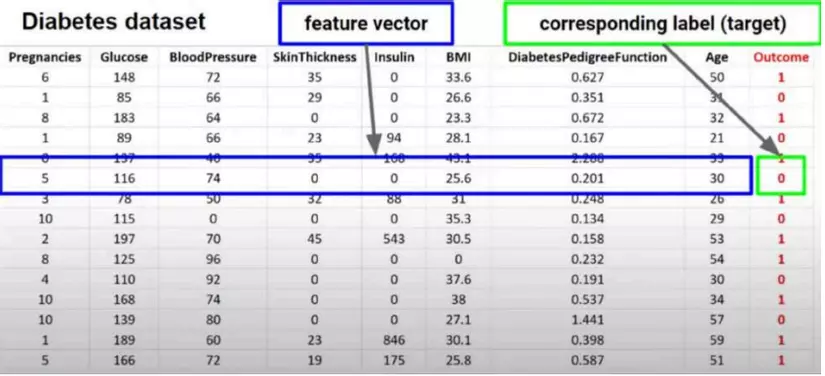 Ví dụ trong dữ liệu ta thường hay gặp nhất - dữ liệu dạng bảng thì một mẫu chính là một hàng
của tập dữ liệu này.
Ví dụ trong dữ liệu ta thường hay gặp nhất - dữ liệu dạng bảng thì một mẫu chính là một hàng
của tập dữ liệu này.
10. Model
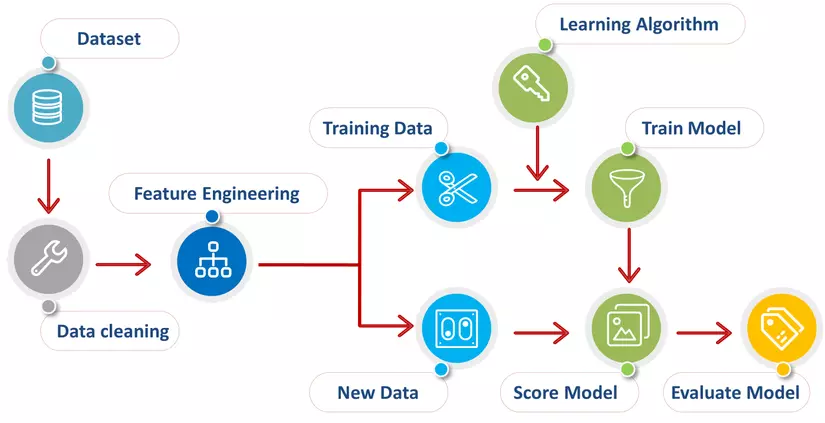 Model (Mô hình) là một thuật toán hoặc hệ thống mà thông qua quá trình huấn luyện, học hỏi
từ dữ liệu để có thể đưa ra dự đoán.
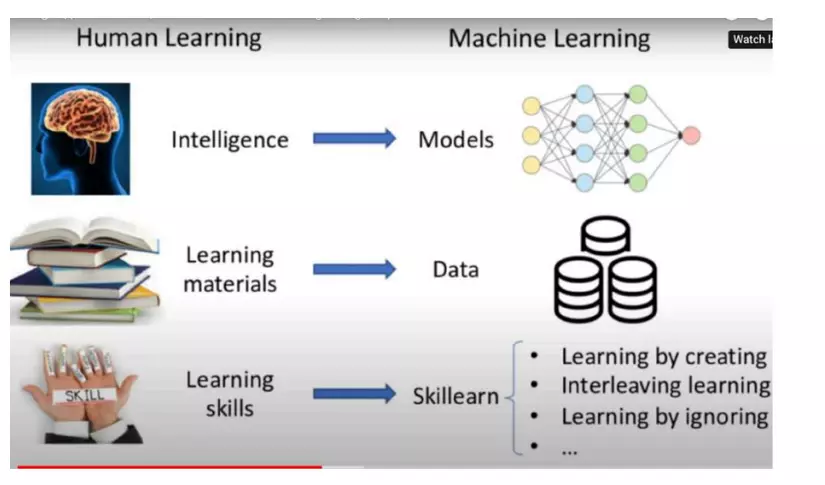
Cách mà mô hình được huấn luyện thông qua dữ liệu chính là sự mô phỏng cách mà con
người học thông qua sách vở.
Model (Mô hình) là một thuật toán hoặc hệ thống mà thông qua quá trình huấn luyện, học hỏi
từ dữ liệu để có thể đưa ra dự đoán.
Cách mà mô hình được huấn luyện thông qua dữ liệu chính là sự mô phỏng cách mà con
người học thông qua sách vở.
11. Data Labeling
Data Labeling (Gắn nhãn dữ liệu) là quá trình đánh dấu dữ liệu thô để mô hình có thể dựa vào
đó học và đưa ra dự đoán.
 Những thông tin được đánh dấu này cũng chính là câu trả lời mà mình muốn mô hình dựa vào
để đưa ra dự đoán
Những thông tin được đánh dấu này cũng chính là câu trả lời mà mình muốn mô hình dựa vào
để đưa ra dự đoán
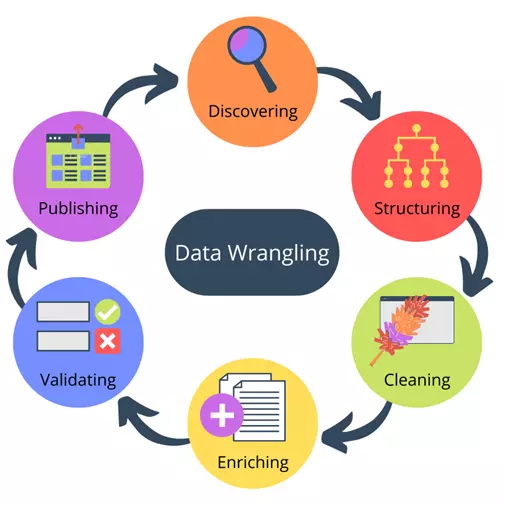
12. Data Wrangling
Data Wrangling (Xử lý dữ liệu) là quá trình thu thập, làm sạch và xử lý dữ liệu từ nhiều nguồn
khác nhau thành dạng có cấu trúc và dễ sử dụng hơn.
13. Data Preprocessing
Data Preprocessing (Tiền xử lý dữ liệu) là quá trình chuẩn bị và xử lý dữ liệu để áp dụng các
thuật toán học máy hoặc phân tích dữ liệu.
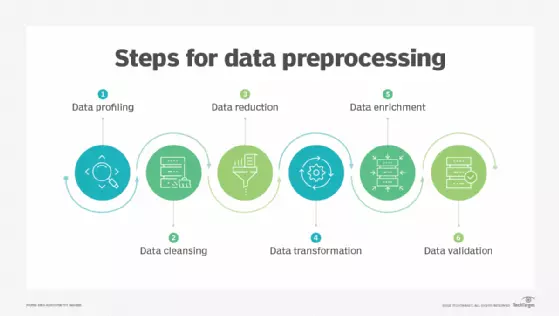
14. Data Augmentation
Data Augmentation (Tăng cường dữ liệu) là quá trình tạo ra dữ liệu mới từ bộ dữ liệu gốc,
giúp tăng độ phong phú của dữ liệu và cải thiện khả năng học của mô hình.

15. Supervised Learning
Supervised Learning (Học có giám sát) là một nhóm các thuật toán sử dụng dữ liệu có nhãn
để mô hình hóa mối quan hệ giữa đầu vào và nhãn của chúng. Đây là một trong những thuật
toán phổ biến nhất trong học máy.
Ví dụ khi ta xây dựng mô hình để dự đoán nhiệt độ ngoài trời hay dự đoán một người có bị
Covid hay không, thì đấy chính là những ví dụ của thuật toán học có giám sát
16. Unsupervised Learning
Unsupervised Learning (Học không giám sát) sử dụng dữ liệu không được đánh nhãn để mô
hình hóa cấu trúc hoặc thông tin ẩn trong dữ liệu.
Ví dụ cơ bản và phổ biến nhất cho thuật toán học không giám sát, đó chính là bài toán phân
cụm. Khi chúng ta phân toàn bộ tập dữ liệu thành K cụm khác nhau, sao cho các điểm dữ liệu
nằm trong cùng một cụm sẽ tương ứng nhau và các điểm dữ liệu trong cụm này sẽ khác xa với
những điểm dữ liệu ở cụm khác.
17 Reinforcement Learning
Reinforcement Learning (học tăng cường) là nhóm các thuật toán học hỏi bằng cách tương
tác với môi trường xung quanh và đưa ra quyết định dựa trên phản hồi mà chúng nhận được từ
môi trường xung quanh.
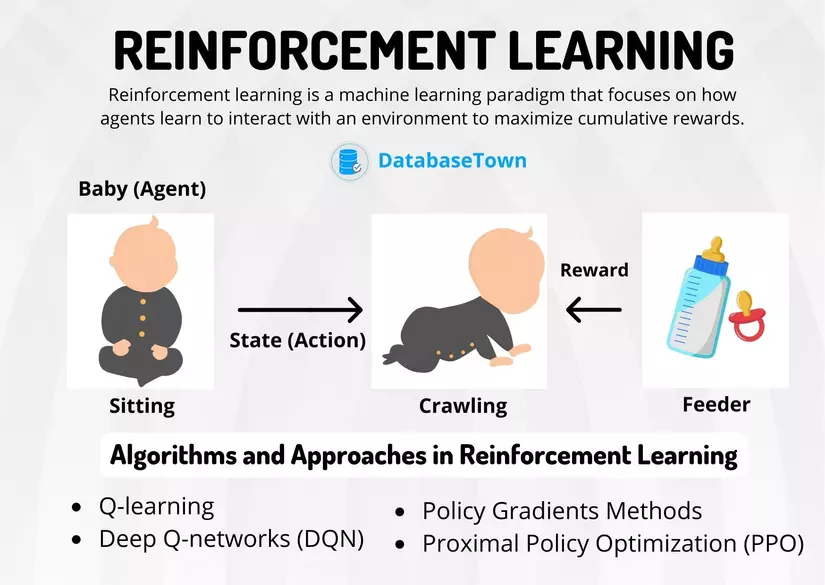 Nếu trong học có giám sát và học không giám sát. Đối tượng mà chúng ta huấn luyện được gọi
là mô hình. Thì trong học tăng cường, đối tượng mà chúng ta huấn luyện được gọi là tác nhân
Ví dụ, một đứa bé và đốm lửa trong phòng, đứa bé là tác nhân và đốm lửa là môi trường.
Khi đưa bé càng lại gần đốm lừa, có cảm giác ấm áp.
Tuy nhiên khi lại quá gần, nó sẽ có cảm giác bị bỏng hay quá nóng. Đây chính là một phản hồi
khác mà môi trường gửi lại cho tác nhân.
Từ những phản hồi mà môi trường phản hồi, tác nhân sẽ điều chỉnh hành vi cho phù hợp.
Nếu trong học có giám sát và học không giám sát. Đối tượng mà chúng ta huấn luyện được gọi
là mô hình. Thì trong học tăng cường, đối tượng mà chúng ta huấn luyện được gọi là tác nhân
Ví dụ, một đứa bé và đốm lửa trong phòng, đứa bé là tác nhân và đốm lửa là môi trường.
Khi đưa bé càng lại gần đốm lừa, có cảm giác ấm áp.
Tuy nhiên khi lại quá gần, nó sẽ có cảm giác bị bỏng hay quá nóng. Đây chính là một phản hồi
khác mà môi trường gửi lại cho tác nhân.
Từ những phản hồi mà môi trường phản hồi, tác nhân sẽ điều chỉnh hành vi cho phù hợp.
18. Classification
Phân loại là một thuật toán có giám sát, trong đó kết quả đầu ra, hay còn gọi là nhãn, là một giá trị rời rạc. Ví dụ, trong mô hình phân loại email, ta xác định xem một email có phải là spam hay không. Kết quả đầu ra của mô hình chỉ có hai giá trị: một là email spam, hai là email bình thường. Đây là các giá trị rời rạc. Ngoài ra, cũng có nhiều ví dụ khác về mô hình phân loại như:
- Mô hình dự đoán xem một người có bị ung thư không,
- Mô hình xác định xem một giao dịch có phải là lừa đảo không,
- Hay mô hình phân loại hình ảnh đầu vào thuộc loại động vật nào như chó, mèo, gà, lợn,
v.v.
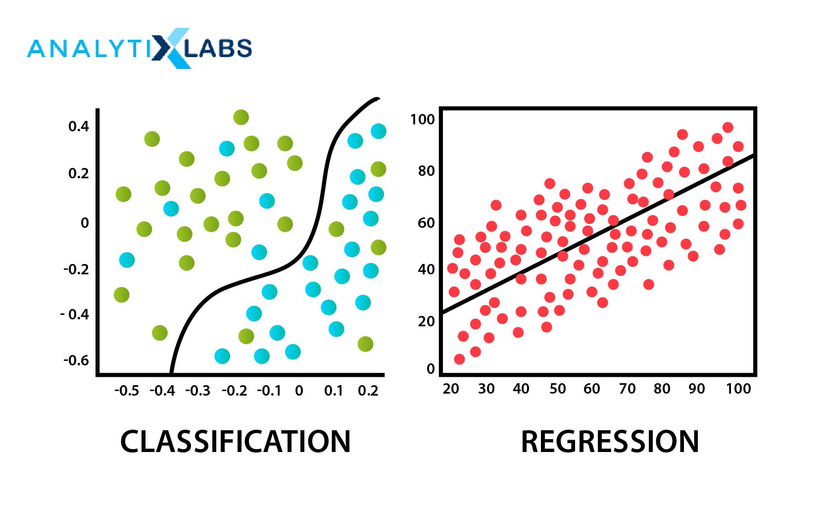
19. Regression
Regression (Hồi quy) là một thuật toán có giám sát khác, trong đó kết quả đầu ra là một giá trị liên tục. Ví dụ, khi xây dựng một mô hình dự đoán giá nhà, giá của một căn nhà có thể là một số dương bất kỳ và thuộc vào một dải liên tục. Điểm khác biệt giữa bài toán phân loại và bài toán hồi quy là trong bài toán phân loại, ta có thể đếm được số lượng giá trị đầu ra (chẳng hạn, hai giá trị trong bài toán email spam), còn trong bài toán hồi quy, kết quả đầu ra có thể có vô số giá trị khác nhau.
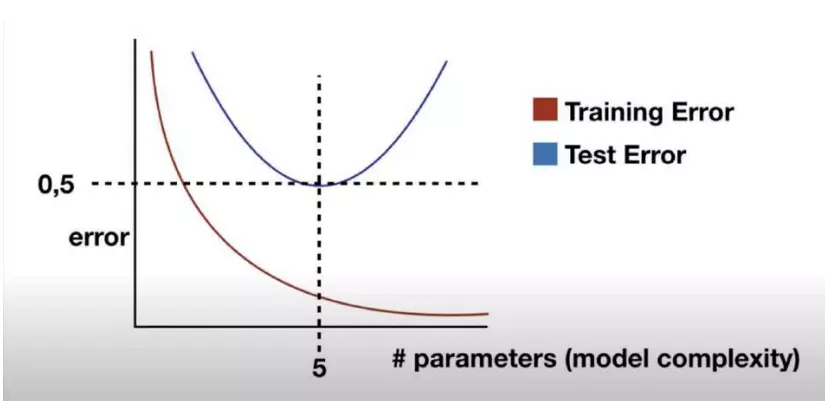
20. Overfitting
Overfitting (quá khớp) là hiện tượng xảy ra khi mô hình học quá chi tiết từ dữ liệu huấn luyện, bao gồm cả nhiễu và những đặc trưng không quan trọng. Điều này dẫn đến hệ quả là mô hình hoạt động rất tốt trên dữ liệu huấn luyện nhưng lại hoạt động rất kém trên dữ liệu mới. Nó giống như việc các bạn học toán bằng cách học thuộc lòng. Nếu các bạn làm những bài cũ mà đã từng gặp rồi thì sẽ làm rất nhanh và được điểm cao. Tuy nhiên, nếu thầy cô thay đổi đề một chút, các bạn sẽ không biết cách làm.
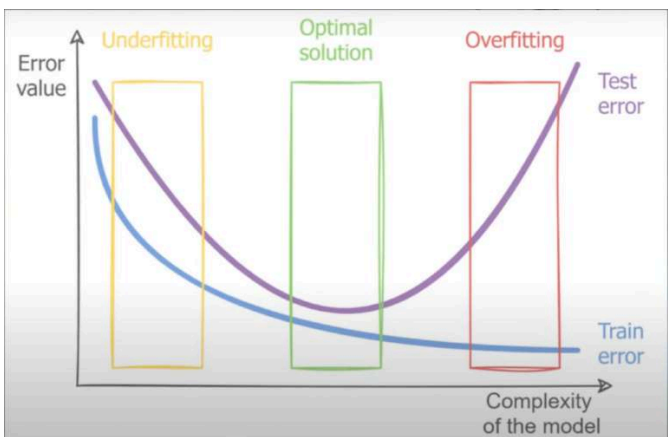
21. Underfitting
Ngược lại với Overfitting là Underfitting (chưa khớp). Đây là hiện tượng xảy ra khi mô hình
quá đơn giản để nắm bắt được những đặc trưng quan trọng của dữ liệu huấn luyện. Hệ quả là
mô hình hoạt động rất tồi cả trên dữ liệu huấn luyện lẫn dữ liệu mới.
Điều này cũng giống như việc cố gắng dạy học sinh lớp 5 kiến thức của lớp 10. Trong quá trình
học, học sinh cũng làm bài tồi, và trong quá trình thi cũng vậy.
22. Imbalance Dataset
Imbalance Dataset (Tập dữ liệu mất cân bằng) là tập dữ liệu dùng cho bài toán phân loại mà số lượng mẫu của mỗi lớp không đều. Có lớp thì có quá nhiều mẫu, trong khi có lớp lại có quá ít mẫu. Ví dụ, trong một tập dữ liệu về bệnh nhân ung thư, có thể có 99% là bệnh nhân khỏe mạnh và chỉ 1% là bệnh nhân bị ung thư. Đây là một ví dụ của tập dữ liệu mất cân bằng. Những tập dữ liệu như vậy sẽ khiến cho quá trình huấn luyện mô hình trở nên khó khăn hơn, đặc biệt là với những lớp thiểu số.
23. Oversampling
Oversampling (Tăng cường mẫu) là quá trình làm tăng số lượng mẫu của lớp thiểu số bằng cách tạo ra thêm những bản sao hoặc mẫu tổng hợp từ những mẫu đã có. Ngược lại với oversampling là
24. Undersampling
Ngược lại với Oversampling (tăng cường mẫu), Undersampling (giảm mẫu) là quá trình làm giảm số lượng mẫu của lớp đa số, thường được thực hiện bằng cách loại bỏ ngẫu nhiên một vài mẫu từ lớp đa số.
25. Class hay Category
Đây là thuật ngữ dùng để phân loại. Ví dụ, trong bài toán phân loại xem một email có phải là email spam hay không. Chúng ta sẽ có hai lớp: một là lớp email bình thường và hai là lớp email spam. Hoặc chúng ta cũng có thể gọi là 2 loại email: một là loại email bình thường và hai là loại email spa