Lược dịch lại từ: https://architecturenotes.co/redis/
Redis là gì ?
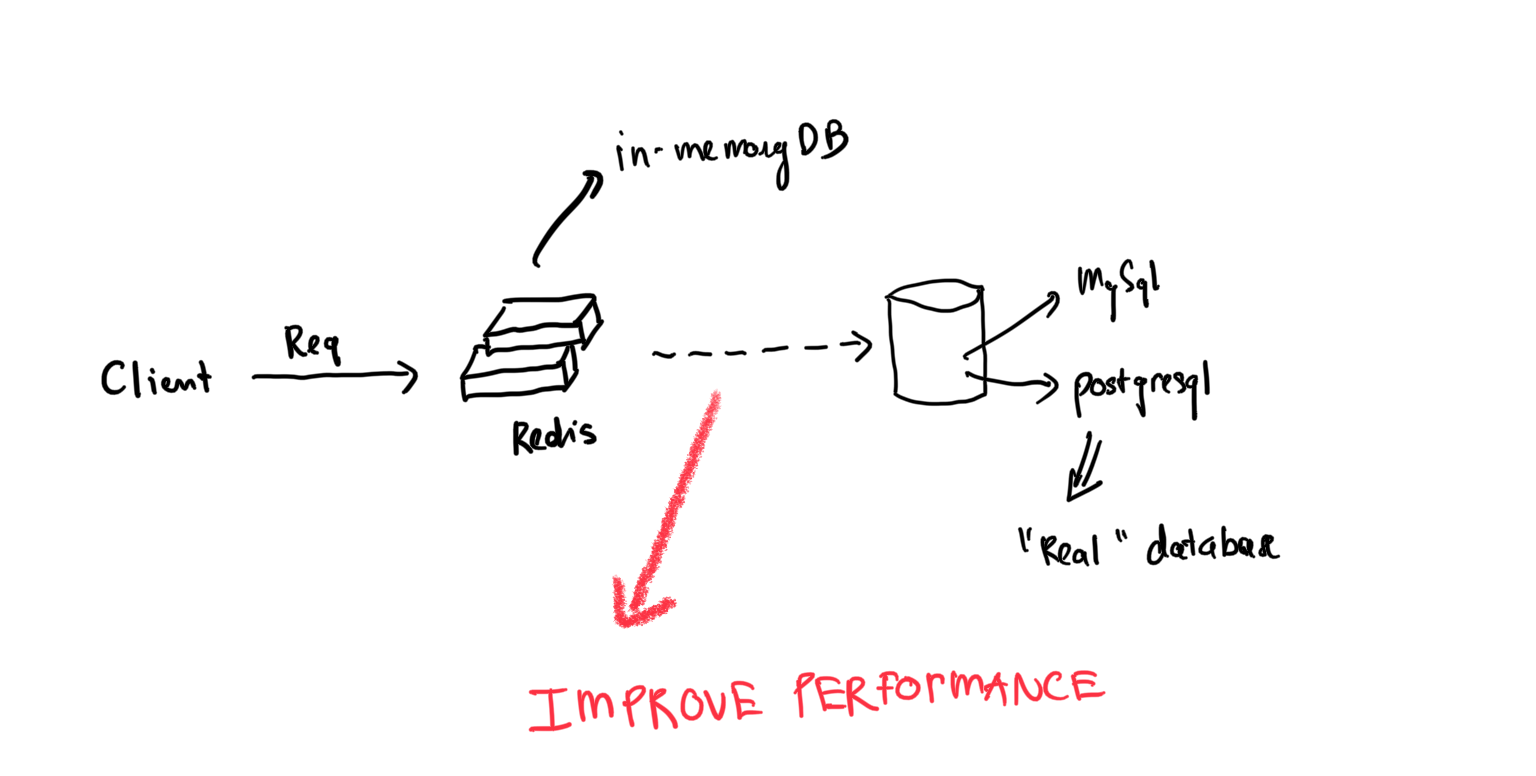
Redis là một in-memory database, lưu trữ dữ liệu dưới dạng key - value.
Redis thường được "đặt phía trước" main database (MySQL, PostgreSQL) để cải thiện hiệu năng hệ thống.
Dữ liệu thường được lưu trong redis là:
- Dữ liệu ít thay đổi nhưng được truy xuất thường xuyên
- Dữ liệu ít quan trọng và vẫn trong quá trình phát triển.
Redis Architectures
Single Redis Instance
Đơn thuần là chỉ sử dụng duy nhất 1 Redis instance hoặc cluster. Cách làm này rất dễ triển khai xong nhược điểm dễ thấy nhất đó là nếu instance duy nhất này bị "sập" thì client sẽ không thể truy cập vào cache dẫn tới hiệu năng của hệ thống bị ảnh hưởng.
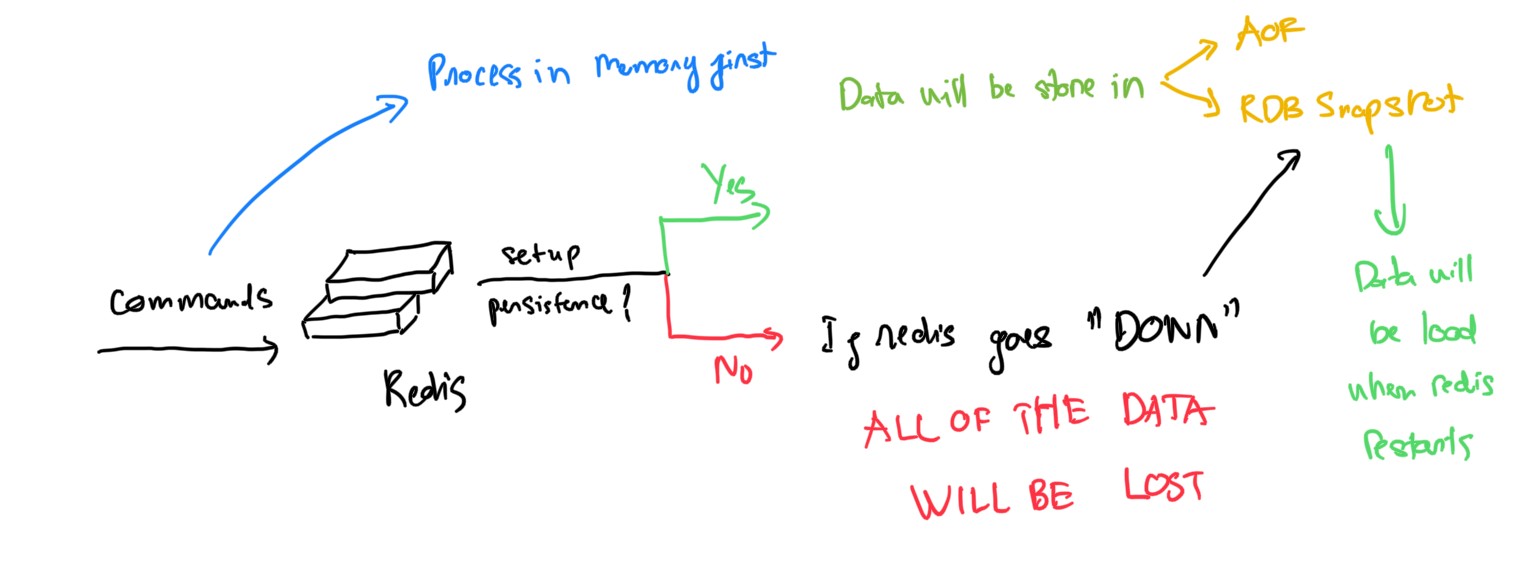
Các lệnh gửi đến redis sẽ được xử lí ở trong memory. Nếu setup persistence cho redis thì sẽ có các tiến trình con chạy trong những khoảng thời gian cố định để lưu dữ liệu của redis vào RDB snapshot hoặc AOF (append-only files)
Nếu không lưu dữ liệu vào snapshot hoặc AOF thì khi redis "sập" toàn bộ dữ liệu sẽ mất sạch, ngược lại nếu lưu thì khi redis restarts thì dữ liệu sẽ được phục hồi trở lại.
Redis HA (High availability)
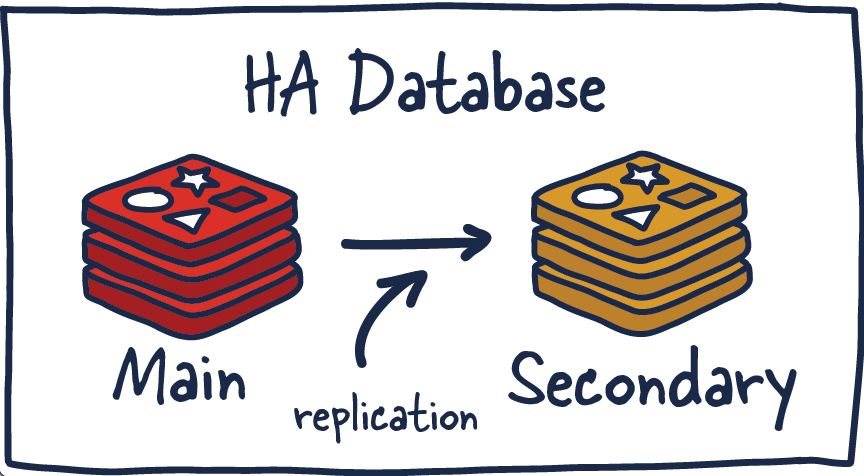
Triển khai nhiều redis instances hơn và đồng thời tiến hành đồng bộ hoá dữ liệu giữa main instance với các instances khác.
Điều này đảm bảo hệ thống tránh được tình trạng "có một điểm chịu lỗi duy nhất". Từ đó:
- Tăng tính sẵn có của hệ thống
- Biết được hệ thống fail ở điểm nào để có biện pháp phục hồi thích hợp
Redis Replication
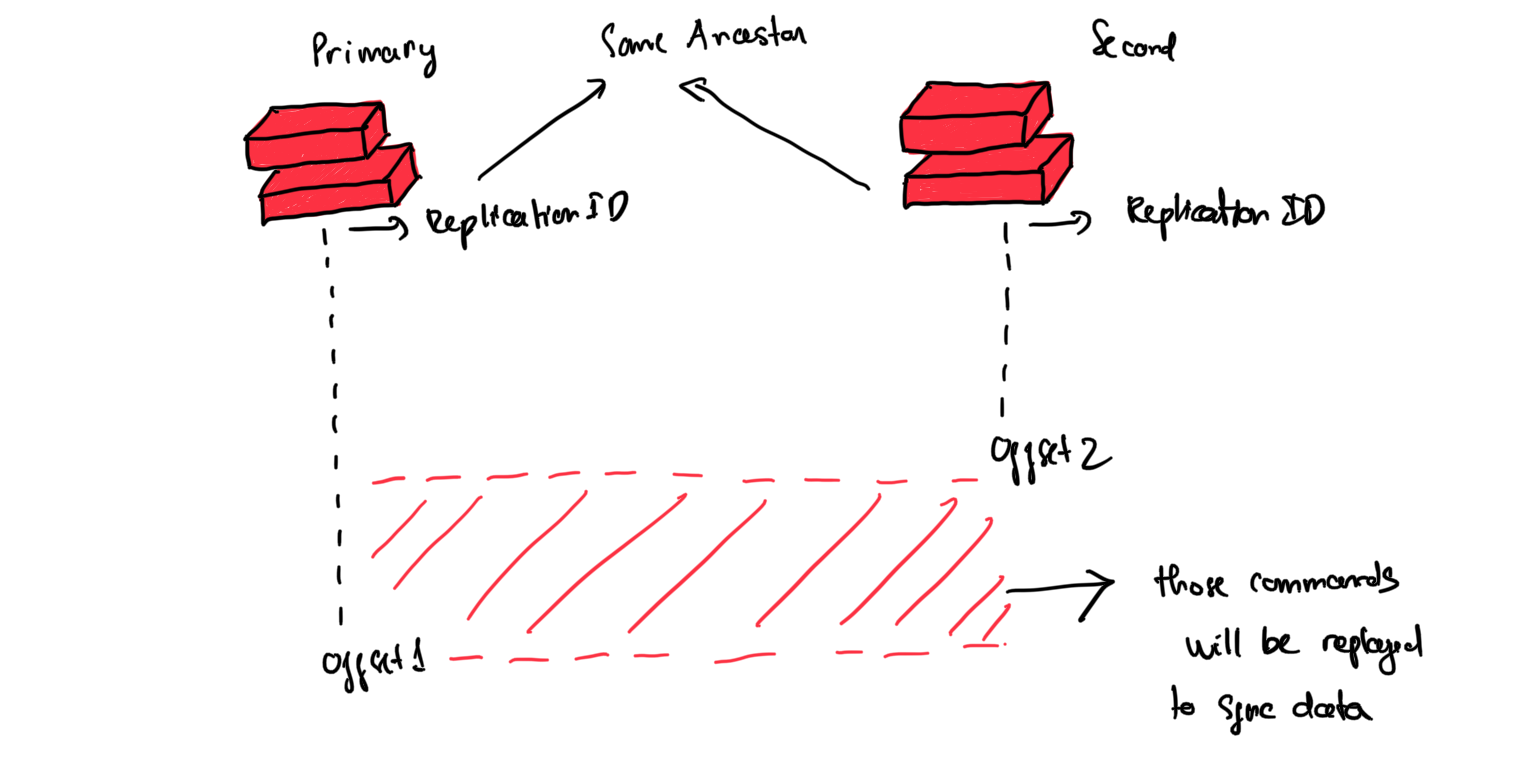
Mọi main instance redis đều có 2 thuộc tính là offset và Replication ID.
Hai thuộc tính này giúp ta tìm ra thời điểm bắt đầu sync data là từ lúc nào. Offset sẽ tự động tăng lên sau mỗi action diễn ra trên main redis instance
Cụ thể như sau: khi một redis instance có offset nhỏ hơn so với offset của main instance thì quá trình sync data sẽ diễn ra cho đến khi 2 offset bằng nhau thì thôi
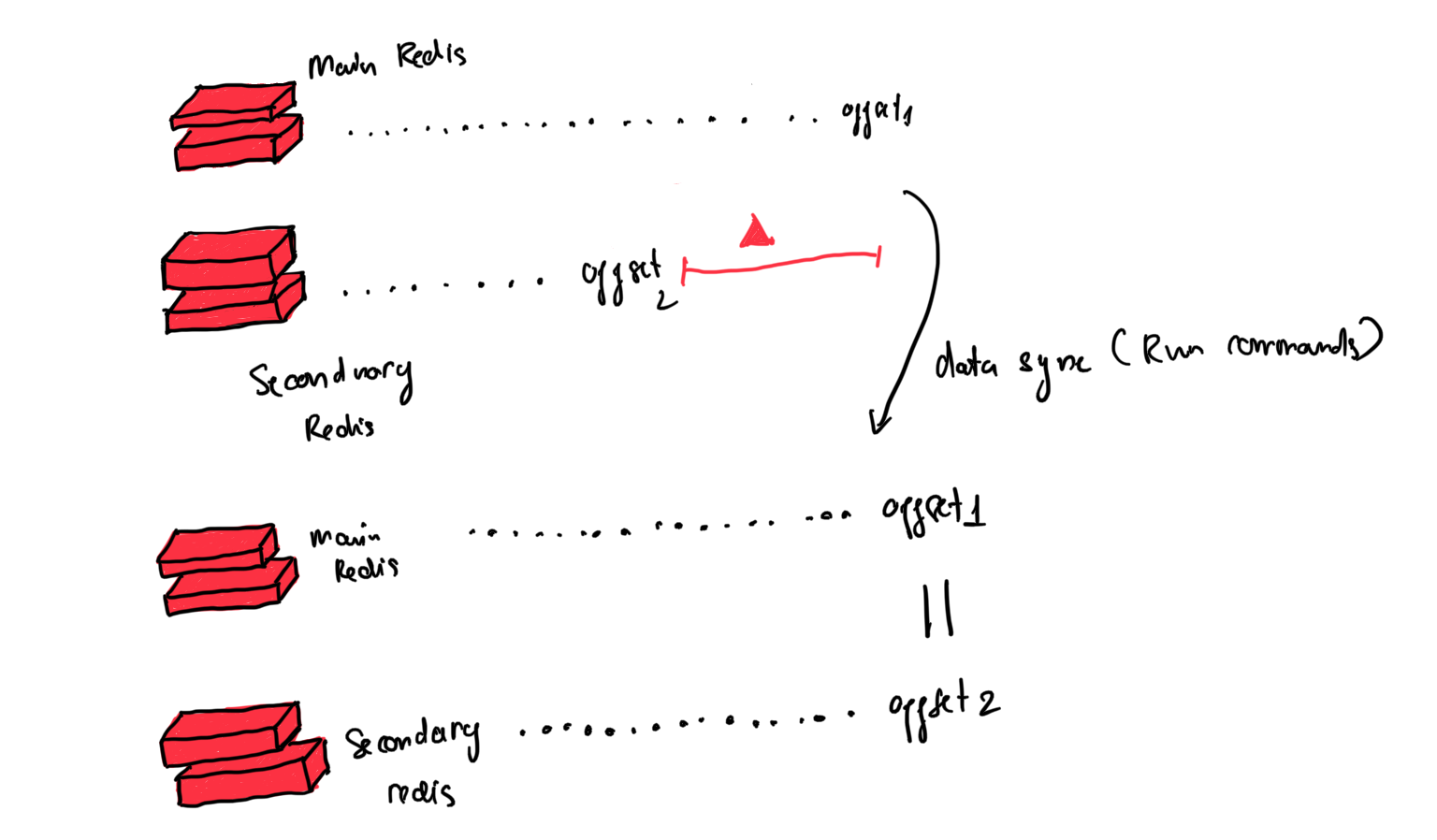
Nếu ở 2 instances ta đều không biết offset thì sẽ diễn ra quá trình full synchronization. Primary instance sẽ tạo ra RDB snapshot và gửi đến cho replica.
Trong quá trình gửi snapshot, main instance sẽ buffer mọi update commands tính từ thời điểm tạo snapshot cho đến offset hiện thời của nó.
Vai trò của replication ID ở đây đó là giúp triển khai partial synchroinization thay vì fully synchronization.
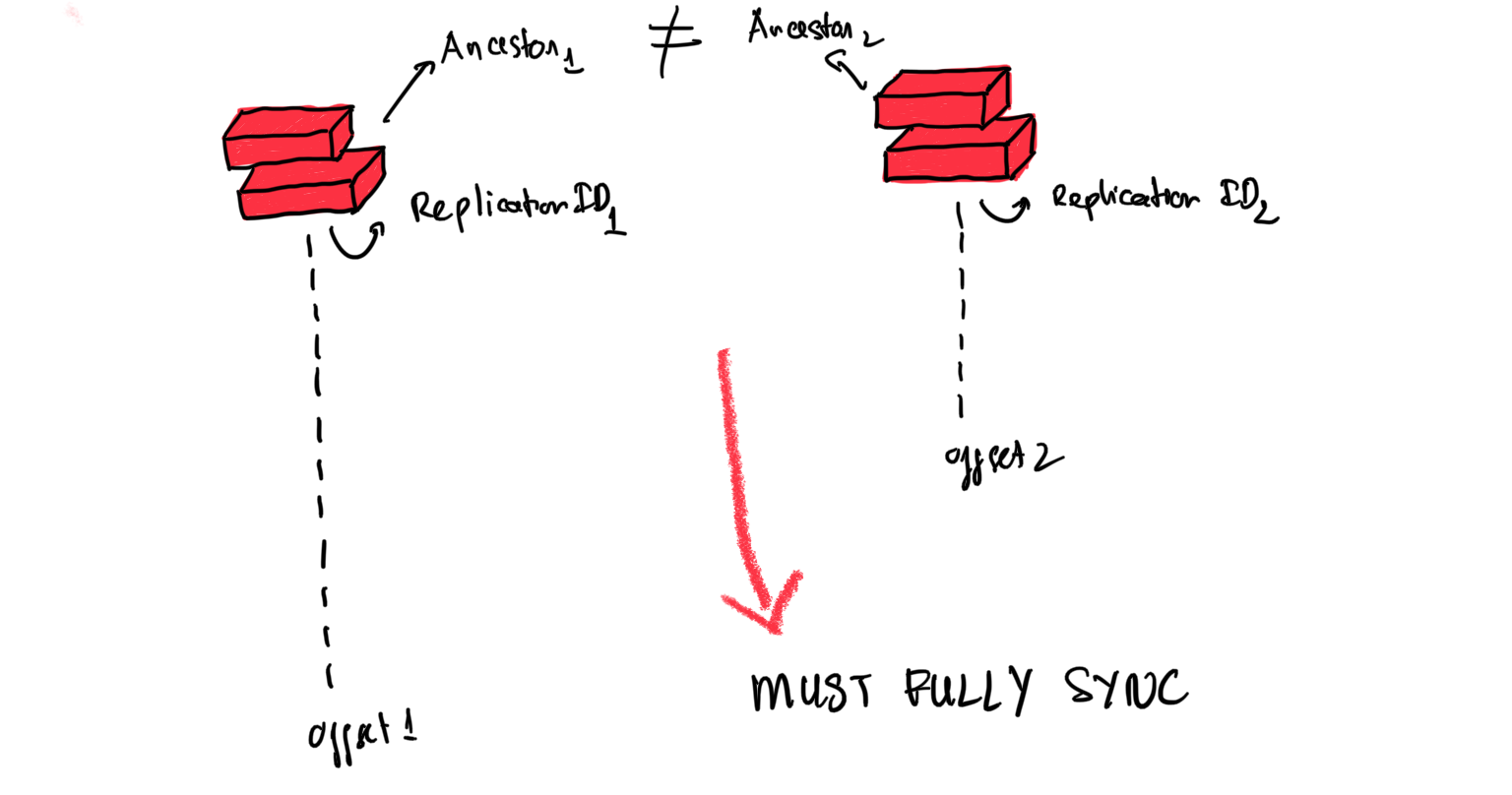
Cụ thể như sau, khi một instance trở thành primary instance mới thì relication ID mới sẽ được sinh ra, đây có thể coi như ID của ancestor instance. Khi 2 instance có chung một ancestor thì quá trình sync data chỉ diễn ra với những phần chênh lệch được xác định dựa trên offset
Trong trường hợp replication ID khác nhau thì sẽ phải sync toàn bộ data giữa 2 instance.
Redis Cluster
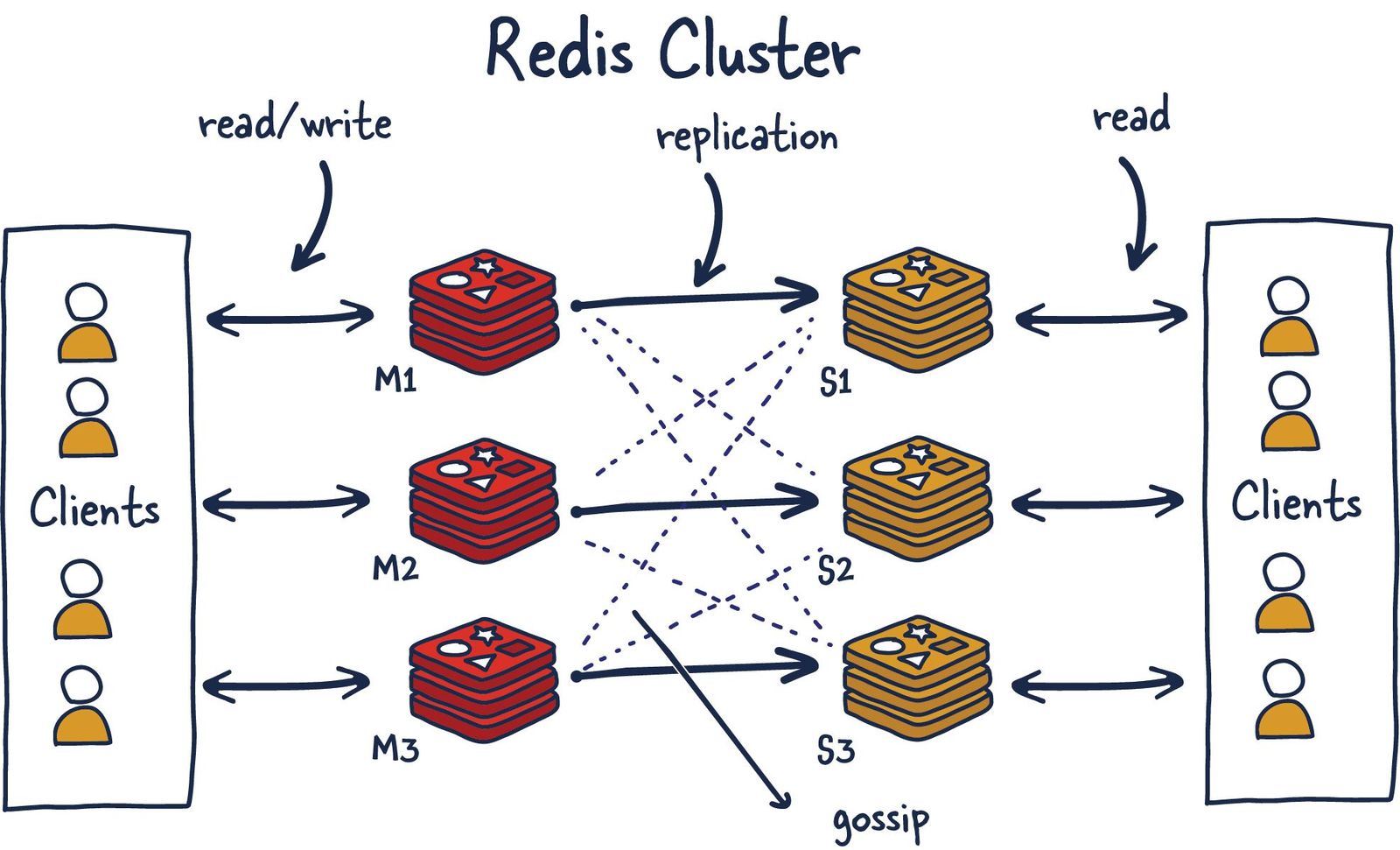
Việc chỉ sử dụng duy nhất một instance ngoài nguy cơ single point failover còn có thể dẫn đến tình trạng instance có thể bị quá tải về mặc dung lượng do tài nguyên của server luôn là có hạn.
Giải pháp ở đây đó là áp dụng horizontal scaling cho cache layer như hình minh hoạ ở trên. Tuy nhiên vấn đề đặt ra ở đây đó là "cách thức" lưu trữ dữ liệu trên các shards (ở đây mỗi instance trong cluster được coi là một shard).
Việc lưu trữ dữ liệu trên nhiều máy được gọi là sharding. Để tìm nơi lưu trữ cho key ta sẽ thực hiện các bước như sau:
- Sử dụng một
hash functioncho trước để băm key - Modulo kết quả dựa trên tổng số shard:
mod(number_of_shards)
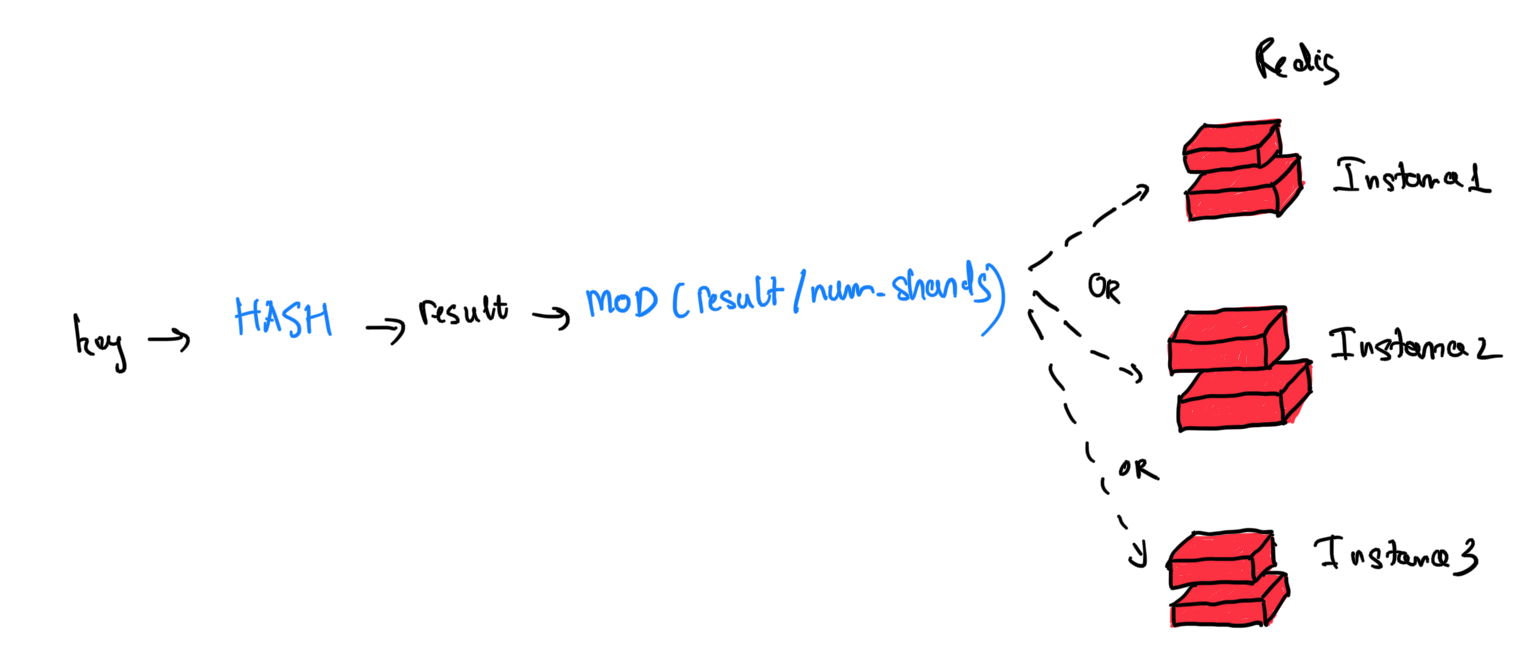
Với công thưc trên thì key sẽ luôn được lưu trữ ở một shard duy nhất.
Tuy nhiên sẽ có một vấn đề xảy ra ở đây đó là khi ta thêm hoặc bớt một hoặc nhiều shards mới vào cluster. Khi đó ta cần phải resharding.
Giả sử với key là foo, ban đầu nó được lưu ở shard-0 thế nhưng sau khi thêm một shard mới vào cluster thì vị trí của nó phải là ở shard-5. Lúc này đòi hỏi quá trình di trú dữ liệu giữa các shard. Việc này sẽ tốn chi phí đồng thời sẽ ảnh hưởng đến tính sẵn có của hệ thống.
Một giải pháp để giải quyết vấn đề trên đó là Hashslot. Lúc này dữ liệu sẽ được map với các hashslot.
Có tất cả 16K hashslot. Khi thêm shard mới thay vì "trực tiếp" di trú dữ liệu ta sẽ di trú các hashslots dọc theo các shards. Việc này đơn giản hơn so với di trú dữ liệu trực tiếp rất nhiều.
Ví dụ:
Ta có 2 shards: M1, M2 lần lượt chứa các slots (0 - 8191) và (8192 - 16383). Với key foo ta tiến hành "băm" và mod nó với số lượng các slots (16K), giả sử key được lưu ở shard M2. Ta thêm mới một shards M3.
Lúc này hashslots sẽ được phân bổ lại như sau:
M1: 0 - 5460 M2: 5461 - 10922 M3: 10923 - 16383
khi đó sẽ có những keys ban đầu được lưu ở M1 nay sẽ chuyển qua M2, nhưng trên thực tế ta chỉ di chuyển các slots từ shard này sang shard kia mà thôi. Điều này sẽ giúp ta tránh được việc phải "băm lại" các keys để biết keys sẽ được lưu ở shard nào.
Gossiping
Redis cluster sử dụng Gossiping để xác định cluster 's health. Như hình mình hoạ phía trên ta thấy rằng có 3 nodes M và 3 nodes S. Các nodes này sẽ tương tác với nhau liên tục để đảm bảo rằng các primary nodes luôn healthy. Khi có đủ số lượng nodes nhất định quyết định rằng sẽ thay thế một node nào đó (VD: M1) thì secondary node (VD: S1) sẽ được sử dụng để thay thế M1.
Số lượng nodes tham gia vào việc quyết định trên hoàn toàn có thể được configure.
Việc configure này nếu không được thực hiện chính xác sẽ dẫn đến tình trạng 2 "phe" phản đối và đồng ý cân bằng nhau về số lượng dẫn tới cluster rơi vào tình trạng bị "chia cắt".
Hiện tượng trên được gọi là split brain
Do đó nên một cluster thường có số lẻ các nodes, mỗi node sẽ có 2 replicas
Redis Persistence Models
Trong thực tế redis có thể được sử dụng cho nhiều mục đích lưu trữ khác nhau. Nếu bạn chỉ sử dụng redis như cache hoặc cho mục đích real-time analytics thì việc mất data bên trong redis cũng không phải vấn đề quá quan trọng.
Tuy nhiên nếu muốn dữ liệu bên trong Redis không biến mất ta cần phải hiểu Redis lưu trữ dữ liệu của nó như thế nào.
No Persistence
Đây là trường hợp ta disable Persistence. Đây là cách nhanh nhất để chạy Redis tuy nhiên nó lại không đảm bảo lợi ích về lâu về dài.
RDB files
RDB (Redis Database): RDB persistence sẽ được thực thi tại những thời điểm nhất định (cách nhau những khoảng thời gian cố định), từ đó tạo ra các snapshots và lưu snapshots vào RDB.
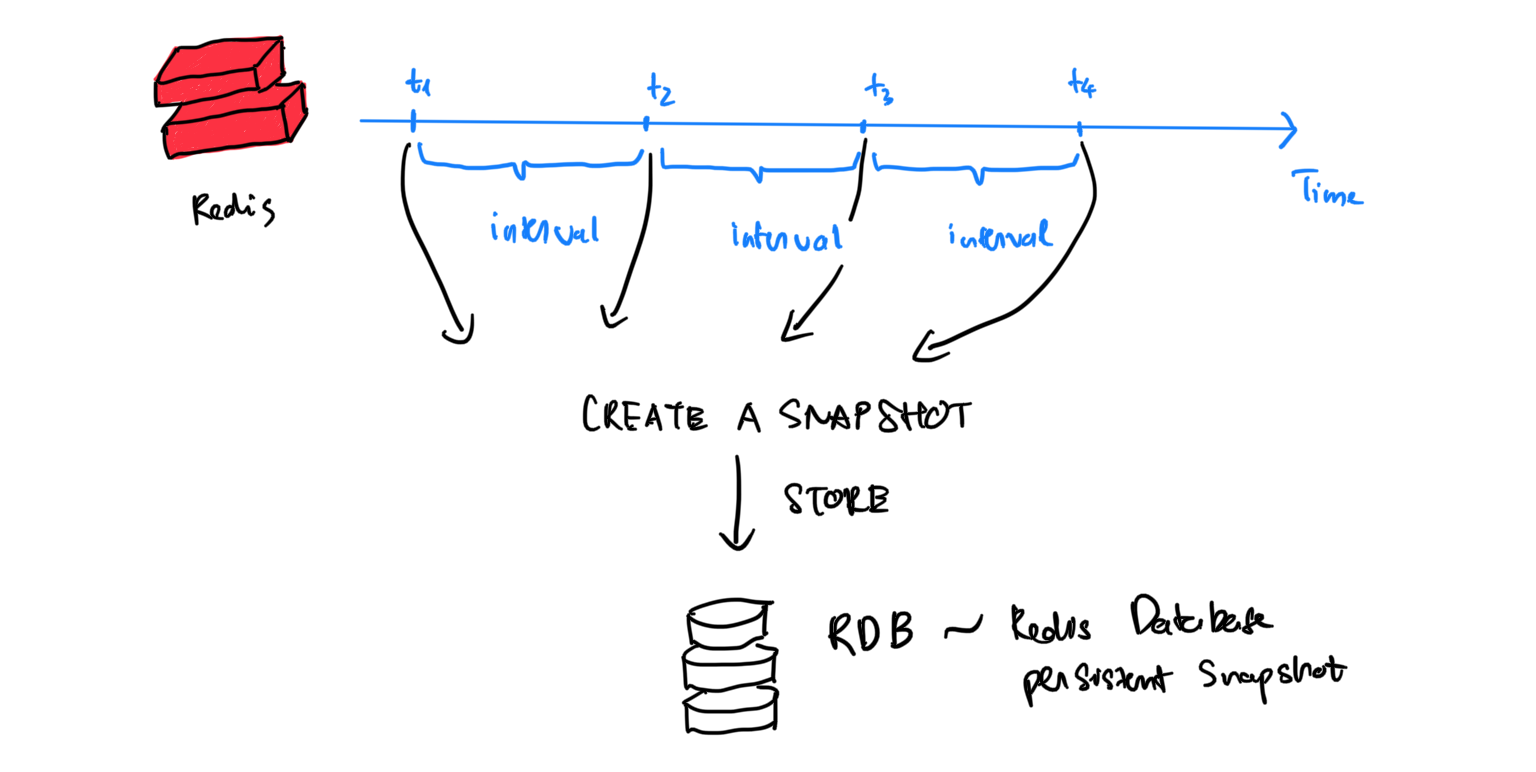
Cách làm này có những nhược điểm sau:
- Dữ liệu giữa các snapshots sẽ bị mất
- Nếu tiến hành chạy một tiến trình khác song song với tiến trình chạy redis hiện thời thì sẽ tốn tài nguyên, ảnh hưởng đến hiệu năng của main instance.
AOF
AOF (Append only Files): ở cách làm này ta sẽ log lại toàn bộ các write operation commands mà redis instance nhận được, các commands này sẽ được chạy lại khi instance được khởi động
Cách làm này chặt chẽ hơn so với RDB ở chỗ không xảy ra tình trạng mất data giữa các snapshot như RDB, ở đây ta chỉ lưu lại log của các command chứ không thực thi nên dữ liệu chưa được lưu lại hoàn toàn.
Khi instance được khởi động, các log commands này sẽ được thực thi.
Nếu có thể ta cũng sẽ đưa các log commands này lưu trữu vào disk (do đó cách làm này tốn disk hơn RDB)
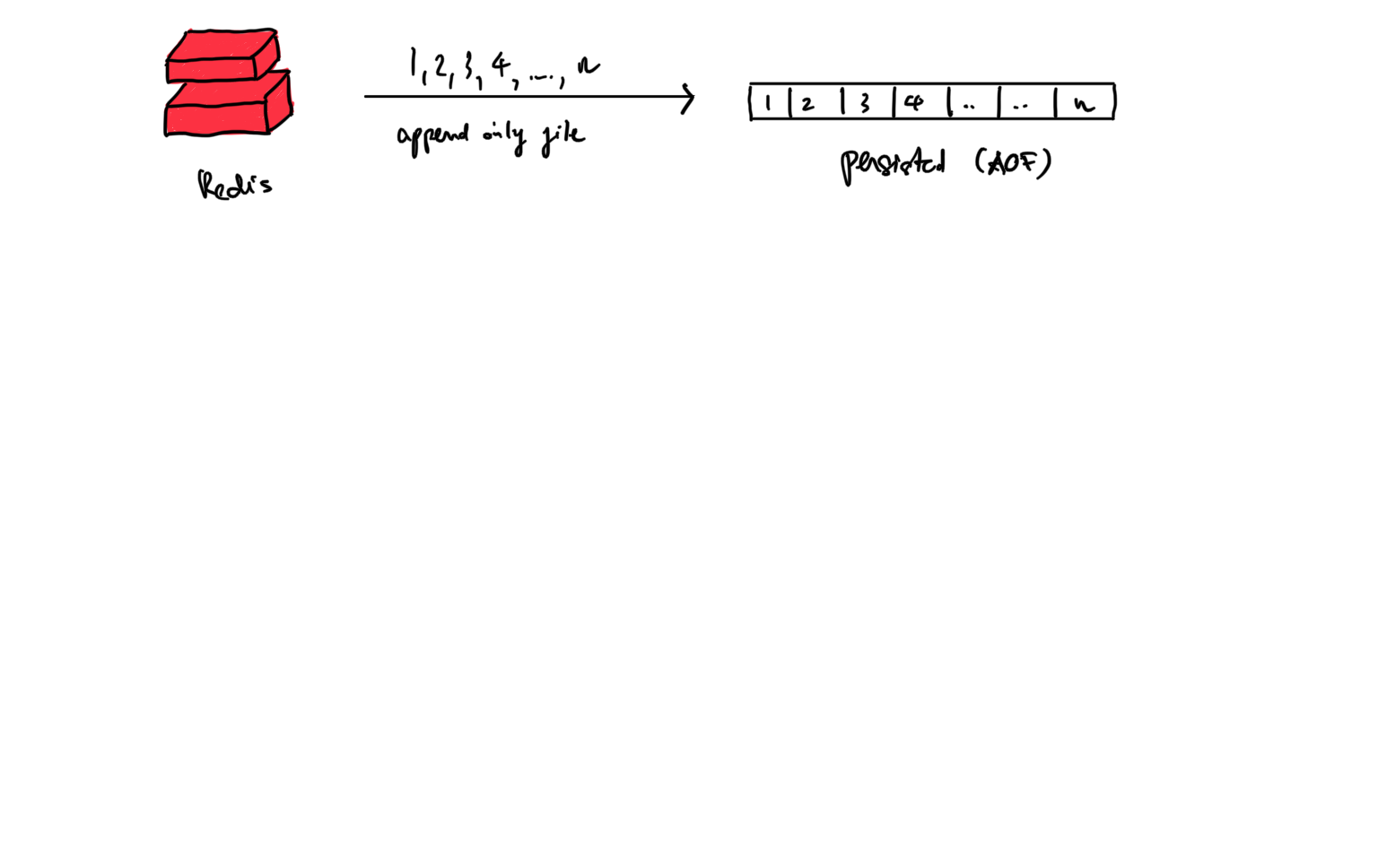
Quá trình restore lại dữ liệu sẽ diễn ra như sau:
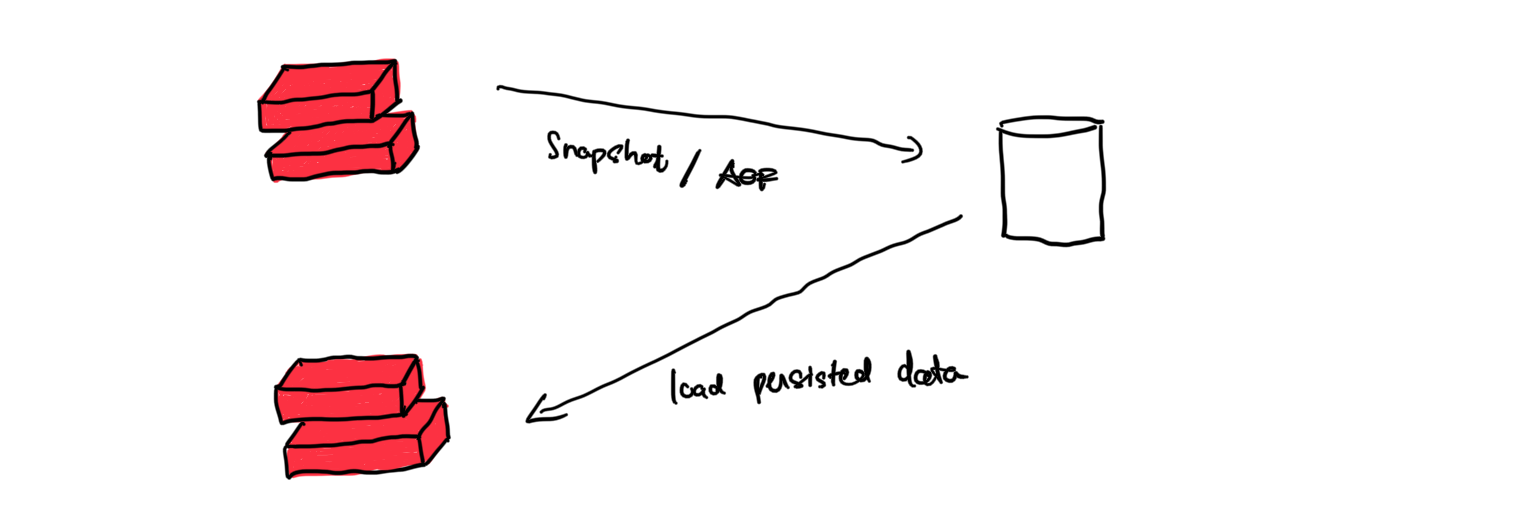
Why not both ?
Ta hoàn toàn có thể kết hợp RDB và AOF. Tuy nhiên để đảm bảo tính toàn vẹn của dữ liệu khi restart thì Redis sẽ sử dụng AOF.
Forking
Giống như trong OS, Redis sẽ tạo ra một tiến trình con (fork) có ID cụ thể và tham chiếu tới tiến trình cha.
Bản thân Redis cũng sử dụng rất nhiều bộ nhớ nhưng cơ chế forking của nó cho phép tiến trình con và cha dùng chung bộ nhớ nên sẽ tránh được tình trạng out of memory, tiến trình con này sẽ sử dụng bộ nhớ dùng chung để tiến hành snapshotting - kĩ thuật sử dụng bộ nhớ dùng chung để snapshotting này được gọi là copy-on-write.
Nếu không có gì thay đổi thì không cần cấp phát thêm bộ nhớ mới. Ngược lại sẽ có bộ nhớ mới cấp phát, tiến trình con hoàn toàn không biết gì về việc này cả, qua đó giúp cho việc snapshot cả gigabyte dữ liệu diễn ra nhanh chóng.