 Databricks là một nền tảng mạnh mẽ và linh hoạt cho phân tích dữ liệu và máy học, và nó đã trở thành một công cụ quan trọng trong lĩnh vực khoa học dữ liệu. Databricks cung cấp phiên bản cộng đồng miễn phí, cho phép bạn trải nghiệm và khám phá sức mạnh của nền tảng này. Hãy cùng bài viết khám phá cách cài đặt và sử dụng Databricks để mở ra một thế giới mới của phân tích dữ liệu và máy học.
Databricks là một nền tảng mạnh mẽ và linh hoạt cho phân tích dữ liệu và máy học, và nó đã trở thành một công cụ quan trọng trong lĩnh vực khoa học dữ liệu. Databricks cung cấp phiên bản cộng đồng miễn phí, cho phép bạn trải nghiệm và khám phá sức mạnh của nền tảng này. Hãy cùng bài viết khám phá cách cài đặt và sử dụng Databricks để mở ra một thế giới mới của phân tích dữ liệu và máy học.
1. Tổng quan
Databricks đơn giản là một nền tảng dựa trên web để lưu trữ dữ liệu và học máy, được phát triển bởi những người sáng tạo ra Spark. Nhưng Databricks không chỉ đơn thuần là vậy. Đó là một sản phẩm đa năng đáng tin cậy cho mọi nhu cầu dữ liệu, từ việc lưu trữ dữ liệu, phân tích dữ liệu và tạo ra thông tin cần thiết bằng cách sử dụng SparkSQL, xây dựng mô hình dự đoán bằng cách sử dụng SparkML. Nó cũng cung cấp kết nối trực tiếp với các công cụ trực quan hóa như Power BI, Tableau, Qlikview, v.v. Nó có thể được coi như Facebook của big data.

2. Phiên bản Databricks Community
Phiên bản Databricks Community được lưu trữ trên AWS và miễn phí.
Các notebook Ipython có thể được nhập vào nền tảng và sử dụng như bình thường.
Cung cấp các cluster 15GB, quản lý cluster và môi trường notebook và không giới hạn thời gian sử dụng.
Hỗ trợ SQL, Scala, Python, Pyspark.
Cung cấp môi trường notebook tương tác.
Phiên bản trả phí của Databricks có thời gian dùng thử 14 ngày nhưng cần được sử dụng cùng với AWS hoặc Azure hoặc GCP.
3. Data Lake
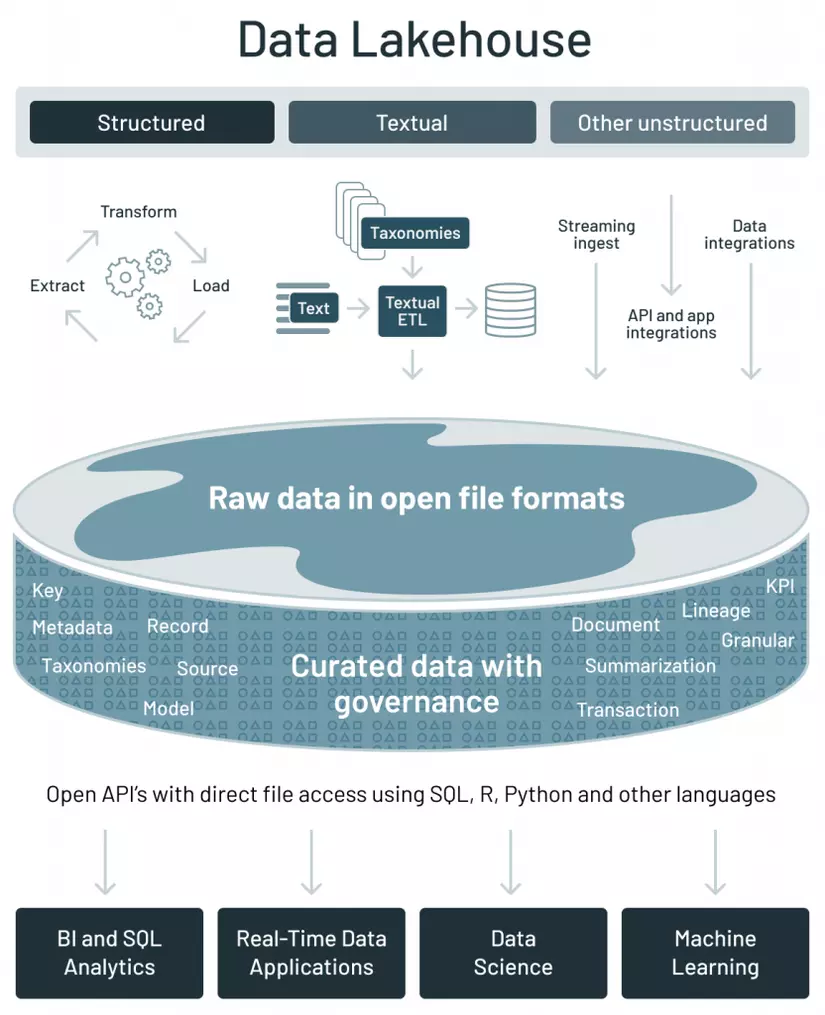
Lakehouse hay data lake là thuật ngữ tiếp thị được sử dụng trong Databricks để chỉ tầng lưu trữ có thể chứa thông tin có cấu trúc hoặc không có cấu trúc, thông tin dòng hoặc thông tin theo lô. Đây là một nền tảng đơn giản để lưu trữ tất cả dữ liệu. Data lake của Databricks được gọi là delta lake. Dưới đây là một số tính năng của delta lake.
- Dựa trên định dạng tệp Parquet.
- Tương thích với Apache Spark.
- Phiên bản dữ liệu.
- Giao dịch ACID – (atomicity, consistency, isolation, durability) đảm bảo tính toàn vẹn và nhất quán của dữ liệu.
- Lưu trữ dữ liệu theo lô và dòng.
- Hỗ trợ xóa và cập nhật vào các bảng bằng cách sử dụng API.
- Có thể truy vấn hàng triệu tệp sử dụng Spark.
4. Áp dụng Databricks theo vai trò
4.1. Nhà phân tích dữ liệu/Phân tích kinh doanh
Với vai trò phân tích, RAC’s và trực quan hóa dữ liệu là công việc cốt lõi của các nhà phân tích, vì vậy sự tập trung cần được đặt vào tích hợp BI và Databricks SQL. Đọc về công cụ trực quan hóa Tableau tại đây.
4.2. Nhà khoa học dữ liệu
Nhà khoa học dữ liệu có vai trò được xác định rõ ràng trong các tổ chức lớn, nhưng trong các tổ chức nhỏ hơn, nhà khoa học dữ liệu đảm nhận nhiều vai trò khác nhau, có thể là một nhà phân tích, kỹ sư dữ liệu, bi visualizer, v.v. Trong một vai trò được xác định rõ ràng, nhà khoa học dữ liệu chịu trách nhiệm khai thác nguồn dữ liệu, một kỹ năng thường bị bỏ qua trước các thuật toán học máy hiện đại. Xây dựng các mô hình dự đoán, quản lý triển khai mô hình. Theo dõi sự thay đổi dữ liệu.
Các kỹ năng quan trọng
Khai thác nguồn dữ liệu – Xác định nguồn dữ liệu và tận dụng chúng để xây dựng các mô hình toàn diện. Xây dựng các mô hình dự đoán. Vòng đời mô hình. Triển khai mô hình.
4.3. Kỹ sư dữ liệu
Phần lớn trách nhiệm của kỹ sư dữ liệu là xây dựng các quy trình ETL và quản lý luồng dữ liệu không ngừng tăng. Xử lý, làm sạch và kiểm tra chất lượng dữ liệu trước khi đẩy chúng vào các bảng vận hành. Triển khai mô hình và hỗ trợ nền tảng là những trách nhiệm khác mà được giao cho kỹ sư dữ liệu.
Databricks cần được kết hợp với Azure/AWS/GCP và do chi phí tương đối cao của nó, việc áp dụng Databricks trong các startup nhỏ/ vừa ở Ấn Độ khá thấp.
5. Lợi ích của Databricks
Hỗ trợ các framework (scikit-learn, TensorFlow, Keras), thư viện (matplotlib, pandas, numpy), ngôn ngữ lập trình (ví dụ: R, Python, Scala hoặc SQL), các công cụ và môi trường phát triển tích hợp (JupyterLab, RStudio).
Databricks cung cấp một Nền tảng Phân tích Dữ liệu Thống nhất, các kỹ sư dữ liệu, nhà khoa học dữ liệu, nhà phân tích dữ liệu và nhà phân tích kinh doanh có thể làm việc cùng nhau trên cùng một notebook.
Linh hoạt trên các hệ sinh thái khác nhau – AWS, GCP, Azure.
Đáng tin cậy và có khả năng mở rộng dữ liệu thông qua Delta Lake.
Có các khả năng cơ bản để tạo các biểu đồ trực quan.
Tự động hóa quá trình máy học tự động (AutoML) và quản lý vòng đời mô hình thông qua MLFLOW.
Hỗ trợ điều chỉnh siêu tham số (hyperparameter tuning) thông qua HYPEROPT.
Tích hợp với Github và Bitbucket.
Tốc độ ETL nhanh hơn gấp 10 lần.
6. Hướng dẫn từng bước sử dụng Databricks
Phiên bản Databricks community edition miễn phí để sử dụng, và nó có 2 vai trò chính: 1. Data Science và Engineering và 2. Machine learning. Đường dẫn Machine learning có một model registry và experiment registry được bổ sung, nơi có thể theo dõi các thử nghiệm bằng cách sử dụng MLFLOW. Databricks cung cấp các sổ ghi chú Jupyter để làm việc, có thể chia sẻ qua các nhóm, giúp dễ dàng hợp tác.
6.1. Tạo một cluster
Để các sổ ghi chú hoạt động, chúng phải được triển khai trên một cluster. Databricks cung cấp 1 Driver: 15.3 GB Bộ nhớ, 2 Core, 1 DBU miễn phí.
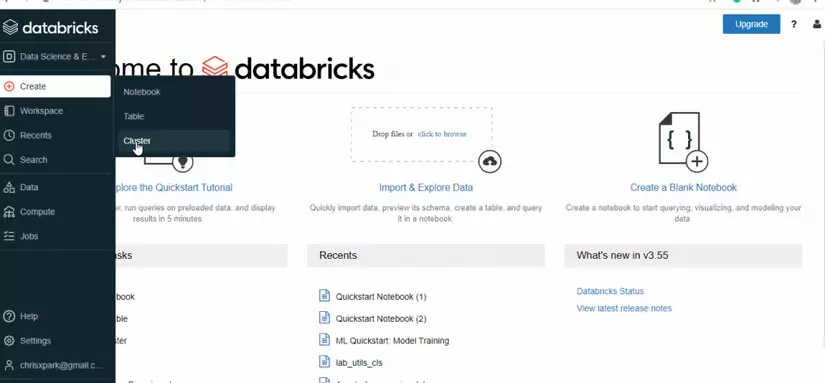
- Chọn Create, sau đó nhấp vào cluster.
- Cung cấp tên cho cluster.
- Chọn Phiên bản Databricks Runtime – 9.1 (Scala 2.12, Spark 3.1.2) hoặc các phiên bản khác, GPU không khả dụng trong phiên bản miễn phí.
- Chọn khu vực khả dụng là AUTO, nó sẽ cấu hình khu vực gần nhất có sẵn.
- Có thể mất vài phút trước khi cluster hoạt động.
- Cluster sẽ tự động chấm dứt sau một khoảng thời gian không hoạt động là hai giờ.
- Để đóng cluster, có 2 tùy chọn, một là chấm dứt và sau đó khởi động lại sau này. Thứ hai, xóa hoàn toàn cluster. Việc xóa cluster sẽ không xóa các sổ ghi chú vì các sổ ghi chú có thể được gắn kết trên bất kỳ cluster nào khả dụng phù hợp với công việc hiện tại.
Hoặc
- Chọn Compute
- Chọn tạo cluster và sau đó làm theo từ bước 2 được đề cập ở trên.
6.2. Tạo một sổ ghi chú
- Chọn tùy chọn tạo và sau đó nhấp vào sổ ghi chú.
- Cung cấp một tên phù hợp cho sổ ghi chú.
- Chọn ngôn ngữ ưu tiên – SQL, Scala, Python, R.
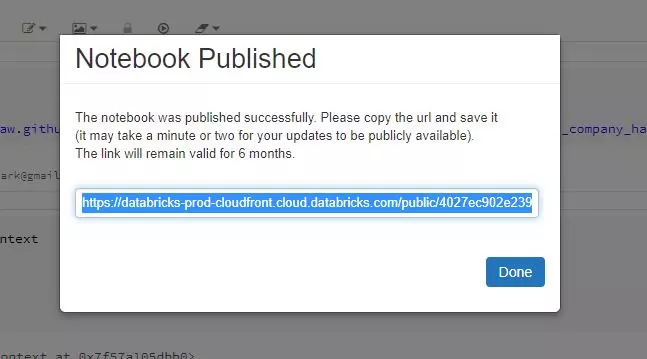
- Chọn một cluster để sổ ghi chú chạy trên. Xuất bản sổ ghi chú
Sau khi phân tích hoàn thành, các sổ ghi chú Databricks có thể được xuất bản (có sẵn công khai) và liên kết sẽ được lưu trong 6 tháng.
 Nhập sổ ghi chú đã xuất bản
Nhập sổ ghi chú đã xuất bản
Sổ ghi chú Databricks đã được xuất bản có thể được nhập bằng cách sử dụng URL cũng như tập tin vật lý. Để nhập bằng cách sử dụng URL:
Chọn Workspace và di chuyển đến thư mục mà tập tin cần được lưu vào.
Nhấp vào nhập và sau đó hộp thoại mới hiển thị.
Dán URL vào và nhấp vào nhập.
Sử dụng liên kết và nhập một hướng dẫn SparkSQL vào workspace.
Bài viết này cung cấp một cái nhìn sơ lược về những gì Databricks có thể làm được cùng như các bước cơ bản để cài đặt và sử dụng data bricks. Databricks có khả năng nhiều hơn nữa, những khả năng này không được khám phá trong bài viết này, và đối với những người đam mê dữ liệu, đó là một kho báu vô cùng quý giá. Vì vậy, hãy thực hành và luôn tiếp tục học hỏi.
Tìm hiểu thêm các khóa học tại đây!