Mở đầu
Xin chào các anh chị em, chả là hôm vừa rồi mình có ngồi xem Cloud Summit AI của GCP host. Mọi người có thể tham khảo qua ở đây nhé: Google Cloud Applied AI Summit.
Trong các topic mà họ chia sẻ thì có vài nội dung khá hay, mà những người "gà mờ AI" như mình cũng hiểu được đôi chút. Nay đang tranh thủ hết task nên mình ngồi vọc vạch một chút về các Multimodal mới ra mắt của GCP không lâu. Trong số đó thì có Get multimodal embeddings, đại khái là Vertex AI giờ đã cho phép chúng ta embedding vector cho cả data dạng Text và Image rồi. Còn tại sao vector lại có mặt ở đây thì mọi người cứ hiểu đơn giản là một cách biểu diễn dữ liệu và được sử dụng để tìm các giá trị tương quan nhé
Tạo account GCP để sử dụng dịch vụ
Để sử dụng Multimodal Embedding (hay Vertex AI) thì mọi người hãy follow theo các bước sau nhé
- Truy cập trang chủ Google Cloud Platform và tạo account
- Tạo một project mới và enable dịch vụ Vertex AI API
- Vào phần IAM & Services -> Credentials -> tạo một service account và download file credentials.json về nhé. Phần này nếu chưa rõ mọi người có thể tham khảo tại đây: Create access credentials
Demo thôi :v
Trước tiên máy mọi người hãy cài sẵn:
Python >= 3.12.1
Elasticsearch >= 7.17.17
có thể sử dụng Docker cho tiện.
https://gitlab.com/doanthephuc/multimodalembeddinggcp.git
cd multimodalembeddinggcp
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
python process.py
Với anh em nào sử dụng Linux distribution thì thường hay có nhiều version Python cài trên máy, có thể thay command từ python sang python3.12 nhé
Tạo index lưu trữ vector trong Elasticsearch
from dotenv import load_dotenv
from vertexai.vision_models import MultiModalEmbeddingModel
from vertexai.preview.vision_models import Image
import os
from elasticsearch import Elasticsearch load_dotenv() # connect to elastic search cluster
# create index if it's not existing
es = Elasticsearch([os.getenv("ELASTIC_SEARCH_DOMAIN")])
index_name = "product_vectors"
if not es.indices.exists(index=index_name): es.indices.create( index=index_name, body={ "mappings": { "properties": { "vector_of_image": { "type": "dense_vector", "dims": 1408, # specify the dimensionality of your vectors }, "image_name": {"type": "text"}, } } }, )
Ở đây mình sử dụng kiểu dữ liệu dense_vector, Elasticsearch còn cung cấp một số kiểu dữ liệu vector khác như sparse_vector,... mọi người có thể tham khảo document thêm nhé. Còn số chiều ở đây là 1408 - là số chiều vector default của Multimodal Embedding, mọi người số thể giảm số chiều xuống 128, 256, 512 tùy ý cho phù hợp với DB của mình.
Embedding images into vectors
Trong folder mình đã có sẵn product_images.zip, bao gồm một có hình ảnh về TV, điều khiển, ghế sofa,... Mình sẽ sử dụng model multimodalembedding@001 để thực hiện embedding vector cho từng ảnh này, và lưu lại vào Elasticsearch index ở trên:
def embedding_images(): # get the list of images folder_path = "product_images" files = os.listdir(folder_path) image_files = [file for file in files] model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding@001") for file in image_files: print("embedding vector for " + file) image = Image.load_from_file("product_images/" + file) # 1408 is the default dimensions quantity embeddings = model.get_embeddings(image=image, dimension=1408) image_embedding = embeddings.image_embedding # index the vector into elastic search index # to simplify the task, the 'id' field will not be provided document = {"vector_of_image": image_embedding, "image_name": file} es.index(index=index_name, body=document)
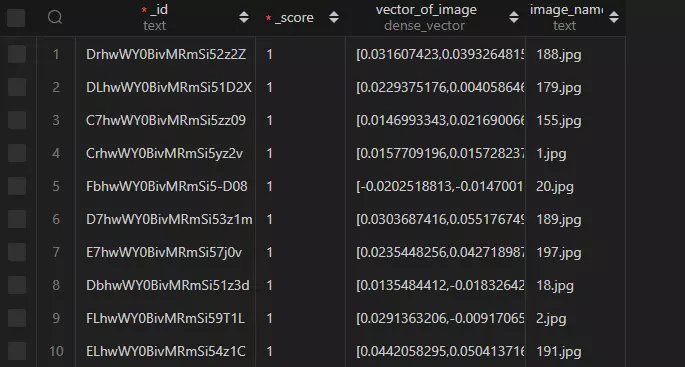
Sau khi tiến hành embedding xong, kết quả sẽ lưu trong DB thế này:
So sánh kết quả trên với text
Vậy là gần xong rồi :v, giờ ta sẽ tiến hành embedding bằng model tương tự, nhưng lần này là embedding với text và đem kết quả ra để so sánh:
def search_related_images(content): # embdding the text content model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding@001") embeddings = model.get_embeddings(contextual_text=content, dimension=1408) text_embedding = embeddings.text_embedding # use cosine similarity to compare vectors search_query = { "query": { "script_score": { "query": {"match_all": {}}, "script": { "source": "cosineSimilarity(params.queryVector, 'vector_of_image') + 1.0", "params": {"queryVector": text_embedding}, }, } } } results = es.search(index=index_name, body=search_query) for hit in results["hits"]["hits"]: print(f"Score: {hit['_score']} - Image: {hit['_source']['image_name']}")
Như mọi người thấy, ở trên mình sử dụng phép so sánh Cosine, mọi người hoàn toàn có thể sử dụng các phép toán so sánh khác (phức tạp hơn, hiệu quả hơn) như Euclide, Hamming,...
Khi chạy đoạn code trên, ta sẽ có kết quả trả về như sau, với tham số truyền vào là "television":
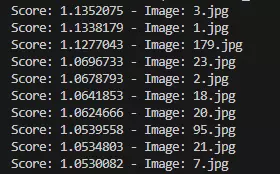
Để tiện mọi người theo dõi, đây là ảnh được trả về với mức score cao nhất (tương tự các ảnh sau cũng trả về kết quả là TV):

Lời kết
Như vậy là mình đã giới thiệu tới mọi người cái nhìn cơ bản về dịch vụ Multimodal Embedding của GCP và bài toán đơn giản về tìm kiếm hình ảnh dưới góc nhìn của một người không có kiến thức gì mấy về AI. Bên cạnh đó, GCP còn cung cấp rất nhiều dịch vụ thú vị xung quanh, hoặc nếu mọi người muốn lưu trữ và tìm kiếm vector trực tiếp on cloud, GCP cũng cung cấp dịch Vertex AI Vector Search. Mong là ngày nào đó các anh em dev "non-AI" như mình cũng có thể tham gia xây dựng các hệ thống liên quan tới AI 😀.
Cảm ơn mọi người đã dành thời gian đọc bài viết, nếu có góp ý gì mong mọi người đóng góp dưới phần comment, kinh nghiệm mình cũng có ít nên mong mọi người ném đá nhẹ tay. 🙇♂️
Link repository: https://gitlab.com/doanthephuc/multimodalembeddinggcp