Giới Thiệu
-
Serverless SQL Pools, còn được gọi là serverless SQL databases hoặc serverless SQL Querying, là một loại dịch vụ cơ sở dữ liệu dựa trên đám mây cho phép người dùng chạy các truy vấn SQL mà không cần quản lý hoặc cung cấp cơ sở hạ tầng cơ bản.
-
Theo truyền thống, việc thiết lập cơ sở dữ liệu yêu cầu phải định cấu hình máy chủ, quản lý bộ nhớ và mở rộng quy mô tài nguyên khi cần. Tuy nhiên, với nhóm SQL không có máy chủ, người dùng không cần phải lo lắng về những tác vụ này. Thay vào đó, nhà cung cấp đám mây tự động phân bổ tài nguyên dựa trên khối lượng công việc, tăng hoặc giảm quy mô tài nguyên khi cần thiết để xử lý tải truy vấn.
-
Các nhóm SQL không có máy chủ này thường cung cấp các tính năng như tự động mở rộng quy mô, tính sẵn sàng cao được tích hợp sẵn và mô hình định giá trả cho mỗi truy vấn. Chúng được thiết kế để mang lại hiệu quả cao và tiết kiệm chi phí vì người dùng chỉ trả tiền cho các truy vấn họ thực hiện thay vì duy trì cơ sở hạ tầng cố định.
-
Các nhà cung cấp đám mây phổ biến như Amazon Web Services (AWS), Microsoft Azure và Google Cloud Platform (GCP) cung cấp dịch vụ cơ sở dữ liệu SQL không máy chủ như một phần trong dịch vụ cơ sở dữ liệu được quản lý của họ. Các dịch vụ này cho phép người dùng tập trung hơn vào việc phát triển ứng dụng và phân tích dữ liệu thay vì quản lý cơ sở hạ tầng hỗ trợ cơ sở dữ liệu của họ.
So sánh với Dedicated SQL Pools
Serverless SQL Pools và Dedicated SQL Pools là hay tùy chọn triển khai khác nhau cho cơ sở dữ liệu SQL trong môi trường đám mây, đặc biệt là Azure Synapse
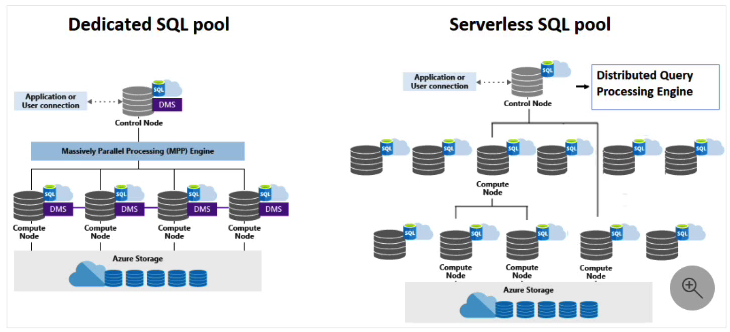
| Catagory | Serverless SQL Pools |
Dedicated SQL Pools |
|---|---|---|
Resource Provisioning (Cung cấp tài nguyên) |
Tài nguyên được nhà cung cấp đám mây cung cấp động dựa trên khối lượng công việc. Người dùng không cần quản lý hoặc cấu hình cơ sở hạ tầng | Người dùng cung cấp và quản lý một bộ tài nguyên cố định cho cơ sở dữ liệu của họ. Họ cần chỉ định trước mức công suất tính toán và dung lượng lưu trữ mà họ yêu cầu và mức này không đổi trừ khi được điều chỉnh thủ công |
Scalability (Khả năng mở rộng) |
Tự động tăng hoặc giảm quy mô tài nguyên dựa trên nhu cầu. Họ có thể xử lý khối lượng công việc biến động một cách hiệu quả mà không cần sự can thiệp của người dùng | Việc mở rộng quy mô trong nhóm SQL chuyên dụng thường bao gồm sự can thiệp thủ công. Người dùng cần tính toán và lưu trữ theo những thay đổi trong mẫu khối lượng công việc |
Billing Model (Mô hình thanh toán) |
Người dùng được tính phí dựa trên lượng dữ liệu được xử lý hoặc số lượng truy vấn được thực hiện. Họ chỉ trả tiền cho những tài nguyên đã tiêu thụ trong quá trình thực hiện truy vấn. | Người dùng được tính phí dựa trên các tài nguyên được cung cấp, bất kể chúng có được sử dụng tích cực hay không. Điều này có nghĩa là người dùng phải trả một khoản cố định cho tài nguyên điện toán và lưu trữ được phân bổ, bất kể khối lượng công việc thực tế |
Use Cases |
Lý tưởng cho các tình huống trong đó khối lượng công việc không thường xuyên, không thể đoán trước hoặc có kiểu sử dụng thay đổi. Nó phù hợp cho truy vấn đặc biệt, phân tích dữ liệu, khám phá hoặc xử lý hàng loạt không thường xuyên | Phù hợp với khối lượng công việc có thể dự đoán được với yêu cầu hiệu suất nhất quán. Nó thường được sử dụng cho các ứng dụng quan trọng, phân tích phức tạp và lưu trữ dữ liệu quy mô lớn |
Management Overhead (Chi phí quản lý) |
Chi phí quản lý tối thiểu do nhà cung cấp đám mây xử lý việc cung cấp, mở rộng quy mô và bảo trì cơ sở hạ tầng | Yêu cầu nhiều nỗ lực quản lý hơn từ người dùng vì họ cần giám sát việc sử dụng tài nguyên, lập kế hoạch mở rộng quy mô và xử lý các tác vụ bảo trì. |