Chào các bạn, như các bạn cũng biết xác suất thống kê khá là quan trọng trong Xử lý dữ liệu (data analysis) cũng như khoa học dữ liệu (data Science) vì nó giúp chúng ta hiểu rõ hơn về dữ liệu mình có. Và mình dạo này khá là rảnh rỗi nên học lại kiến thức xác suất thống kê và đây là bài viết đầu tiên trong chuỗi Series Xác suất thống kê với python . Chúng ta cùng bắt đầu thôi nhé.
Mean, Median, Mode
3 giá trị Mean, Median và Mode là những khái niệm cơ bản trong xác suất thống kê vì vậy ở bài này mình chỉ nhắc qua về cách tính toán chứ không đi chi tiết nhé mọi người.
Mình sẽ lấy một ví dụ về dãy số sau dùng để áp dụng tính toán 3 giá trị trên:1, 3, 4, 4, 8, 4,9, 15.
Mean
Mean hay còn gọi là trung bình của các số, cách tính như sau
Vậy giá trị trung bình của dãy trên là 6
Median
Median hay còn gọi là trung vị (vị trí chính giữa ). Để tìm ra median của dãy trên chúng ta làm như sau
Sắp xếp dãy trên theo thứ tự tăng dần, 1, 3, 4, 4, 4, 8, 9, 15. Meadian ở đây chính bằng 4
Mode
Hay còn là tần suất xuất hiện nhiều nhất và mode ở đây bằng 4.
Thông thường Mean sẽ được sử dụng phổ biến nhất. Tuy nhiên nếu so sánh giữa mean và median, thì mean thường sẽ bị ảnh hưởng bởi các extreme observation (rất lớn hoặc rất nhỏ), còn median thì không. Vì vậy, nếu dataset có xuất hiện extreme observations, thì median thường được sử dụng thay cho mean.
Variance, Standard Deviation
Hai tập dữ liệu có thể cùng các giá trị mean, median và mode, tuy nhiên vẫn khác nhau ở các góc độ khác. Và một trong số đó là độ biến thiên ( Variation).
Ví dụ xem xét chiều cao của các bạn học sinh ở độ tuổi từ 15-17 tuổi của 2 trường phổ thông đều có cùng mean, median và mode tuy nhiên độ biến thiên về chiều cao của các các bạn học sinh là khác nhau; trường A có sự đồng đều hơn (độ biến thiên thấp), trường B có độ biến thiên cao hơn. Và chúng ta có thể dùng Variance (phương sai) và Standard Deviation(độ lệch chuẩn) để đo.
Variance hay còn gọi là phương sai để đo lường mức độ phân tán của các giá trị trong một tập dữ liệu. Nó đo độ lệch của mỗi điểm dữ liệu so với giá trị trung bình của toàn bộ tập dữ liệu.Variance cho biết mức độ đồng nhất hoặc không đồng nhất của các giá trị trong một tập dữ liệu. Khi variance thấp nghĩa là các giá trị trong tập dữ liệu gần nhau và không chênh lệch nhiều. Ngược lại, khi variance cao, các giá trị trong tập dữ liệu có sự chênh lệch lớn. Công thức tính Variance như sau:
= Variance population
N = Số lượng quan sát trong population
Xi = Quan sát thứ i trong population
μ = Population mean
Standard deviation hay còn gọi là độ lệch chuẩn được tính từ phương sai và cho bạn biết trung bình mỗi giá trị nằm bao xa so với giá trị trung bình. Đó là căn bậc hai của variance:
σ= Population standard deviation
Áp Dụng với Python
Các kiến thức cơ bản về xác suất thống kê ở trên chúng ta đều đã được học ở trường rồi, vì vậy tiếp theo chúng ta sẽ dùng python để xem tính toán các giá trị trên có đơn giản k nhé,
Tập dữ liệu của tuần học này trong khóa Statistics được lấy từ đây mọi người tải về để thực hành nhé.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
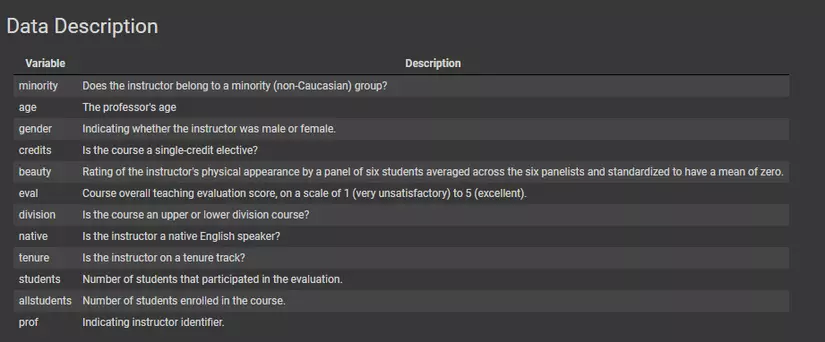
hình ảnh: mô tả về dữ liệu
ratings_df=pd.read_csv('teachingratings.csv')
Check xem dữ liệu có những gì
ratings_df.head(5)
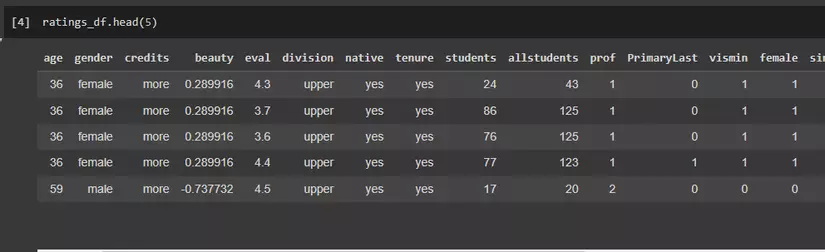
hình ảnh:5 dòng đầu của tập dữ liệu này
check thông tin dữ liệu
ratings_df.info()
Trong python làm sao để tính Mean,Median, Min, Max nhỉ ? Mình sẽ tính toán các thông số này với cột 'Students' như các lệnh dưới đây nhé,
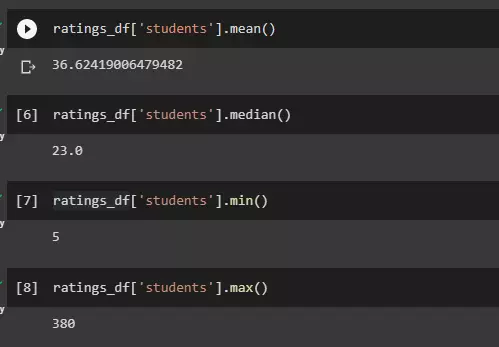
hình ảnh: Cách tính mean, meadian min, max
Trong pandas có hàm tính toán thống kê cơ bản và chi tiết luôn chúng ta cùng xem nha:
ratings_df.describe()
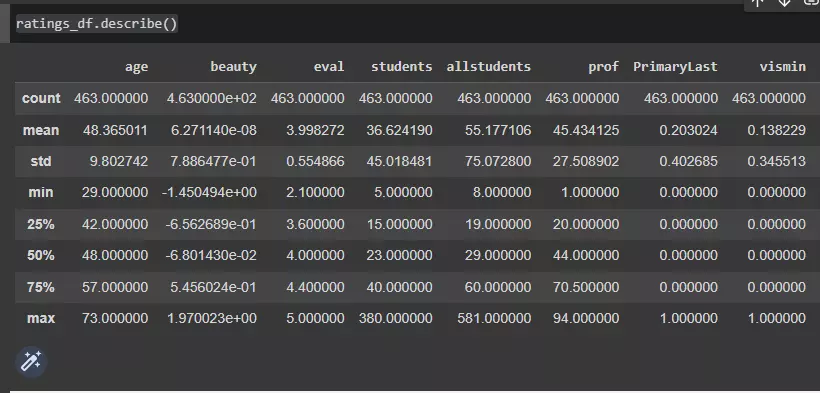
Như ở hình trên các bạn cũng thấy được ở đây pandas đã tính sẵn cho chúng ta những giá trị cơ bản trong thống kê rồi.
Tiếp theo sẽ thử áp dungj các giá trị ở trên để trả lời các câu hỏi này nhé.
- Does average beauty score differ by gender? Produce the means and standard deviations for both male and female instructors
ratings_df.groupby('gender').agg({'beauty':['mean', 'std', 'var']}).reset_index()
kết quả thu được:
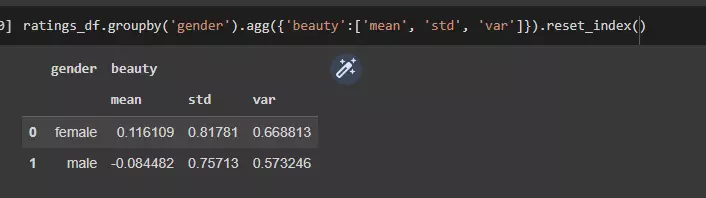
Dựa vào kết quả trên chúng ta có thể thấy giá trị beauty trung bình của nữ cao hơn nam
- Calculate the percentage of males and females that are tenured professors. Will you say that tenure status differ by gender?
# groupby and get total sum
tenure_count = ratings_df[ratings_df.tenure == 'yes'].groupby('gender').agg({'tenure': 'count'}).reset_index()
# calculate percentage
tenure_count['percentage'] = 100 * tenure_count.tenure/tenure_count.tenure.sum()
tenure_count
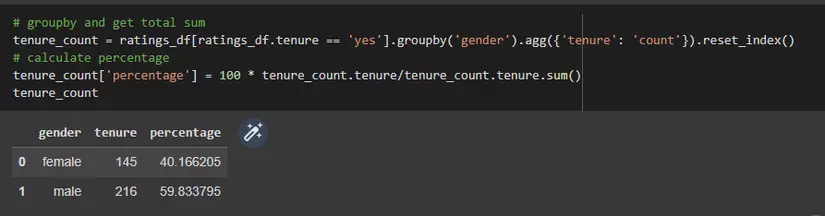
Dựa vào kết quả thì chúng ta cũng thấy được sự khác biệt.
- Calculate the percentage of visible minorities are tenure professors. Will you say that tenure status differed if teacher was a visible minority?
# first groupby to get the total sum
tenure_count = ratings_df.groupby('minority').agg({'tenure': 'count'}).reset_index()
# Find the percentage
tenure_count['percentage'] = 100 * tenure_count.tenure/tenure_count.tenure.sum()
tenure_count
- *Does average age differ by tenure? Produce the means and standard deviations for both tenured and untenured professors.
Câu thứ 4 này mọi người thử code xem nha. xem đáp án tại notebook này nha.
Thực chất trong câu hỏi của khóa học cũng có gợi ý sử dụng các giá trị nào để tính toán. 
Kết luận
Cảm ơn các bạn đã đọc bài viết của mình, các bạn có thể cùng học khóa học này với mình để trao đổi nha., Mong nhận được sự góp ý của mọi người. Và đừng quênUpvoted nha  )
)
Reference
https://www.coursera.org/learn/statistics-for-data-science-python