Microsoft đã giới thiệu một mô hình mới được đặt tên là Visual ChatGPT, kết hợp ChatGPT với các mô hình nền tảng hình ảnh như Transformers, ControlNet và Stable Diffusion. Không chỉ có thể nhập các hình ảnh và tạo ra các hình ảnh mới, mà bạn cũng có thể chỉnh sửa hình ảnh của mình.
Mục đích của Visual ChatGPT rất đơn giản. Bạn có thể tạo và sửa đổi các hình ảnh trong định dạng chat, tạo ra một loại trải nghiệm người dùng khác cho việc làm việc với các hình ảnh và nghệ thuật sinh học AI.
Trong khi chúng ta đã sử dụng các nền tảng và ứng dụng cụ thể cho hình ảnh và nghệ thuật, điều này kết hợp khái niệm của trò chuyện + hình ảnh kích thích, điều đó chưa được khám phá thực sự.
Hiện tại, bạn phải tải xuống Visual ChatGPT qua trang GitHub, nhưng tôi dự đoán rằng chúng ta sẽ thấy điều này trong các giao diện người dùng khác sớm. Có thể như là một tính năng mới trong ChatGPT và được phơi bày thông qua API của nó.
Cũng có một tùy chọn "hugging face" nếu bạn muốn thử nghiệm nó.
Dưới đây là sơ đồ kiến trúc hệ thống…
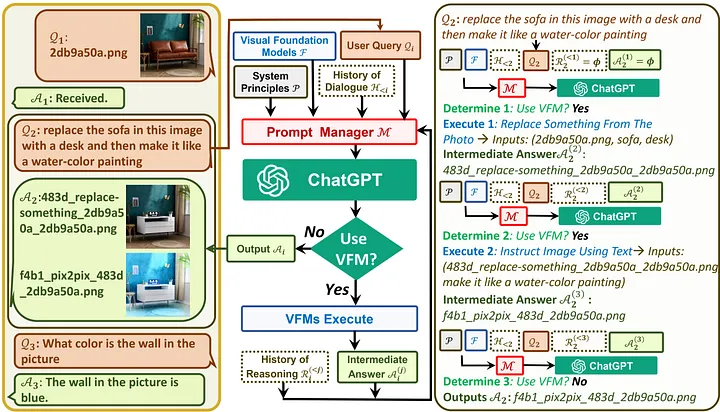
Về cơ bản, Visual ChatGPT sử dụng các thuật toán sinh học để phân tích dữ liệu ảnh, sau đó dự đoán các giá trị pixel để tạo ra hình ảnh mới. Nó kết hợp cả phương pháp đưa ra các thông tin hình ảnh dưới dạng văn bản để đặt câu hỏi và nhận câu trả lời.
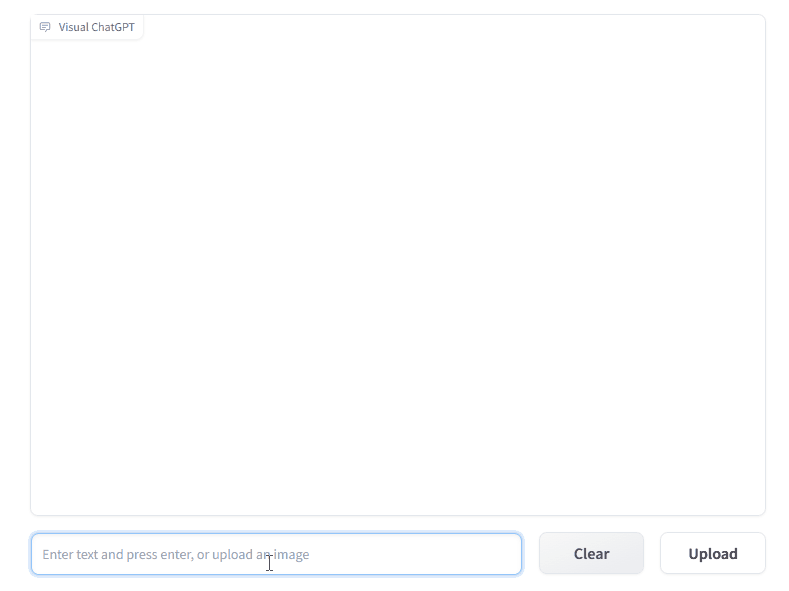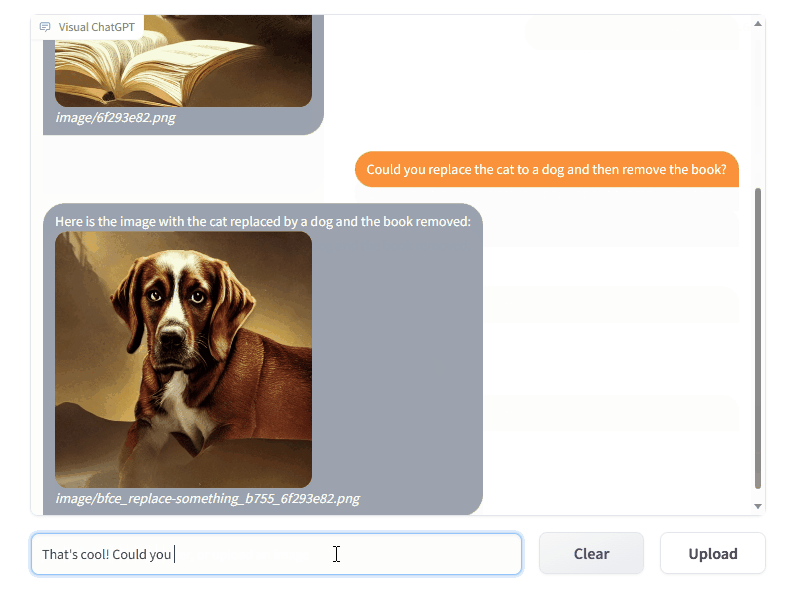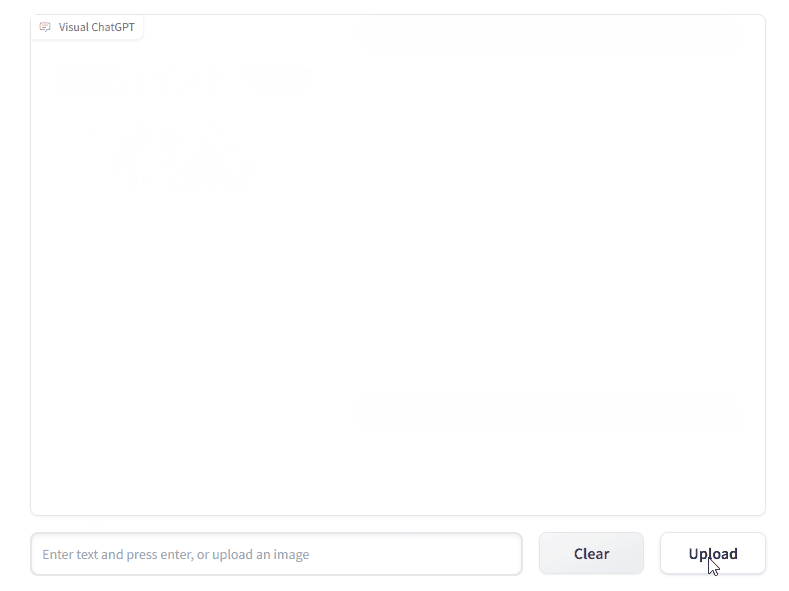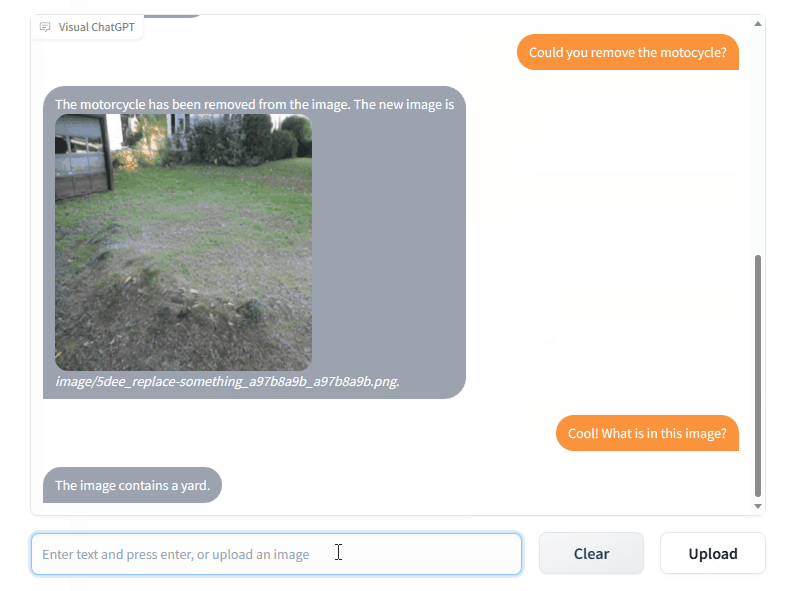
Visual ChatGPT có thể được sử dụng để tạo ra các hình ảnh tùy ý, bao gồm các phong cảnh, đồ vật, động vật, con người, và nhiều hơn nữa. Nó cũng có thể được sử dụng để chỉnh sửa hình ảnh hiện có, bao gồm việc thêm hoặc xóa các đối tượng, sửa đổi màu sắc hoặc thay đổi ánh sáng.
Nhưng điều thú vị hơn là với Visual ChatGPT, bạn có thể tạo ra các hình ảnh theo cách chưa từng thấy trước đó. Bạn có thể gửi một bức ảnh và
Paper: https://arxiv.org/abs/2303
VelikHo