Trước tiên cho ai chưa biết SOLID là gì thì đây là bộ gồm 5 nguyên tắc trong thiết kế nói chung (không chỉ trong thiết kế phần mềm đâu nhé) với mỗi chữ cái đầu trong từ S-O-L-I-D thể hiện một nguyên tắc.
Trong tất cả các nguyên tắc của SOLID thì Single Responsibility Principle (viết tắt là SRP) là nguyên tắc có lẽ được ít người hiểu rõ nhất. Có lẽ là bởi nó có một cái tên không được thích hợp cho lắm. Nó dễ gây ra việc các lập trình viên khi nghe thấy cái tên này sẽ cho rằng nó có nghĩa là mỗi module chỉ nên làm một việc.
Không sai, đúng là có một nguyên tắc như vậy. Một hàm chỉ nên làm một việc. Chúng ta thường sử dụng nguyên tắc đó khi chúng ta refactor các hàm quá lớn thành các hàm nhỏ hơn và sử dụng nó ở các tầng thấp. Nhưng đấy không phải một trong các nguyên tắc của SOLID, không phải SRP.
Thời đầu, SRP được nói như này:
Một module chỉ nên có một lý do để thay đổi.
Các hệ thống phần mềm bây giờ đều được thay đổi để thỏa mãn người dùng (user) và các bên liên quan (stakeholder), thế nên nói chung thì "lý do để thay đổi" mà nguyên tắc trên nói tới chính là các user và stakeholder đó. Chúng ta có thể phát biểu lại nguyên tắc như sau:
Một module chỉ nên chịu trách nhiệm với chỉ một user hoặc stakeholder.
Cơ mà thực tế thì các từ như "user" và "stakeholder" dùng ở đây cũng không được đúng cho lắm. Nói thẳng ra là không bao hàm đủ. Bởi sẽ có thể có nhiều user hoặc stakeholder muốn hệ thống của chúng ta thay đổi theo cùng 1 chiều hướng. Thế nên ở đây chúng ta thực chất là nói đến một nhóm người muốn có sự thay đổi đó. Với những nhóm như vậy ta gọi với một ngôn từ khá là quen thuộc trong việc phân tích và thiết kế hệ thống: actor.
Chốt lại thì cái phiên bản của cuối cùng của SRP sẽ thế này:
Một module chỉ nên chịu trách nhiệm với chỉ một actor.
Còn giờ thì ta xem "module" là cái gì? Thôi thì anh em cứ hiểu đơn giản nhất nó là một cái source file. Nói chung trong phần lớn trường hợp thì hiểu như thế là ổn. Mặc dù có một số ngôn ngữ và môi trường phát triển không sử dụng source file để chứa code. Trong các trường hợp đó một module là một sự gắn kết của các hàm và cấu trúc dữ liệu.
Tại sao ở đây lại dùng từ "gắn kết" mà không phải là một "tập hợp các hàm" chẳng hạn. Bởi vì việc sử dụng từ này chính là ngụ ý nói đến SRP. Sự gắn kết ám chỉ việc các hàm và cấu trúc dữ liệu này phải gắn với nhau để đảm nhận nhiệm vụ cho chỉ một actor đơn lẻ.
Có lẽ cách tốt nhất để hiểu về nguyên tắc SRP này là nhìn vào các dấu hiệu gây ra việc vi phạm nó.
Dấu hiệu 1: Sự trùng lặp ngẫu nhiên
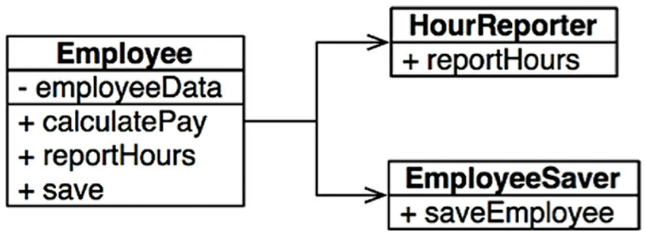
Tôi sẽ lấy một ví dụ là class Employee trong một hệ thống trả lương. Class này có ba method: calculatePay(), reportHours() và save()
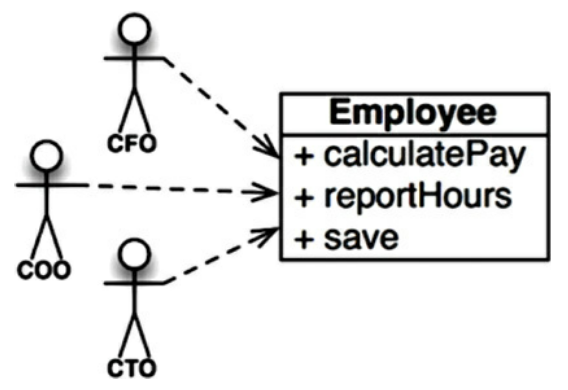
Class này vi phạm SRP vì ba phương thức này ảnh hưởng tới ba actor khác nhau. Việc implement các hàm:
calculatePay()được chỉ định bởi phòng kế toán, sẽ báo cáo tới CFO.reportHours()được chỉ định và sử dụng bởi phòng nhân sự, sẽ báo cáo tới COO.save()được chỉ định bởi các nhân viên quản trị cơ sở dữ liệu, sẽ báo cáo tới CTO.
Việc đặt source code cho cả ba phương thức này trong một class Employee đơn lẻ gây ra việc ghép các actor lại với nhau. Nói cho dễ hiểu thì khi có những thay đổi từ đội CFO như thay đổi thuật toán, input, output,... sẽ gây ra việc phải chỉnh sửa code ở class Employee, và khi code trong Employee thay đổi sẽ impact đến đội COO và CTO vì hai đội này cũng đang sử dụng code trong cùng module đó.
Ví dụ, giả sử như hàm calculatePay() và reportHours() cùng dùng chung một thuật toán để tính giờ làm việc bình thường (tức là kiểu không phải giờ OT). Và cũng giả sử rằng các developers rất ư là cẩn thận trong việc tránh lặp code, thế nên đặt thuật toán này và một hàm tên là regularHours().
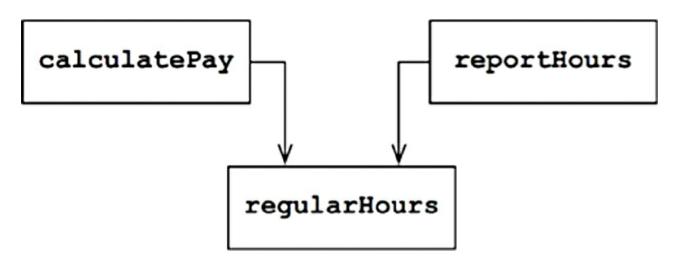
Giờ tiếp tục giả dụ rằng đội CFO quyết định cách tính thời gian làm việc bình thường cần phải sửa một tí. Nhưng trong khi đó, đội COO trong phòng nhân sự không muốn chỉnh mấy thứ này vì họ sử dụng cách tính này cho một mục đích khác.
Một developer được giao task này và nhìn thấy hàm regularHours() đang được gọi bởi hàm calculatePay(), có vẻ tiện phết. Thế là xúc luôn cái hàm này đem sửa lấy sửa để mà không biết nó cũng được gọi bởi hàm reportHours().
Developer hoàn thành công việc, test kỹ càng các kiểu. Đội CFO xác nhận feature mới khá lá ưng, và hệ thống được deploy. Và tất nhiên đội COO chả biết gì đến cái việc thay đổi này, và họ vẫn cứ sử dụng những số liệu không còn đúng từ hàm reportHours(). Thậm chí cho đến khi vấn đề được phát hiện, ông COO vẫn thốn đến tận rốn khi các bad data này đã gây tiêu tốn cả đống tiền.
Và mọi thứ xảy ra như vậy. Anh em ai làm developer thì cũng thừa hiểu việc sửa một mà impact mười nó là thế nào. Nói chung những vấn đề như thế này xảy ra vì chúng ta đang đặt những dòng code mà nhiều actor khác nhau dựa vào quá gần nhau. SRP yêu cầu chúng ta tách riêng code mà các actor khác nhau dựa vào.
Dấu hiệu 2: Phải đi merge code
Không khó để có thể tưởng tượng rằng việc merge khá là bình thường trong các source file mà chứa nhiều method khác nhau. Mà đặc biệt lại còn hay xảy ra nếu mà các method này chịu trách nhiệm cho các actor khác nhau, vì sao?
Ví dụ, giả sử rằng đội CTO quyết định sẽ thêm một thay đổi nhỏ trong schema của bảng Employee của database. Giả sử rằng đội COO quyết định rằng họ cần đội format của báo cáo giờ làm việc.
Viễn cảnh ở đây là có hai developer khác nhau, có thể là đến từ hai team khác nhau luôn, kiểm tra class Employee và bắt đầu tạo các thay đổi, không may là các thay đổi này lại gây conflict với nhau, và kết quả là phải đi merge.
Chẳng cần phải nói thì chúng ta cũng hiểu rằng việc merge là một câu chuyện đầy mạo hiểm. Mặc dù các công cụ bây giờ rất là xịn, nhưng không có tool nào có thể xử lý được với tất cả các case merge. Về cuối cùng thì nó cũng luôn là một điều nguy hiểm.
Trong ví dụ của chúng ta, việc merge đặt cả CTO và COO vào nguy hiểm. Và thậm chí đến cả CFO cũng có thể gặp nguy hiểm.
Còn nhiều dấu hiện khác mà chúng ta có thể tự tìm ra, nhưng tất cả đều bao gồm việc nhiều người cùng sửa một source file mà lại cho những lý do khác nhau.
Một lần nữa, cách để tránh vấn đề này chính là tách các dòng code mà hỗ trợ cho các actor khác nhau.
Giải pháp
Có rất nhiều cách đề giải quyết vấn đề này. Nói chung thì đều là chuyển các hàm sang các class khác nhau.
Có lẽ cách rõ ràng nhất là tách dữ liệu ra khỏi các hàm. Ba class sẽ chia sẻ truy cập tới EmployeeData, đây là một cấu trúc dữ liệu đơn giản mà không chứa method nào. Mỗi class giữ chỉ source code cần thiết cho các hàm của nó. Ba class này không được phép biết tới nhau. Do đó ta sẽ tránh được việc trùng lặp ngẫu nhiên (dấu hiệu 1).
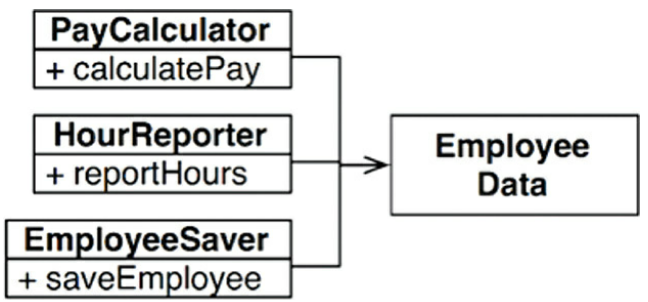
Nhược điểm của giải pháp này là các developer giờ có tới ba class mà sẽ phải khởi tạo và tracking. Nghe có vẻ cồng kềnh thật. Một giải pháp là khá là common đó là sử dụng Facade pattern.
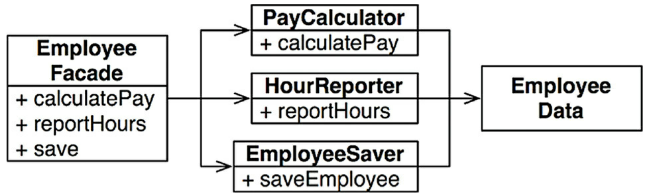
EmployeeFacade chứa rất ít code, thực ra nó chỉ có trách nghiệm khởi tạo và ủy quyền cho các class khác để rồi xử lý mấy cái hàm cần thiết thôi. Ví dụ khi gọi calculatePay() trong EmployeeFacade thì nó sẽ khởi tạo PayCalculator và gọi hàm calculatePay() trong đó.
Một vài developer thích giữ những business rule quan trọng nhất ở gần với dữ liệu. Điều này có thể thực hiện bằng việc giữ các method quan trọng nhất trong class Employee gốc và sau đó sử dụng class này như một Facade để giảm bớt số lượng hàm.
Bạn có thể sẽ phản đối các giải pháp này vì cho rằng mỗi class có mỗi hàm thì ông tách class ra làm chi vậy? Nhưng trên thực tế thì điều này không bao giờ xảy ra. Số lượng hàm cần thiết để tính lương, sinh báo cáo, hoặc lưu dữ liệu sẽ rất lớn trong từng trường hợp. Và mỗi class sẽ có hàng đống private method trong nó.
Mỗi class chứa một họ các phương thức như vậy gọi là một scope. Ở phía ngoài scope, không ai có thể biết về các private member tồn tại.
Kết
Single Responsiblity Principle là để nói về các hàm và các class. Nhưng nó cũng xuất hiện ở các cấp độ khác nhưng dưới hình thức khác. Ở cấp độ components, nó chính là là Common Closure Principle (cái này ai chưa biết thì sau biết). Ở cấp độ architectural, nó chính là Axis of Change, là nguyên tắc cho việc chịu trách nhiệm khi đi xây dựng một Architectural Boundaries. Nói chung nếu tôi có thời gian viết thì chúng ta có thể học về mấy cái thứ này sau này.
Chúc các bạn có một ngày làm việc vui vẻ và hiệu quả!
Dịch và tham khảo từ Clean Architecture: A Craftsman's Guide to Software Structure and Design (Robert C. Martin Series)