1. Động lực
Việc mô hình hóa mối quan tâm của người dùng dựa vào lịch sử hành vi là rất quan trọng đối với mọi hệ thống gợi ý. Các phương pháp trước đây sử dụng các sequential neural network để encode lịch sử tương tác của người dùng từ trái sang phải thành các biểu diễn ẩn để thực hiện gợi ý. Mặc dù có những hiệu quả nhất định, tuy nhiên cách làm này vẫn tồn tại một số hạn chế:
-
Các cấu trúc đơn hướng hạn chế khả năng biểu diễn ẩn chuỗi hành vi người dùng.
-
Thường dựa trên một giả định không linh hoạt về thứ tự trong chuỗi, điều này là không thực tế.
2. Đóng góp
Để giải quyết vấn đề trên, nhóm tác giả đề xuất một sequential recommendation model có tên là BERT4Rec. Mô hình sử dụng một mạng học sâu bidirectional self-attention để mô hình hóa chuỗi hành vi người dùng. Để hạn chế rò rỉ thông tin và train model bidirectional hiệu quả hơn, nhóm tác giả áp dụng Cloze objective trong việc training, dự đoán item được mask ngẫu nhiên trong chuỗi bằng cách cùng điều chỉnh ngữ cảnh bên phải và bên trái. Bằng cách này, ta sẽ có một mô hình bidirectional representation thực hiện gợi ý bằng cách cho phép mỗi item trong lịch sử hành vi người dùng hợp nhất thông tin từ cả bên trái và phải.
3. Phương pháp
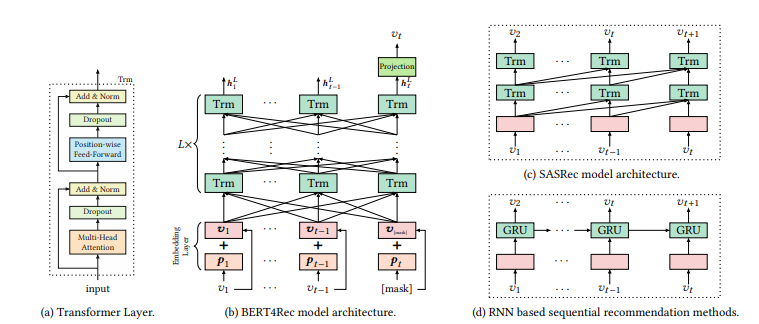
3.1. Mô tả bài toán
Ta đặt là tập các user, là tập các item và danh sách là chuỗi tương tác theo thứ tự thời gian của người dùng , trong đó là item mà đã tương tác tại timestep và là độ dài của chuỗi tương tác của user . Bài toán đặt ra là cho lịch sử tương tác , mục tiêu của hệ thống gợi ý sẽ dự đoán item mà user sẽ tương tác tại timestep . Bài toán có thể được công thức hóa như sau:
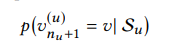
3.2. Model Architecture
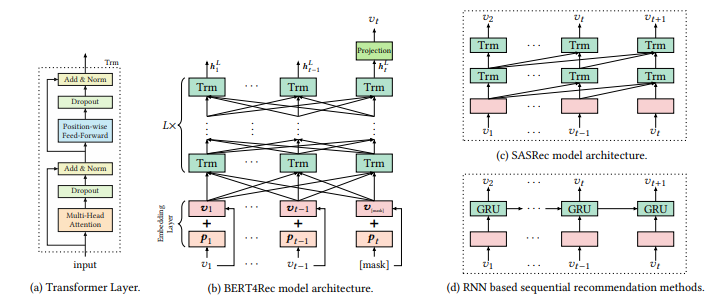
Bản chất, mô hình được để xuất là sử dụng BERT cho một task mới là hệ thống gợi ý. Trong hình b, BERT4Rec được stack bởi lớp Bidirectional Transformer. Tại mỗi layer, mô hình lặp đi lặp lại việc sửa đổi biểu diễn của mọi vị trí bằng cách trao đổi thông tin song song qua tất cả các vị trí ở lớp trước đó. Thay vì cách học truyền thông tin liên quan một cách step by step như RNN tại hình d thì cơ chế self attention mang lại cho BERT4Rec khả năng nắm bắt trực tiếp các phần phụ thuộc ở bất kì khoảng cách nào. Điểm hay của cơ chế này là cho ta một global receptive field, trong khi các phương pháp CNN thì thường cho một receptive field hạn chế. Ngoài ra, ngược lại với RNN, selff attention có thể chạy song song được.
3.3. Transformer Layer
Cho một chuỗi input có độ dài , ta sẽ lặp lại việc tính toán đồng thời biểu diễn tại mỗi layer cho mỗi vị trí bằng cách sử dụng transformer layer. Ta sẽ stack cùng nhau thành một ma trận . Việc này sẽ tận dụng khả năng tính toán đồng thời của GPU. Như trên hình a, Transformer layer Trm bao gồm 2 layer con, một Multi-Head Self-Attention sub-layer và một Position-wise Feed-Forward Network.
Multi-Head Self-Attention. Các cơ chế attention đã trở thành một phần không thể thiếu của việc sequence modeling trong nhiều nhiệm vụ khác nhau, nó cho phép nắm bắt sự phụ thuộc giữa các cặp biểu diễn mà không quan tâm đến khoảng cách của chúng trong chuỗi. Trong model, nhóm tác giả sử dụng multi-head self-attention để khai thác điểm mạnh của cơ chế này.
Đầu tiên, multi-head attention thực hiện chiếu tuyến tính vào không gian con bằng các linear projection khác nhau và learnable. Sau đó, sử dụng hàm attention song song để cho ra biểu diễn output được concat và tiếp tục được project.
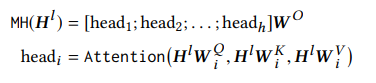
Trong đó, ma trận projection cho mỗi head là , and là các tham số learnable. Các tham số projection không chia sẻ giữa các layer. Tại đây, Attention function là Scaled Dot-Product Attention:
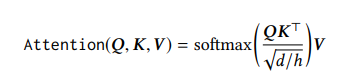
Trong đó, query , key , và value được chiếu từ cùng một ma trận với các ma trận chiếu khác nhau. Temperature được sử dụng để thu được phân phối attention mềm hơn (softer attention distribution) nhằm hạn chế gradient quá nhỏ.
Position-wise Feed-Forward Network. Để ý rằng các self-attention sub-layer chủ yếu dựa trên các phép chiếu tuyến tính. Do đó, ta phải cung cấp tính chất phi tuyến tính và tương tác giữa các chiều khác nhau cho model. Nhóm tác giả sử dụng Position-wise Feed-Forward Network cho các output của self-attention sub-layer riêng biệt và giống hệt nhau tại mỗi vị trí. Nó bao gồm 2 affine transformation cùng với Gaussian Error Linear Unit (GELU) activation như sau:
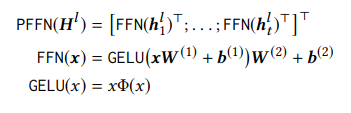
Trong đó, là hàm phân phối tích lũy của phân phối standard gaussian, và là các tham số learnable và chia sẻ giữa các vị trí. Thực tế các tham số này khác nhau giữa các layer.
Stacking Transformer Layer. Bằng các thành phần ở trên, ta đã có thể capture được tương tác giữa người dùng và item sử dụng cơ chế attention. Ta cũng có thể capture được các item transition pattern phức tạp hơn bằng cách stack các self-attention layer. Tuy nhiên, việc này làm cho mô hình sâu hơn và sẽ dẫn đến khó đào tạo hơn. Do vậy, nhóm tác giả sử dụng residual connection giữa mỗi 2 sublayer, tiếp sau đó là normalization layer. Ngoài ra, nhóm tác cũng áp dụng dropout cho đầu ra của mỗi sublayer, trước khi nó được chuẩn hóa. Công thức hóa sẽ như sau

Tổng kết lại, BERT4Rec tinh chỉnh biểu diễn ẩn của mỗi layer như sau:
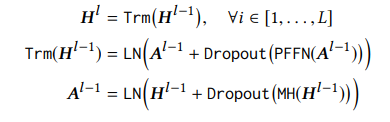
3.4. Embedding Layer
Để tận dụng thông tin vị trí của chuỗi đầu vào, nhóm tác giả tích hợp Positional Embedding vào input item embedding tại phía dưới của Transformer layer stack. Cho item , biểu diễn input tương ứng được xây dựng bằng cách tính tổng embedding của item với positional embedding tương ứng.
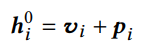
Trong đó, là -dimensional embedding cho item là -dimensional positional embedding cho vị trí . Nhóm tác giả sử dụng learnable positional embedding thay vì fixed sinusoid embeddings để đạt hiệu suất tốt hơn.* Ma trận positional embedding cho phép model xác định phần đầu vào mà nó đang xử lý. Tuy nhiên, nó cũng đặt ra giới hạn về độ dài câu tối đa mà model có thể xử lý. Vì vậy, ta cần cắt bớt chuỗi đầu vào thành item cuối cùng nếu .
3.5. Output Layer
Sau layer ta thu được output cho tất cả item của chuỗi input. Mục tiêu tiếp theo là ta cần dự đoán item tại time step biết rằng item đã bị mask và ta cần dựa vào để dự đoán ra nó. Phân phối xác suất các item được tính như sau:
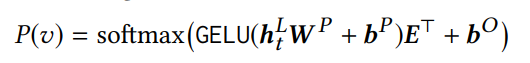
Trong đó là learnable projection matrix, và là các bias, là embedding matrix cho tập item . Nhóm tác giả sử dụng shared item embedding matrix trong lớp đầu vào và đầu ra để hạn chế overfitting và giảm kích thước mô hình.
3.6. Model Learning
Training. Mục tiêu của các mô hình gợi ý là dự đoán item tiếp theo sẽ được tương tác. Cụ thể, trong các mô hình gợi ý đơn hướng, mục tiêu của chuỗi input sẽ là . Tuy nhiên, vì mô hình hiện tại mà nhóm tác giả đề xuất là mô hình 2 chiều nên biểu diễn output cuối cùng của mỗi item có thể mang thông tin của item mục tiêu. Điều này làm cho việc dự đoán trở nên tầm thường và model sẽ không học thêm được gì hữu ích. Một giải pháp đơn giản cho vấn đề này là ta sẽ tạo mẫu từ chuỗi lịch sử hành vi người dùng ban đầu có độ dài , sau đó encode mỗi chuỗi con bằng bidirectional model và dùng để dự đoán item mục tiêu. Cách tiếp cận này có một nhược điểm là rất tốn thời gian và tài nguyên do ta cần tạo mẫu cho mỗi vị trí và thực hiện dự đoán một cách riêng biệt.
Để cho việc training trở nên hiệu quả hơn, nhóm tác sử dụng objective: Cloze task. Hiểu đơn giản là ta sẽ che đi một số t ừ và phải dự đoán từ đó là gì dựa vào các từ còn lại. Trong trường hợp này, tại mỗi bước training, nhóm tác giả sẽ ngẫu nhiên mask item trong chuỗi đầu vào với tỷ lệ là và sau đó dự đoán id của item bị mask đó dựa vào context bên trái và bên phải. Cụ thể như mô tả dưới:
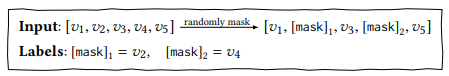
Hàm loss được sử dụng là negative log-likelihood
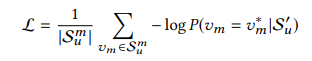
Trong đó là phiên bản đã mask của lịch sử hành vi người dùng là các item được mask ngẫu nhiên trong đó, là nhãn của item bị mask.
Một điểm lợi của Cloze task là nó có thể sinh nhiều mẫu để train model. Giả sử với chuỗi có độ dài , BERT4Rec có thể xác định mẫu (trong đó ta mask ngẫu nhiên item) tại nhiều epoch. Điều này cho phép việc training bidirectional model hiệu quả hơn.
Testing. Cách làm trên bị phát sinh một thiếu sót là Cloze objective thực hiện dự đoán item bị mask hiện tại trong khi hệ thống gợi ý cần dự đoán item ở trong tương lai. Để giải quyết vấn đề này, nhóm tác giả thêm một token "[mask]" vào cuối chuỗi hành vi của người dùng và dự đoán item tiếp theo dựa vào biểu diễn ẩn cuối cùng của token này, rất tường minh 
4. Thực nghiệm
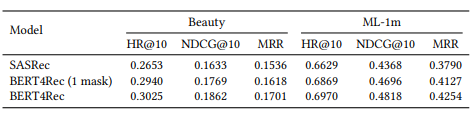
Bảng dưới là kết quả so sánh phương pháp đề xuất với các phương pháp khác trên 4 bộ dữ liệu khác nhau.
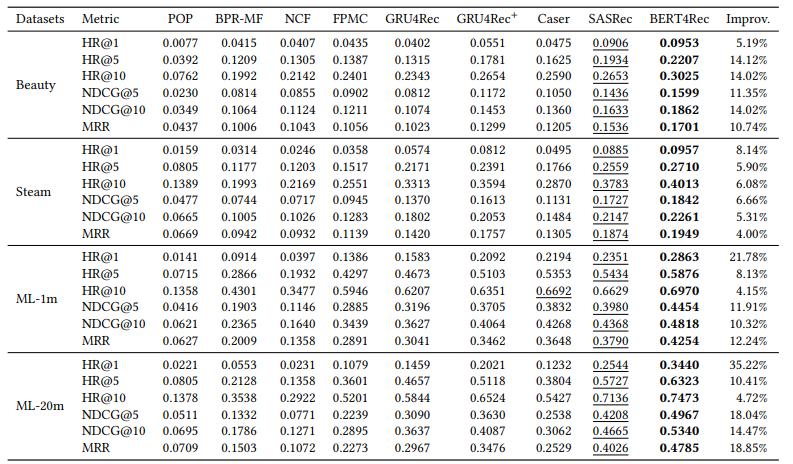
Nhận thấy rằng kết quả của BERT4Rec cao hơn các method còn lại. Vậy thì sự hiệu quả này đến từ bidirectional self-attention model hay từ Cloze objective? Để trả lời câu hỏi này, nhóm tác giả tách biệt tác động của hai yếu tố bằng cách hạn chế Cloze task chỉ mask một item tại một thời điểm. Theo cách này, sự khác biệt chính giữa BERT4Rec (với 1 mask) và SASRec là BERT4Rec dự đoán mục tiêu dựa vào cả context bên trái và bên phải. Kết quả cho thấy BERT4Rec với 1 mask vượt trội đáng kể so với SASRec trên tất cả các chỉ số. Nó cho thấy tầm quan trọng của các biểu diễn hai chiều đối trong việc gợi ý tuần tự. Ngoài ra, hai hàng cuối cùng chỉ ra rằng Cloze objective cũng cải thiện hiệu suất.
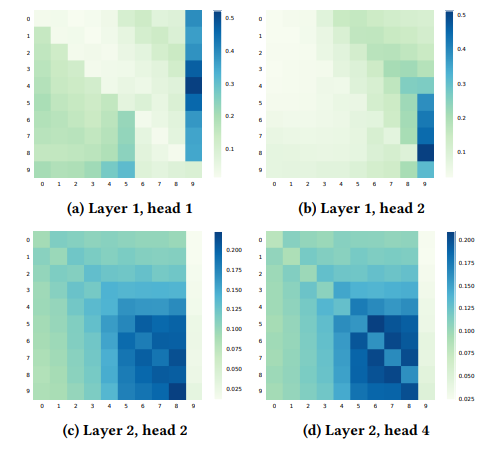
Hình dưới là heatmap mô tả trung bình trọng số của vị trí bị mask cuối cùng. Ta có thể có một số quan sát quan trọng rằng:
-
Attention là đa dạng với các head và layer khác nhau
-
Các model đơn chiều chỉ tập trung vào một phía, model hai chiều tập trung vào cả 2 phía.
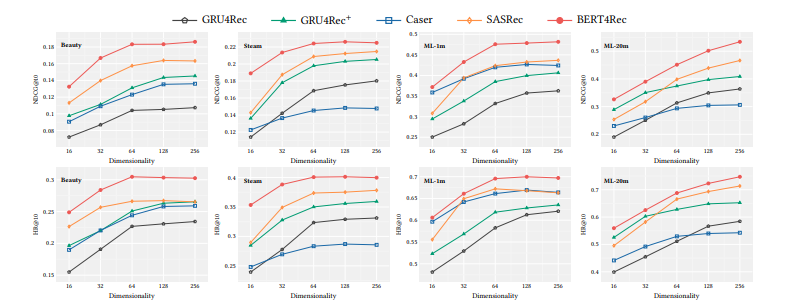
Nhóm tác giả đánh giá tác động của khác nhau và nhận thấy rằng, hiệu suất tốt đạt được khi
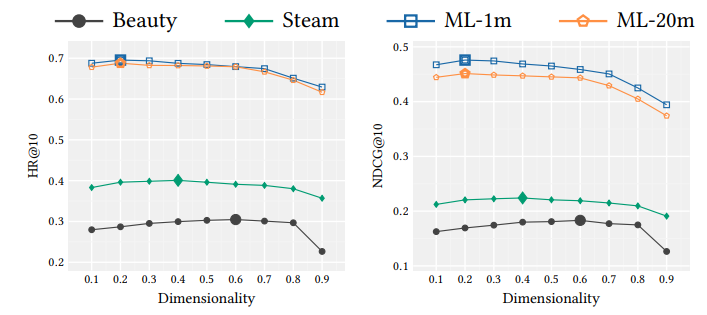
Nhóm tác giả cũng đánh giá tác động của lên hiệu suất mô hình. Kết quả được visualize trong biểu đồ dưới đây. Đúng ra chạy từ 0.1 tới 0.9 nhưng tác giả để tên trục hoành nhầm là Dimensionality
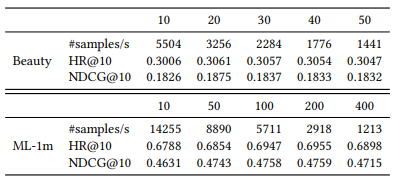
Với độ dài input khác nhau, kết quả như sau. Nhận thấy rằng với lớn thì chưa chắc model cho ra hiệu suất tốt vì có thể có thêm nhiều noise.
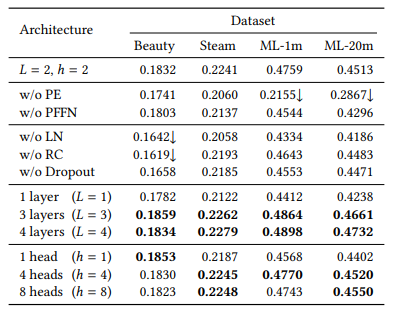
Bảng dưới thể hiện mức độ ảnh hưởng của các thành phần trong model elên độ chính xác.
5. Kết luận
Điểm đáng chú ý của bài báo là khai thác ý tưởng bidirectional model để học được context cả bên trái và bên phải. Tuy nhiên, method mà bài báo đề xuất bị ảnh hưởng khá nhiều đến các tham số độc lập. Các tham số này cần được tinh chỉnh sao cho phù hợp với những bộ dữ liệu khác nhau.
6. Tham khảo
[1] BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
[2] FeiSun/BERT4Rec: BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer (github.com)