1. Động lực
Các hệ thống gợi ý tin tức giúp cho người dùng tìm được những tin bài mà họ thật sự muốn quan tâm. Việc mô hình hóa chính xác các tin tức và thông tin user là rất cần thiết cho hệ thống gợi ý tin tức. Đặc biệt, nắm bắt được context của các từ và tin bài là ý tưởng chủ chốt để học được những biểu diễn của tin bài và user.
2. Đóng góp
Nhóm tác giả đề xuất cách tiếp cận mô hình hóa tin bài sử dụng multi-head self-attention (NRMS). Cốt lõi của cách tiếp cận này là sử dụng một news encoder và một user encoder. Ý tưởng như sau:
-
Trong news encoder, nhóm tác giả sử dụng multi-head self-attention để học các biểu diễn tin bài từ tiêu đề bằng cách mô hình hóa sự tương tác giữa các từ.
-
User encoder học biểu diễn của user thông qua các tin bài đã xem của họ và sử dụng multi-head self-attention để nắm bắt sự liên quan giữa các tin bài.
Bên cạnh đó, nhóm tác giả cũng sử dụng attention để học thêm nhiều thông tin hơn từ tin bài và biểu diễn của user bằng cách chọn các từ và tin bài quan trọng.
3. Phương pháp
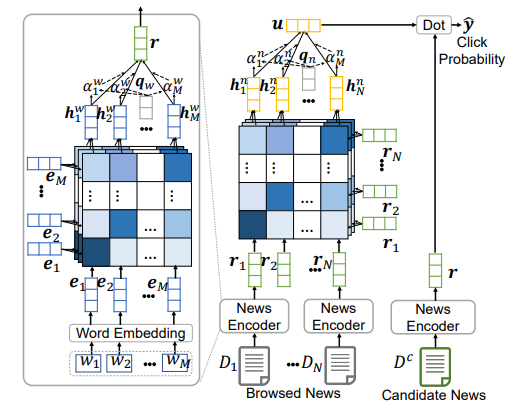
3.1. News Encoder
Module news encoder được dùng để học biểu diễn của tin bài. Module này gồm 3 layer. Layer đầu tiên là word embedding được sử dụng để convert tiêu đề của tin bài từ một chuỗi các từ thành một chuỗi embedding vector thấp chiều (low-dimensional).
Layer thứ 2 là word-level multi-head self-attention network. Ta giả định rằng, sự tương tác giữa các từ trong tiêu đề là quan trọng cho việc học biểu diễn tin bài. Dựa vào quan sát rằng, các từ trong tiêu đề có mức độ quan trọng đối với nội dung tin bài khác nhau và một từ có thể tương tác với nhiều từ khác. Nhóm tác giả đề xuất sử dụng self-attention để học biểu diễn context của từ bằng cách capture sự tương tác giữa các từ này. Biểu diễn của từ được học bởi attention head được tính như sau:
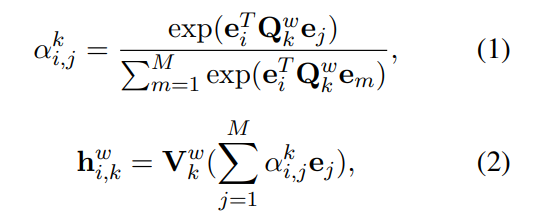
trong đó và là projection parameters trong self-attention head . biểu thị mức độ quan trọng tương đối của tương tác giữa từ thứ và từ thứ . Biểu diễn multi-head của từ thứ là concat của các biểu diễn self-attention head riêng biệt.
Lớp thứ 3 là một neural network additive attention để chọn các từ quan trọng trong news title để học các biểu diễn thông tin tin bài hiệu quả hơn. Trọng số attention của từ thứ trong một new title được tính như sau:
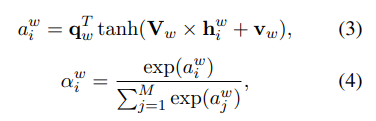
Trong đó và là các projection parameter và là query vector. Biểu diễn cuối cùng của tiêu đề tin bài là tổng có trọng số của biểu diễn context word.
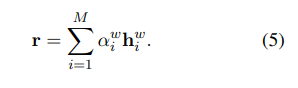
3.2. User Encoder
User encoder được dùng để học biểu diễn của user từ các tin bài mà họ đã xem. Dựa trên ý tưởng các tin bài người dùng xem có sự liên quan tới nhau. Nhóm tác giả đề xuất sử dụng multi-head self-attention để nâng cao khả năng biểu diễn tin bài bằng cách capture sự tương tác giữa chúng. Biểu diễn của tin bài được học bởi attention head được tính như sau:
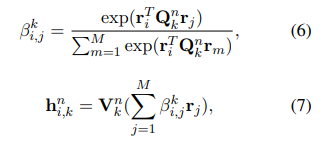
trong đó và là các tham số của các self-attention head tin bài. biểu diễn tương tác giữa tin bài và .
Lớp tiếp theo là một mạng additive attention chọn tin bài quan trọng để học nhiều thông tin biểu diễn user hơn. Trọng số attention của tin bài được tính như sau:
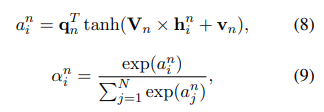
trong đó và là các tham số của mạng attention và là số tin bài đã xem. Biểu diễn cuối cùng của user được tính như sau:
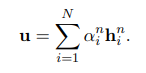
3.3. Click Predictor
Click predictor module được sử dụng để dự đoán xác suất người dùng click vào một tin bài ứng cử viên. Xác xuất đó được tính bằng tích vô hướng của vector biểu diễn user và vector biểu diễn tin bài.
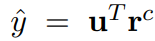
Nhóm tác giả cũng nghiên cứu các phương pháp scoring khác nhưng tích vô hướng vẫn hiệu quả và cho hiệu suất tốt nhất.
3.4. Model Training
Nhóm tác giải sử dụng kĩ thuật negative sampling để huấn liên model. Ý tưởng như sau:
-
Với mỗi tin bài được xem bởi user (positive sample), ta lấy ngẫu nhiên mẫu tin bài cũng được hiển thị cùng lúc nhưng user không click vào (negative sample).
-
Shuffle thứ tự tin bài để tránh positional biases (hiểu đơn giản là vị trí tin bài trên bảng tin ảnh hưởng rất nhiều đến việc user click vào xem). Công thức tính xác suất user click vào 1 postive sample được chuẩn hóa như sau:
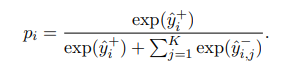
Loss function sử dụng là negative log-likelihood của tất cả positive sample được tính như sau:
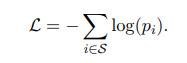
4. Thực nghiệm
Nhóm tác giả thực nghiệm trên bộ dữ liệu thực tế với thống kê như sau

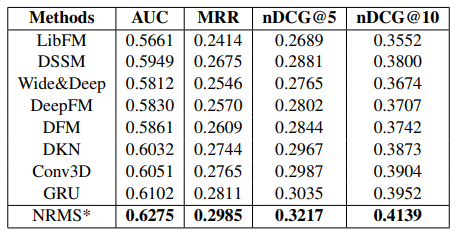
Kết quả thực nghiệm như sau, ta thấy kết quả của phương pháp sử dụng neural network tốt hơn các phương pháp truyền thống. Đặc biệt, phương pháp đề xuất NRMS tốt hơn các phương pháp còn lại.
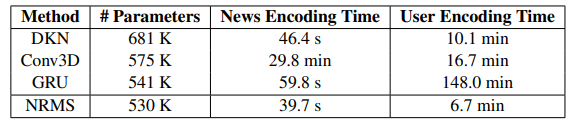
Nhóm tác giả cũng thực hiện đo lường thời gian encoding với các method khác.
Nhóm tác giả thực hiện đó mức độ hiệu quả của việc áp dụng cơ chế attention vào method.
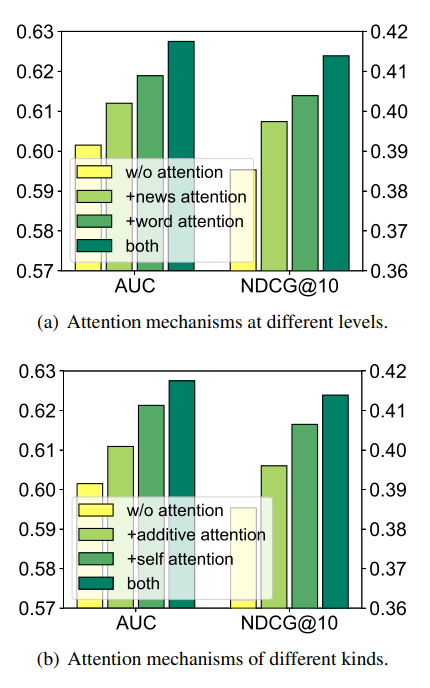
5. Kết luận
Ý tưởng của bài báo khá clear và đơn giản. Kiến trúc sử dụng chủ yếu cơ chế attention (cụ thể là self attention và additive attention) với các quan sát rất tự nhiên như: Các tin bài của cùng 1 người dùng có sự liên quan tới nhau, Các từ trong tiêu đề của tin bài có mức độ quan trọng và tương tác khác nhau,...
6. Tham khảo
[1] EMNLP2019-NRMS.pdf (wuch15.github.io)
[2] Recommender Systems: Machine Learning Metrics and Business Metrics - neptune.ai
[3] wuch15/EMNLP2019-NRMS: The source codes for the paper "Neural News Recommendation with Multi-Head Self-Attention". (github.com)