Đóng góp của bài báo
Các bài toán OCR luôn được sự quan tâm trong giới AI nhờ khả năng ứng dụng rộng rãi 😀 Một thách thức lớn mà các model hiện tại gặp phải khi giải quyết bài toán này đó là các scene image được chụp từ nhiều điều kiện môi trường khác nhau, do đó text có thể bị che khuất, mờ, nhiễu,... điều này rất khó để model có thể nhận biết được nội dung text trong ảnh.
Cũng như con người, khi mà đọc một văn bản mà có một số chữ bị mờ, khó đọc hay bị che khuất, ta sẽ dự đoán từ khó đọc đó dựa vào các từ xung quanh, hay nói cách khác là dựa vào ngữ nghĩa của các từ xung quanh từ đó. Ví dụ trong câu: "Halley mới mua cây mask mới để chơi cầu lông". Dựa vào ngữ nghĩa các từ xung quanh, ta đoán được khả năng cao mask chính là từ "vợt" đúng không nào 😀
Ý tưởng trên được áp dụng cho nhiều model, tuy nhiên, làm thế nào để mô hình hóa hành vi ngôn ngữ trong quá trình đọc của con người một cách hiệu quả vẫn là một vấn đề khoai 😀 Tuy nhiên ta có một số nhận xét sau:
- Nếu không nhìn được từ ta có thể dùng những tri thức về ngôn ngữ đề dự đoán ra từ đó. Hay nói một cách khác đây là 2 phần độc lập với nhau nhưng bổ trợ cho nhau. Vậy ta có thể thiết kế vision model và language model độc lập và kết hợp chúng cho việc suy đoán văn bản.
- Có thể dựa vào các ký tự dễ đọc bên trái và bên phải của ký tự khó đọc để suy ra từ khó đọc là gì.
- Cải thiện độ tin cậy của dự đoán bằng cách sửa lặp đi lặp lại đến khi đúng thì mới oke 😀
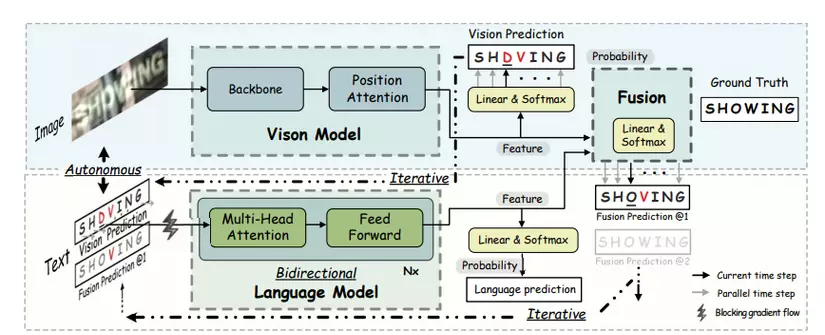
Qua các vấn đề và ý tưởng trên, bài báo đề xuất một hướng tiếp cận áp dụng language knowledge vào scene text recognition một cách hiệu quả có tên ABINet. Ba đặc điểm chính của ABINet là Autonomous, Bidirectional, và Iterative.
- Autonomous, cho phép thiết lập mô hình ngôn ngữ độc lập và rõ ràng bằng cách chặn gradient flow giữa visual model và language model
- Bidirectional, nghĩa là học biểu diễn văn bản bằng cách thao tác trên ngữ cảnh của các ký tự trong các điều kiện chung theo hai chiều
- Iterative, từng bước hiệu chỉnh dự đoán để giảm thiểu tác động của nhiễu đầu vào. Trên cơ sở đó, bài báo này đề xuất thêm một phương pháp self training tích hợp cho semi-supervised learning. Kết quả thử nghiệm standard benchmark cho thấy tính ưu việt của phương pháp này, đặc biệt là trên các hình ảnh có chất lượng thấp.
Phương pháp đề xuất
Kiến trúc tổng quan của ABINet
Vision Model
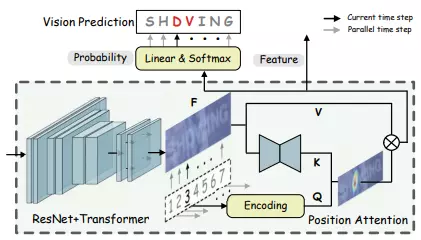
Vision model bao gồm một backbone network và một positional attention module. Feature extraction network và sequence modeling network là ResNet + Transformer. Với một ảnh ta có
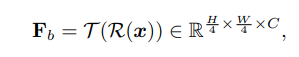
trong đó , là kích thước của ảnh và là feature dimension.
Positional attention module dựa trên mô hình truy vấn, mô hình này chuyển đổi song song các visual feature thành các xác suất ký tự:
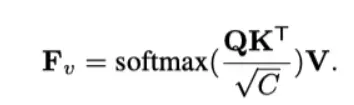
Cụ thể, là positional encodings của thứ tự các kí tự và là độ dài chuỗi kí tự , trong đó được cài đặt bởi mini U-net. , trong đó là identity mapping.
Phần vision model backbone được cài đặt như sau:
from fastai.vision import * from modules.model import _default_tfmer_cfg
from modules.resnet import resnet45
from modules.transformer import (PositionalEncoding, TransformerEncoder, TransformerEncoderLayer) class ResTranformer(nn.Module): def __init__(self, config): super().__init__() self.resnet = resnet45() self.d_model = ifnone(config.model_vision_d_model, _default_tfmer_cfg['d_model']) nhead = ifnone(config.model_vision_nhead, _default_tfmer_cfg['nhead']) d_inner = ifnone(config.model_vision_d_inner, _default_tfmer_cfg['d_inner']) dropout = ifnone(config.model_vision_dropout, _default_tfmer_cfg['dropout']) activation = ifnone(config.model_vision_activation, _default_tfmer_cfg['activation']) num_layers = ifnone(config.model_vision_backbone_ln, 2) self.pos_encoder = PositionalEncoding(self.d_model, max_len=8*32) encoder_layer = TransformerEncoderLayer(d_model=self.d_model, nhead=nhead, dim_feedforward=d_inner, dropout=dropout, activation=activation) self.transformer = TransformerEncoder(encoder_layer, num_layers) def forward(self, images): feature = self.resnet(images) n, c, h, w = feature.shape feature = feature.view(n, c, -1).permute(2, 0, 1) feature = self.pos_encoder(feature) feature = self.transformer(feature) feature = feature.permute(1, 2, 0).view(n, c, h, w) return feature
Language Model
Chiến lược Autonomous
Chiến lược Autonomous gồm những đặc điểm sau:
- Language Model được sử dụng như một spell correction model độc lập. Trong đó vector xác suất của kí tự là input và output là phân phối xác suất của các ký tự mong muốn
- Chặn training gradient flow tại input vector
- Language Model được đào tạo riêng biệt từ text data không được gán nhãn
Bidirectional Representation
Các cách tiếp cận trước đây thường sử dụng mô hình tích hợp của hai mô hình một chiều, về cơ bản là các biểu diễn một chiều. So với biểu diễn hai chiều, biểu diễn một chiều về cơ bản nắm được 1/2 thông tin , dẫn đến khả năng trích xuất đặc trưng bị hạn chế.
BCN (Bidirectional Cloze Network) là một biến thể của L-layer transformer decoder. Mỗi layer của BCN là một chuỗi các multi-headed feed-forward networks, residual connections và layer normalization.
Không như transformer thông thường, BCN lấy vị trí ký tự mã hóa theo thứ tự (character position ordinal encoding) làm đầu vào, là một vectơ xác suất không phải ký tự. Vector xác suất ký tự được truyền trực tiếp vào trong multi-head attention module. Mặt khác, trong multi-head attention, diagonal attention mask được thiết kế để ngăn các kí tự “tự nhìn thấy chúng”. Ngoài ra, BCN không sử dụng self-attention để tránh rò rỉ thông tin qua các time step. Vì vậy, việc tính toán từng time step của BCN là độc lập và song song, đồng thời cũng mang lại hiệu quả cao.
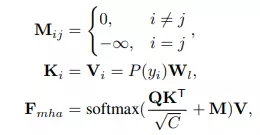
Ma trận là ma trận attention sử dụng để tránh việc nhận thông tin của ký tự hiện tại.
Bằng cách chỉ định attention mask theo kiểu điền vào chỗ trống, BCN có thể học các biểu diễn hai chiều mạnh mẽ hơn so với học thông tin biểu diễn một chiều. Đặc biệt, nhờ kiến trúc giống như transformer, các BCN có thể thực hiện các phép tính một cách độc lập và song song. Ngoài ra, vì chỉ cần một nửa số lượng tính toán và tham số nên model mang lại hiệu quả cao.
Module BCN được cài đặt như sau:
class BCNLanguage(Model): def __init__(self, config): super().__init__(config) d_model = ifnone(config.model_language_d_model, _default_tfmer_cfg['d_model']) nhead = ifnone(config.model_language_nhead, _default_tfmer_cfg['nhead']) d_inner = ifnone(config.model_language_d_inner, _default_tfmer_cfg['d_inner']) dropout = ifnone(config.model_language_dropout, _default_tfmer_cfg['dropout']) activation = ifnone(config.model_language_activation, _default_tfmer_cfg['activation']) num_layers = ifnone(config.model_language_num_layers, 4) self.d_model = d_model self.detach = ifnone(config.model_language_detach, True) self.use_self_attn = ifnone(config.model_language_use_self_attn, False) self.loss_weight = ifnone(config.model_language_loss_weight, 1.0) self.max_length = config.dataset_max_length + 1 # additional stop token self.debug = ifnone(config.global_debug, False) self.proj = nn.Linear(self.charset.num_classes, d_model, False) self.token_encoder = PositionalEncoding(d_model, max_len=self.max_length) self.pos_encoder = PositionalEncoding(d_model, dropout=0, max_len=self.max_length) decoder_layer = TransformerDecoderLayer(d_model, nhead, d_inner, dropout, activation, self_attn=self.use_self_attn, debug=self.debug) self.model = TransformerDecoder(decoder_layer, num_layers) self.cls = nn.Linear(d_model, self.charset.num_classes) if config.model_language_checkpoint is not None: logging.info(f'Read language model from {config.model_language_checkpoint}.') self.load(config.model_language_checkpoint) def forward(self, tokens, lengths): """ Args: tokens: (N, T, C) where T is length, N is batch size and C is classes number lengths: (N,) """ if self.detach: tokens = tokens.detach() embed = self.proj(tokens) # (N, T, E) embed = embed.permute(1, 0, 2) # (T, N, E) embed = self.token_encoder(embed) # (T, N, E) padding_mask = self._get_padding_mask(lengths, self.max_length) zeros = embed.new_zeros(*embed.shape) qeury = self.pos_encoder(zeros) location_mask = self._get_location_mask(self.max_length, tokens.device) output = self.model(qeury, embed, tgt_key_padding_mask=padding_mask, memory_mask=location_mask, memory_key_padding_mask=padding_mask) # (T, N, E) output = output.permute(1, 0, 2) # (N, T, E) logits = self.cls(output) # (N, T, C) pt_lengths = self._get_length(logits) res = {'feature': output, 'logits': logits, 'pt_lengths': pt_lengths, 'loss_weight':self.loss_weight, 'name': 'language'} return res
Iterative Correction
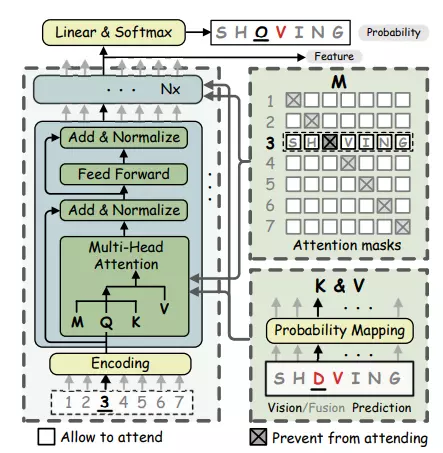
Việc dự đoán song song của transformer yêu cầu noise input, thường là giá trị gần đúng của visual prediction hoặc visual feature.

Cụ thể, như trong hình trên, tại biểu diễn hai chiều, điều kiện của ("O") là "SH-WING". Nhưng do ảnh bị mờ và bị che khuất, visual model cho kết quả là "SH-VING", trong đó "V" trở thành nhiễu, điều này làm giảm độ tin cậy của dự đoán. Do đó, kết quả của visual model giờ đây lại trở thành nhiễu của language model.
Để giải quyết vấn đề noise input, bài báo đề xuất một iterative language model. Language model lặp lại lần, thực hiện các phân bổ khác nhau cho ( là vector xác suất các kí tự và là đầu ra của visual model). Với lần lặp đầu tiên, mục tiêu của language model là sửa output của visual model. Đối với các lần lặp tiếp theo, mục tiêu của bản sửa lỗi là kết quả của lần sửa trước đó. Bằng cách này, language model có thể cho ra được kết quả dự đoán chính xác.
Ta implement cho ý tưởng này như sau:
import torch
import torch.nn.functional as F
from fastai.vision import * from .model_vision import BaseVision
from .model_language import BCNLanguage
from .model_alignment import BaseAlignment class ABINetIterModel(nn.Module): def __init__(self, config): super().__init__() self.iter_size = ifnone(config.model_iter_size, 1) self.max_length = config.dataset_max_length + 1 # additional stop token self.vision = BaseVision(config) self.language = BCNLanguage(config) self.alignment = BaseAlignment(config) self.export = config.export def forward(self, images, *args): v_res = self.vision(images) a_res = v_res all_l_res, all_a_res = [], [] for _ in range(self.iter_size): tokens = torch.softmax(a_res['logits'], dim=-1) lengths = a_res['pt_lengths'] lengths.clamp_(2, self.max_length) l_res = self.language(tokens, lengths) all_l_res.append(l_res) a_res = self.alignment(l_res['feature'], v_res['feature']) all_a_res.append(a_res) if self.export: return F.softmax(a_res['logits'], dim=2), a_res['pt_lengths'] if self.training: return all_a_res, all_l_res, v_res else: return a_res, all_l_res[-1], v_res
Fusion
Visual model được train trên hình ảnh và language model được train trên văn bản theo các phương thức khác nhau. Để căn chỉnh visual feature và linguistic feature, ta thực hiện như sau:
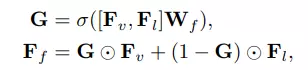
trong đó và .
Ta implement phần này như sau:
import torch
import torch.nn as nn
from fastai.vision import * from modules.model import Model, _default_tfmer_cfg class BaseAlignment(Model): def __init__(self, config): super().__init__(config) d_model = ifnone(config.model_alignment_d_model, _default_tfmer_cfg['d_model']) self.loss_weight = ifnone(config.model_alignment_loss_weight, 1.0) self.max_length = config.dataset_max_length + 1 # additional stop token self.w_att = nn.Linear(2 * d_model, d_model) self.cls = nn.Linear(d_model, self.charset.num_classes) def forward(self, l_feature, v_feature): """ Args: l_feature: (N, T, E) where T is length, N is batch size and d is dim of model v_feature: (N, T, E) shape the same as l_feature l_lengths: (N,) v_lengths: (N,) """ f = torch.cat((l_feature, v_feature), dim=2) f_att = torch.sigmoid(self.w_att(f)) output = f_att * v_feature + (1 - f_att) * l_feature logits = self.cls(output) # (N, T, C) pt_lengths = self._get_length(logits) return {'logits': logits, 'pt_lengths': pt_lengths, 'loss_weight':self.loss_weight, 'name': 'alignment'}
Supervised Training
ABINet được train "end-to-end" sử dụng multitask objective như sau:
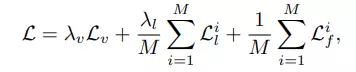
trong đó và là các cross entropy loss từ , và tương ứng. và là các loss tại lần lặp thứ . và là các trọng số.
Thực nghiệm
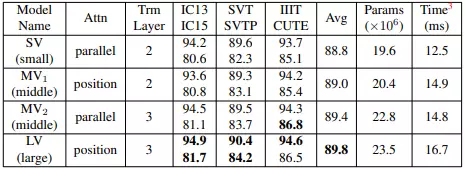
Bảng dưới là kết quả của mô hình khi sử dụng các cấu hình khác nhau của visual model. Attn là phương pháp attention và Trm Layer là số layer của Transformer.
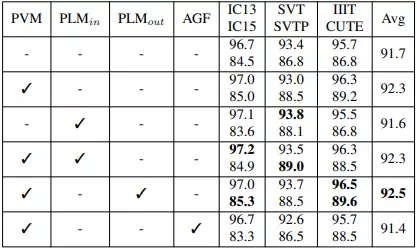
Bảng dưới là kết quả khi sử dụng autonomous strategy. PVM là pretraining visual model được supervised training trên 2 tập dữ liệu là MJSynth và SynthText. PLM_in là pretraining language model được self-supervised training sử dụng text trong 2 tập dữ liệu MJSynth và SynthText. PLM_out là pretraining language model được self-supervised training trên tập WikiText-103. AGF là allowing gradient flow giữa visual model và language model.
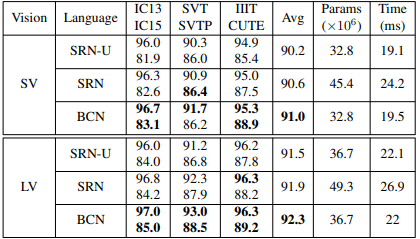
Bảng dưới là so sánh kết quả khi sử dụng và không sử dụng học bidirectional representation.
Visualization của top-5 xác suất trong BCN 
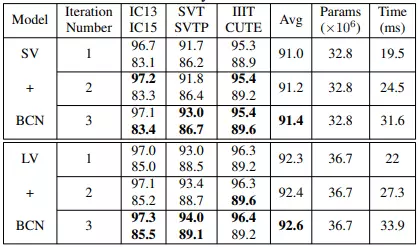
Bảng dưới là kết quả khi so sánh số lần lặp khác nhau.
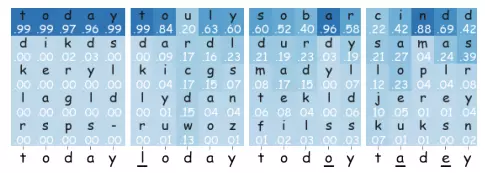
Hình dưới là kết quả khi thực hiện việc sửa lặp sửa chính tả. Các văn bản trong hình lần lượt là ground truth, vision prediction, fusion prediction không có iterative correction và có iterative correction.

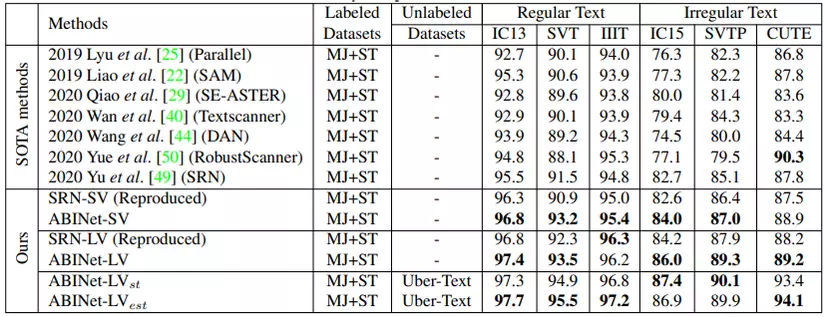
Bảng dưới là kết quả so sánh với các phương pháp khác nhau.