Xin chào mọi người hôm nay mình sẽ tiếp tục viết chủ đề mình hay viết: phân tích dữ liệu và trực quan hóa dữ liệu, tuy nhiên, thay vì mình sử dụng ngôn ngữ python thì mình sử dụng ngôn ngữ lập trình R. Trong bài viết này chúng ta sẽ cùng nhau học cách phân tích dữ liệu đơn giản nhất trên tập dữ liệu mà chúng ta có bằng ngôn ngữ R.
Cùng bắt đầu với R
Download và Install R | RStudio
Ngôn ngữ lập trình R cung cấp một bộ thư viện có sẵn giúp chúng ta có thể dễ dàng xây dựng hình ảnh trực quan với lượng code ít nhất và linh hoạt. Mọi người có thể tiến hành Download tại đây theo hdh mà mình đang sử dụng và tiếp theo chúng ta cài đặt theo các bước được hướng dẫn. Ở dưới đây mình sẽ hướng dẫn cài trên Ubuntu nhé
# update indices
sudo apt update -qq
# install two helper packages we need
apt install --no-install-recommends software-properties-common dirmngr
# import the signing key (by Michael Rutter) for these repo
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E298A3A825C0D65DFD57CBB651716619E084DAB9
Sau đó:
apt install --no-install-recommends r-base Vậy là chúng ta đã cài xong r-base rồi cùng test thử nào
 Hình: r-base
Hình: r-base
Để có thể sử dụng cũng như code một cách đơn giản và nhanh gọn hơn thì chúng ta nên cài thêm RStudio nữa. Download RStudio tại đây
sudo apt install gdebi-core
cd Downloads/
wget https://download1.rstudio.org/rstudio-1.0.143-amd64.deb
sudo apt-get install ./rstudio-1.0.143-amd64.deb
Sau khi cài xong chúng ta thử mở ra xem ok chưa nhé.
 Hình: RStudio
Hình: RStudio
Install R packages
Giống như trong python thì để có thể install một packages trong R khi chúng ta cần thiết thì sử dụng lệnh như sau: Ví dụ ở đây mình install "gplots" :
install.packages('gplots')
Một số hàm hữu ích trong R
DataFrame, Matrices, Vectors
Tương tự như trong Python, Dataframe lưu trữ các giá trị với các kiểu dữ liệu khác nhau. Ma trận lưu trưc các giá trị cùng một kiểu dữ liệu. Vector là mảng 1-d chiều.
Toán tử Assignment
Ở trong R chúng ta có thể dùng <- hoặc = đều được
Hàm c()
Hàm c() là một hàm rất hữu ích được sử dụng để tạo vectors (hoặc mảng 1-d), nối hai hay nhiều vector với nhau
myarray <- c( 1, 2, 3.4, c(2, 4))
Hàm paste()
Hàm paste() sử dụng để nối các chuỗi, rất hữu ích lúc in ra kết quả:
paste(“The dimensions of the data frame are “, paste (dim(data.frame), collapse = ‘, ‘))
Truy cập vào rows và columns
Chúng ta có thể truy nhập vào cột của dataframe sử dụng $. Ví dụ:
data.frame$Name
để có được một tập con của hàng và cột, chúng ta làm như sau: ví dụ để lấy hàng 10 đến 12 và cột 4 đến cột 5:
data.frame[10:12,4:5]
Để truy cập vào các hàng và cột không liên tiếp thì sử dụng hàm c() như bên trên nhé các bạn. Ví dụ để lấy các hàng từ 1 đến 5, 7 và 11 và các cột 3 đến 4 và 7
data.frame[c(1:5, 7, 11), c(3:4, 7)]
Số hàng
Khi muốn kiểm tra số hàng trong dataframe
number.of.rows = nrow(data.frame)
Đếm giá trị NA
sum(is.na(data.frame))
Xóa hàng và cột
để xóa cột:
data.frame$ColumnName <- NULL
Để xóa hàng 1, 3 và 4 sử dụng:
data.frame <- data.frame[-c(1,3,4)]
Phân tích và trực quan hóa dữ liệu Titanic
Ở đây mình sử dụng tập training của titanic làm dataset, mọi người có thể tải về tại đây
Read and view data
titanic = read.csv("~/Downloads/train.csv", na.strings = '')
Sau khi đọc xong thì thử view xem như thế nào nè.
View(titanic)
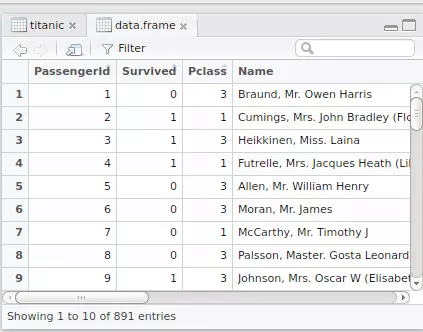 Hình: data titanic
Hình: data titanic
head(titanic, n)| tail(titanic, n)
Để xem nhanh về dữ liệu thì chúng ta thường sử dụng 2 hàm head() và tail()
head(titanic, 10)
 Hình: 10 hàng đầu trong data set
tail(titanic)
Hình: 10 hàng đầu trong data set
tail(titanic)
 Hình: 5 hàng cuối trong dataset
Ở hàm head chúng ta sẽ thấy show ra 10 hàng của dữ liệu, còn hàm tail mình không thêm nên mặc định là 5, khá là giống với mặc định trong python.
Hình: 5 hàng cuối trong dataset
Ở hàm head chúng ta sẽ thấy show ra 10 hàng của dữ liệu, còn hàm tail mình không thêm nên mặc định là 5, khá là giống với mặc định trong python.
names(titanic)
Tiếp theo để lấy ra tất cả các biến trong Dataframe này:
 Hình: Tất cả tên columns
Hình: Tất cả tên columns
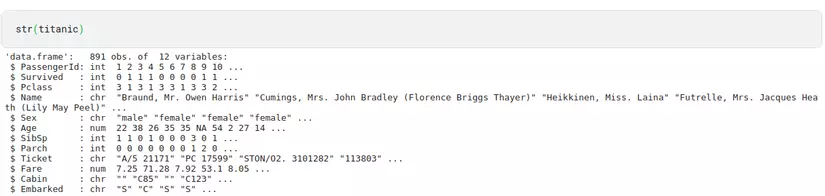
str(titanic)
Việc này giúp chúng ta hiểu cấu trúc dữ liệu, kiểu dữ liệu của từng thuộc tính, và số hàng số cột có trong dữ liệu
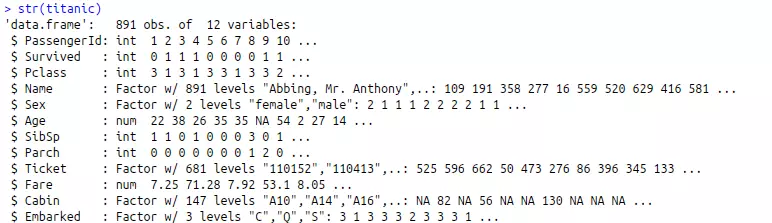 Hình: str
Hình: str
Ở hình trên chúng ta thấy cột "Embarked có giá trị " " " vì vậy chúng ta sẽ chuyển giá trị " " thành "C" nhé
titanic$Embarked[titanic$Embarked==""]="C"
str(titanic)
kết quả chúng ta sẽ được như sau:
summary(titanic)
 summary là một trong những hàm quan trọng nhất giúp tóm tắt từng thuộc tính trong tập dữ liệu chúng ta có. Mình thấy khá là giống với hàm describe() trong python.
summary là một trong những hàm quan trọng nhất giúp tóm tắt từng thuộc tính trong tập dữ liệu chúng ta có. Mình thấy khá là giống với hàm describe() trong python.
Kiểm tra dữ liệu null
Như ở trên mình có nhắc đến hàm sum để đếm giá trị NA thì chúng ta cùng kiểm tra xem data này có nhiều giá trị NA không nhé.
sum(is.na(titanic))
Kết qủa của chúng ta sẽ được như sau:
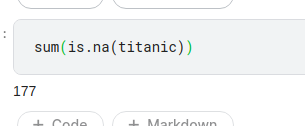 Hình: giá trị na
Hình: giá trị na
Tuy nhiên nếu chỉ dựa vaò hình trên thì làm sao biết được cột nào đang chứa giá trị NA nhỉ, vì vậy mình đã tìm được hàm sau đây
colSums(is.na(titanic))
Hàm này để kiểm tra cột nào đang chứa giá trị NA.

Hình: columns bị na
Ở hình trên chúng ta thấy cột Age đang bị NA
Tiếp theo chúng ta sẽ chuyển các columns: "Survived","Pclass","Sex","Embarked" thành factor nhé:
cols<-c("Survived","Pclass","Sex","Embarked")
for (i in cols){ titanic[,i] <- as.factor(titanic[,i])
}
str(titanic)

Visualize
Một số thư viện mình dùng trong này:
library(ggplot2)
library(dplyr)
library(GGally)
library(rpart)
library(rpart.plot)
Đầu tiên câu hỏi mà chúng ta sẽ luôn quan tâm là: có bao nhiêu người sống sót trên chuyến tàu này đúng không?
ggplot(titanic, aes(x=Survived)) + geom_bar()
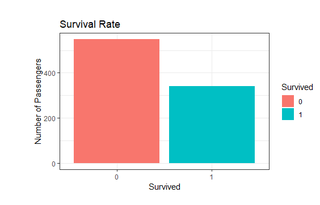 Hình: số người sống sót trên khoang tàu
Hình: số người sống sót trên khoang tàu
Ở hình trên trục X: 0 để biểu thị người không sống sót, 1 để biểu thị người sống sót. Trục Y: đại diện cho số lượng hành khách, ở đây chúng ta thấy rằng có hơn 550 hành khách đã không sống sót và 340 hành khách sống sót. Thử tính toán ra tỉ lệ phần trăm như thế nào nhé.
prop.table(table(titanic$Survived))
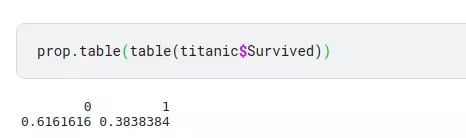 Hình: tỉ lệ người sống sót
Hình: tỉ lệ người sống sót
Vậy thì tỉ lệ người sống sót theo giới tính thì như thế nào nhỉ? Nam hay nữ có tỉ lệ cao hơn?
ggplot(data=titanic,aes(x=Sex,fill=Survived))+geom_bar()
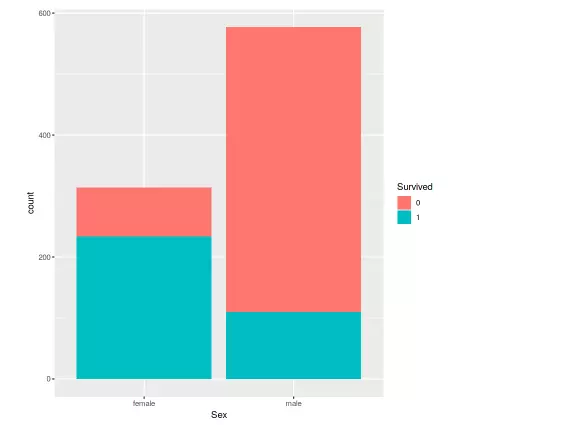 Hình : tỉ lệ người sống sót theo giới tính
Hình : tỉ lệ người sống sót theo giới tính
Ở đây chúng ta có thể thấy rằng tỉ lệ sống sót ở nữ giới cao hơn nam giới.Tỷ lệ sống sót ở phụ nữ khoảng 75%, trong khi nam giới ít hơn 20%.
Mọi người mua vé thường biết có các khoang riêng dành cho từng phân khúc khách hàng vậy thì trên chuyến tàu titanic này tỉ lệ người sống sót giữa 3 hạng vé này có khác nhau như giá tiền mà mỗi khách hàng ở mỗi phân khúc phải trả không nhờ? 
ggplot(data=titanic,aes(x=Pclass,fill=Survived))+geom_bar()
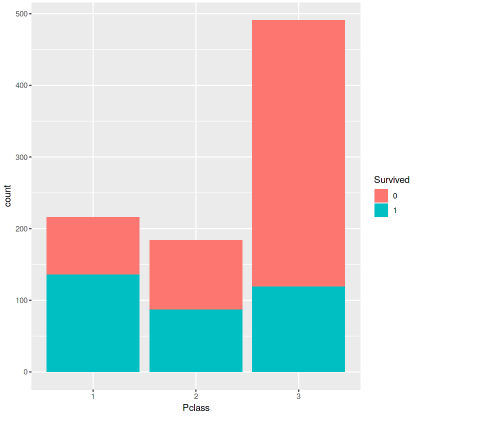 Hình : tỉ lệ sống sót theo hạng vé
Hình : tỉ lệ sống sót theo hạng vé
WOw nhìn vào hình trên thì đúng là có sự khác biệt này quả thật khách hàng hạng nhất có tỉ lệ sống sót là 60%, hạng 2 khoảng 45-50% và thấp nhất là hạng 3 ít hơn 25 %.
Tiếp theo chúng ta thử xem xem tỉ lệ sống sót theo giới tính trên mỗi hạng vé nha.
ggplot(data = titanic,aes(x=Sex,fill=Survived))+geom_bar(position="fill")+facet_wrap(~Pclass)
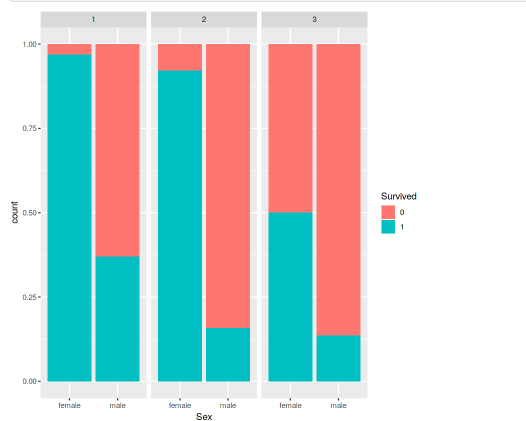 Hình: tỉ lệ sống sót theo giới tính trên mỗi hạng vé.
Hình: tỉ lệ sống sót theo giới tính trên mỗi hạng vé.
Như ở trên chúng ta cũng thấy rằng nữ giới có tỉ lệ sống sót cao hơn nam giới thì tương tự ở đây cũng vậy. Bên cạnh đó, ở hình trên chúng ta có thể thấy rẳng tỉ lệ sống sót của nữ giới ở khoang hạng nhất và 2 có tỉ lệ sống sót cực cao (trên 90%), còn của nam giới ở hạng 1 khoảng 37% và hạng 2 khoảng 16%. Còn ở hạng 3 thì tỉ lệ sống sót của nữ giới khoảng 50% nam giới nhỏ hơn 15%.
Còn tỉ lệ sống sót theo tuổi thì như thế nào nhỉ?
ggplot(data = titanic[!(is.na(titanic$Age)),],aes(x=Age,fill=Survived))+geom_histogram(binwidth =3)
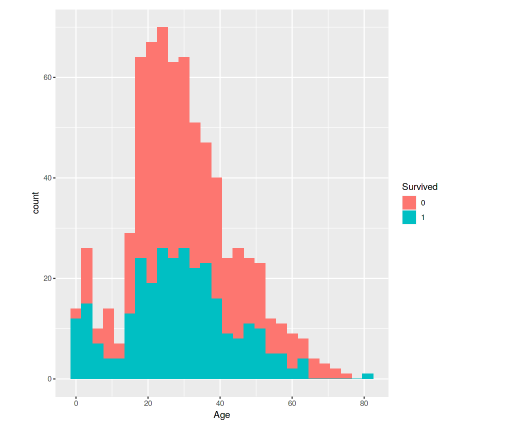 Hình: tỉ lệ sống sót theo tuổi
Hình: tỉ lệ sống sót theo tuổi
Nhìn vào biểu đồ thì chúng ta có thể nhận thấy rằng trẻ < 10 tuổi có tỉ lệ sống sót cao, còn với những người sau 45 tuổi tỉ lệ sống sót giảm hơn rất nhiều.
Kết Luận
Ở trên mình đang phân tích và visualize những cái cơ bản để làm quen với R. mình thấy R cũng khá là thú vị và hơi giống python tuy nhiên vẫn chưa quen với cách viết lắm nên còn lúng túng. Hi vọng mình sẽ viết được nhiều thứ hay ho hơn về R ở những bài viết tiếp theo. Cảm ơn mọi người đã đọc bài viết của mình, nếu hữu ích nhớ Upvoted cho mình nhé.
Reference
https://www.kaggle.com/c/titanic/data
https://towardsdatascience.com/data-analysis-and-visualisations-using-r-955a7e90f7dd