Trong thời gian gần đây, việc phát triển của các mô hình ngôn ngữ lớn (LLMs) đang phát triển chóng mặt, từ những open source model đến những close source model từ các ông lớn trong ngành. Và có lẽ những người được hưởng lợi khá lớn từ sự cạnh tranh này là những người như chúng ta, và những phương án tối ưu dần được thiết kế ra, từ những phương án tối ưu fine tuning về mặt weight, prompt đến những kỹ thuật bổ sung ngữ cảnh thông tin, nổi bật là RAG. Nhưng hiện tại là RAG đang được thiết kế một cách cố định, và sẽ ra sao nếu chúng ta có thể tạo ra các mô hình và kiến trúc RAG có thể huấn luyện được, hay nói ngắn gọn thì các quy trình trong RAG có thể tùy chỉnh như việc tinh chỉnh một mô hình LLMs. Và RAG 2.0 có được đề xuất, và tình cờ mình đọc tìm được một bài viết về kiến trúc này. Chúng ta sẽ đi sâu hơn về sự khác biệt của kiến trúc này.
Thật ra là kiến trúc này được giới thiệu bởi Contextual AI Team vào giữa tháng 3, nhưng hiện tại mình mới thấy có bài về cái này, mọi người có thể tìm đọc thêm ở đây.
Có khá nhiều bài viêt về RAG rồi nên là mọi người có tìm đọc thêm trước khi vào bài viết này để có cái nhìn tổng quan trước khi vào bài.
Những phương diện mà RAG 2.0 so sánh và phát triển
Contextual AI Team có giới thiệu về Contextual Language Model, và họ có đề cập đến một số tiêu chí để so sánh với những kiến trúc RAG tĩnh:
- Open domain question-answering: Họ sử dụng các bộ dữ liệu Natural Questions (NQ) và TriviaQA để kiểm tra khả năng truy xuất của các mô hình, liệu chúng có lấy được các thông tin liên quan, từ đó có thể trả lời một cách chính xác hay không? Ngoài ra họ cũng đánh giá yếu tố này thông qua bộ dữ liệu HotpotQA (HPQA).
- Faithfulness: Đối với yếu tố này thì họ đánh giá khả năng bảo toàn thông tin qua các tác vụ hay thành phần trong kiến trúc, tránh việc tạo ra thông tin sai lệch hoặc những thông tin giả. Họ đánh giá dựa trên HaluEvalQA và TrurhfulQA.
- Freshness: Đánh giá khả năng cập nhật kiến mới thông qua việc tìm kiếm các thông tin đó trên web với benchmark là FreshQA.
-
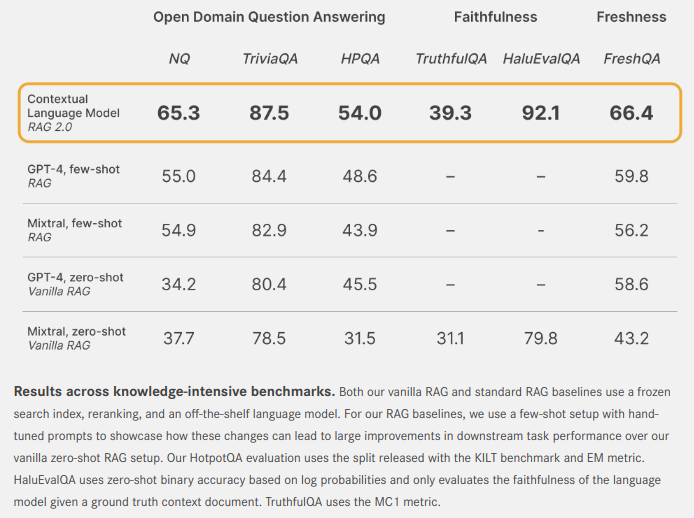
Và từ đó họ thấy rằng CLMs có sự cải thiện về mặt hiệu suất đáng kể so với các hệ thống RAG tĩnh truyền thống, dù dựa trên những open source như Mixtral hay là những close source như GPT 4.
Vậy hãy xem họ làm thế nào nhé?
Sử dụng một thuật toán truy xuất tốt hơn
Chũng ta sẽ điểm qua một số thuật toán truy xuất thường được đề cập và sử dụng: TF-IDF, BM25, Dense Retrieval, …
Hay ngoài ra có một số kỹ thuật liên quan khác chúng ta có thể chú ý đến như là ColBERT, với ý tưởng nổi bật là cách tiếp cận khá đặc biệt: late interaction machanism (cơ chế tương tác trễ ?). Thay vì so sánh trực tiếp toàn bộ tài liệu và câu truy vấn, ColBERT mã hóa cá thành phần một cách riêng biệt cả trong tài liệu và câu truy vấn. Sau đó dùng từng phần của câu truy vấn tương tác với các thành phần của bộ dữ liệu, đơn giản hóa là nó sẽ tính toán theo từng phần một thay vì toàn bộ câu truy vấn rồi tổng hợp lại.
Không dừng lại ở đó, có một số thuật toán truy xuất khác cũng được giới thiệu
SPLADE(Sparse LAttentional DEcoder): Sự kết hợp giữa sparse and dense representations và query expansion.
DRAGON (Generalize dense retriever via progressive data augmentation)
Thuật toán này hướng đến việc tăng hiệu suất truy vấn bằng cách sử dụng progressive data augmentation. Thuật toán này liên tục cập nhật và điều chỉnh các truy vấn dựa trên ngữ cảnh thay đổi của cuộc trò chuyện, đảm bảo rằng thông tin truy xuất luôn phù hợp và chi tiết.
Các bước chính trong hoạt động của DRAGON:
- Truy vấn ban đầu: * Khi nhận được một truy vấn từ người dùng, DRAGON sẽ nhận diện chủ đề và tạo ra một truy vấn mục tiêu để thu thập thông tin liên quan đến chủ đề đó.
- ** Truy xuất ban đầu**: * DRAGON truy xuất các tài liệu từ cơ sở dữ liệu của mình chứa thông tin liên quan đến truy vấn. Ví dụ, nếu truy vấn ban đầu là "Làm thế nào để chăm sóc cây nhện?", DRAGON sẽ truy xuất các tài liệu về yêu cầu ánh sáng, lịch trình tưới nước, và phân bón phù hợp cho cây nhện.
- Phản hồi ban đầu: * Dựa trên các tài liệu đã truy xuất, DRAGON sẽ tạo ra một phản hồi chi tiết và cụ thể cho người dùng.
- Cập nhật từ người dùng: * Khi cuộc trò chuyện tiếp tục, người dùng có thể đặt thêm các câu hỏi hoặc cung cấp thêm thông tin. DRAGON sẽ nhận diện sự thay đổi này và điều chỉnh truy vấn của mình.
- Thích nghi và truy xuất động: * DRAGON tinh chỉnh truy vấn ban đầu để tập trung vào vấn đề mới mà người dùng quan tâm. Ví dụ, nếu người dùng hỏi "Điều gì xảy ra nếu lá cây chuyển sang màu nâu?", DRAGON sẽ tập trung vào việc truy xuất thông tin về nguyên nhân lá cây nhện chuyển sang màu nâu.
- Cung cấp kiến thức cập nhật: * Bằng cách sử dụng thông tin mới được truy xuất, DRAGON điều chỉnh phản hồi của mình để phù hợp với ngữ cảnh và yêu cầu mới của người dùng. Điều này đảm bảo rằng thông tin cung cấp luôn chính xác và hữu ích.
Hybrid Search:
<image6>
Hiểu đơn giản là sự kết hợp giữa Dense và Spaese search.
Nhưng mà nhìn chung thì chúng vẫn cố định.
Contextualizing the Retriever for the Generator
RePlug
Đây là một trong những bài báo rất thú vị trong lĩnh vực truy xuất thông tin có tên là RePlug. Đối với một truy vấn nhất định, chúng ta truy xuất top-K tài liệu, và sau khi thực hiện bình thường hóa (tính toán xác suất của chúng), chúng ta có được một phân phối, và chúng ta đưa từng tài liệu riêng biệt vào bộ tạo sinh cùng với truy vấn. Sau đó, chúng ta xem xét độ khó (perplexity) của câu trả lời chính xác cho mô hình ngôn ngữ. Lúc này, chúng ta có hai phân phối xác suất, trên đó chúng ta tính toán độ mất mát KL Divergence, sao cho KL divergence được tối thiểu hóa dẫn đến tài liệu truy xuất có độ khó thấp nhất trên câu trả lời đúng.
À thì trên là phần dịch nguyên từ bên baì gốc về RePlug sang, còn chi tiết hơn thì mình chưa có thời gian đọc, nhưng khá là thú vị nên mình sẽ trình bày ở một ngày không xa :3.
Tổng kết phần một
Một kiến trúc RAG sẽ được cải tiến và thêm thắt rất nhiều trong những bài toán thực tế. Bên trên chỉ là một số cải tiến khá là riêng lẻ so với pipeline chung, cụ thể là về vấn đề truy xuất. Ở bài sau chúng ta sẽ đề cập thêm một số phần ý tưởng về việc cải tiến theo từng bộ phận nói riêng và cả pipeline nói chung.
Reference
https://contextual.ai/introducing-rag2/
https://medium.com/aiguys/rag-2-0-retrieval-augmented-language-models-3762f3047256
https://arxiv.org/pdf/2004.12832
https://arxiv.org/pdf/2302.07452