
Hệ thống gợi ý (Recommender System) là 1 nhánh con của hệ thống lọc thông tin (Infomation filtering system), nhằm tìm cách dự đoán việc đánh giá (rating) của người dùng (user) sẽ đưa ra cho 1 sản phẩm (item). Chúng chủ yếu được dùng trong các ứng dụng thương mại điện tử.
Ví dụ như: Giới thiệu các sản phẩm trên Amazon, các bài hát trên Spotify, các bộ phim trên Netflix hay các bài viết trên Medium, ...
Thực chất, vấn đề của hệ gợi ý là xác định ánh xạ (u, i) -> R, trong đó u là biểu diễn cho 1 người dùng, i biểu diễn cho 1 sản phẩm và R là đánh giá của u lên i. Sau đó, các đánh giá của người dùng u lên tất cả các sản phẩm i tương ứng sẽ được sắp xếp, và lấy N sản phẩm có đánh giá cao nhất để đưa ra gợi ý cho người dùng u.
Khái niệm 'đánh giá' ở đây là khá trừu tượng, có thể được đo lường bằng hành động của người dùng như mua sản phẩm, click chuột vào sản phẩm, hoặc click vào "không hiển thị lại", ...
1. Ranking vs Recommender
Có nhiều người vẫn hay lầm tưởng hệ thống xếp hạng (Ranking) và hệ thống gợi ý (Recommender), nhưng nó là 1 bài toán khác biệt nhau:
- Hệ thống xếp hạng dựa trên tất cả các sản phẩm mà người dùng cung cấp để đưa ra truy vấn tìm kiếm, người dùng biết họ đang tìm kiếm sản phẩm nào. Hệ thống gợi ý không có bất kỳ 1 input rõ ràng nào từ người dùng, nhằm mục đích khám phá những sản phẩm mà họ chưa thấy bao giờ.
- Hệ thống xếp hạng thường đặt các sản phẩm có liên quan gần đầu danh sách hiển thị trong khi hệ gợi ý lại đôi khi cố gắng không chuyên biệt hóa quá mức.
- Hệ gợi ý nhấn mạnh hết mức vào việc cá nhân hóa
2. Các hệ gợi ý
Hệ gợi ý thường được phân thành các loại sau:
- Lọc dựa trên nội dung (Content-base filtering)
- Lọc cộng tác (Collaborative filtering)
- Phương pháp lai ghép (Hybrid Method)
Tùy thuộc vào việc hệ thống có học từ dữ liệu hay không, lại chia thành các loại sau:
- Dựa trên bộ nhớ
- Dựa trên mô hình
2.1. Lọc dựa trên nội dung (Content-base filtering)
Phương pháp lọc dựa trên nội dung dựa vào tổng số các item (đối với user) và profile về đánh giá của người dùng. Nó phù hợp nhất với dữ liệu đã biết về item và cách người dùng đã tương tác trước đây với hệ gợi ý, nhưng thiếu thông tin người dùng.
Thực chất, việc dự đoán đánh giá của user u lên item i chính là dựa trên các đánh giá của người dùng đó cho các item khác trước đây.
Giả sử Wi là vector profile cho item i và Wu là vector profile cho người dùng u. 1 vector profile được hiểu là 1 bản tóm tắt về các đánh giá của người dùng đối với tất cả các mục trước đây.
2.1.1. Ví dụ về dựa trên bộ nhớ (Memory base example)
Ta dùng hệ thống xếp hạng làm ví dụ, 1 cách để lập mô hình vector profile người dùng là thông qua mức trung bình có trọng số xếp hạng, tức là:
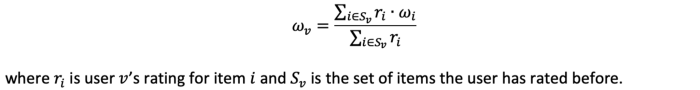
Sau đó, đánh giá (u, i) trở thành:
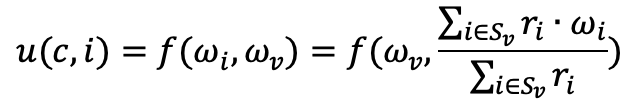
Hàm tiện ích thường được thể hiện trong tài liệu truy xuất thông tin bằng thước đo độ tương tự cosin:
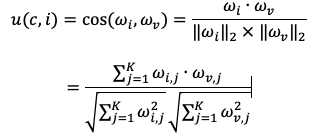
Ở đây, K là thứ nguyên của item và vector profile người dùng.
2.1.2. Ví dụ mô hình (Model base example)
Phân loại Naive Bayes đã được sử dụng rộng rãi, điển hình cho phương pháp lọc dựa trên nội dung cho hệ gợi ý.
Ta dùng hệ thống gợi ý video làm ví dụ, và đánh giá của người dùng được đo bằng cách nhấp vào video gợi ý hay không. Chính xác hơn, vấn đề gợi ý ở đây là ước tính xác suất nhấp chuột vào 1 video:

Theo định lý Bayes:
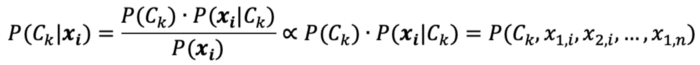
Theo kỹ thuật chain rule:
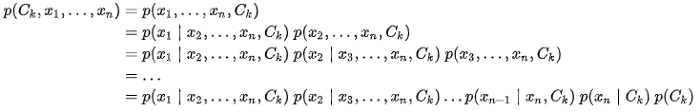
Với sự hỗ trợ của giả định độc lập Naive, ta được:
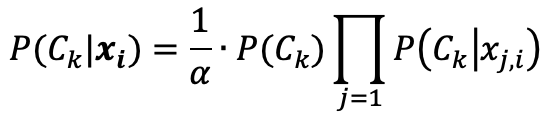
Ở đây, alpha là 1 tham số chuẩn hóa để đảm bảo xác suất kết quả nằm trong đoạn [0, 1]. Tuy nhiên, điều này là không cần thiết đối với 1 số hệ thống gợi ý, nơi mà ta chỉ quan tâm đến thứ hạng tương đối giữa các item.
2.1.3. Hạn chế
- Dữ liệu thưa thớt, dựa trên bộ nhớ hay các mô hình thì cả 2 đều tận dụng tương tác lịch sử của người dùng với hệ gợi ý. Vì vậy, đối với những người mới bắt đầu sử dụng hệ thống (Cold Start) thì hệ gợi ý có thể hoạt động chưa chính xác.
- Với trường hợp người dùng mới (Cold Start) thì không hoạt động được.
Lọc cộng tác khắc phục các hạn chế trên bằng các tận dụng thông tin của nhiều người dùng.
2.2. Lọc cộng tác (Collaborative filtering)
Lọc cộng tác phù hợp với các kiểu dữ liệu đã biết về người dùng nhưng thiếu dữ liệu cho các item hoặc khó thực hiện việc trích xuất tính năng cho các item quan tâm.
Không giống như lọc dựa trên nội dung, lọc cộng tác cố gắng dự đoán đánh giá của người dùng u cho 1 item i dựa trên các đánh giá của người dùng khác đối với item đó.
2.2.1. Ví dụ dựa trên bộ nhớ (Memory base example)
Sử dụng lại ví dụ về hệ thống xếp hạng, các phương pháp dựa trên bộ nhớ về cơ bản là phương pháp dự đoán xếp hạng của người dùng u cho item i dựa trên việc thu thập xếp hạng cho sản phẩm đó từ những người dùng khác:
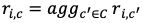
Trong đó, C là tập người dùng không bao gồm người dùng c quan tâm
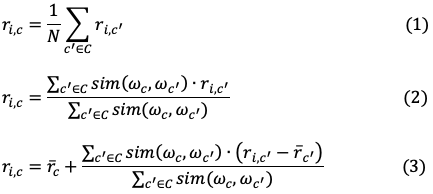
(1) chỉ đơn giản là xếp hạng trung bình cho sản phẩm từ tất cả các user khác. (2) cố gắng cân nhắc xếp hạng của người dùng khác bằng mức độ tương đồng với người dùng c. Một cách để đo lường hàm tương đồng dữa vector đặc điểm của 2 người dùng. (3) là giải quyết vấn đề người dùng có thể có thang điểm xếp hạng khác nhau.
2.2.2. Ví dụ về mô hình (Model base example)
Lọc cộng tác dựa trên dữ liệu lịch sử (từ những người dùng khác) để tìm hiểu 1 mô hình. Đối với ví dụ xếp hạng, 1 mô hình là hồi quy tuyến tính đối với profile người dùng là các tính năng và đánh giá cho từng item riêng biệt.
2.2.3. Hạn chế
- Dữ liệu thưa thớt, đối với các item ít phổ biến hay ít đánh giá hơn, lọc cộng tác khó đưa ra kết quả chính xác.
- Đối với người dùng mới, cũng không thể áp dụng phương pháp này.
2.3. Phương pháp lai ghép (Hybrid Method)
Do cả 2 phương pháp trên đều các các hạn chế riêng, đồng thời phương pháp này có thể giải quyết được hạn chế của phương pháp còn lại, vì vậy có thể lai ghép chúng với nhau.
Các cách kết hợp:
- Triển khai 2 phương pháp 1 cách riêng biệt và kết hợp các dự đoán của chúng. Đây thực chất là 1 mô hình tổng hợp.
- Kết hợp các đặc điểm dựa trên nội dung và lọc cộng tác. Cách làm là tận dụng profile của người dùng để đo độ tương đồng giữa 2 người dùng, và sử dụng độ tương đồng này làm trọng số trong bước tổng hợp 2 phương pháp.
- Một mô hình nhiều người dùng và nhiều mục. Điều này là để xây dựng một mô hình có cả tính năng mục và tính năng người dùng làm đầu vào, chẳng hạn như mô hình hồi quy tuyến tính, mô hình cây, mô hình mạng nơ ron, ...
3. Mở rộng
Một số hệ gợi ý rất nhạy cảm về thời gian (New feed của facebook) hoặc phụ thuộc vào thời vụ (gợi ý điểm du lịch). Đối với các hệ gợi ý này, chúng ta cần phải xây dựng thêm mô hình chuỗi thời gian (Arima, RNN). Cũng có những hệ gợi ý mà các đề xuất có liên quan nhiều đến mục được xem gần nhất của người dùng (Youtube), trong trường hợp này, mô hình dựa trên Markov có thể phù hợp hơn.
Nguồn: TowardsDataScience