Bài viết được dịch từ nguồn
Cache
Cache là cơ chế giúp việc truy xuất dữ liệu trở nên nhanh hơn so với các data source. Cache thường được sử dụng để lưu các response hay được user request tới, ngoài ra cache còn được tận dụng để lưu kết quả của các xử lí tốn nhiều tài nguyên tính toán cũng như thời gian tính toán.
Cache sẽ lưu dữ liệu ở một nơi khác so với data source đang dùng với mục đích tăng tốc truy vấn. Cũng như load balancer, cache có thể được sử dụng ở nhiều vị trí khác nhau trong hệ thống.
Trong thiết kế hệ thống, khái niệm về cache thường được đề cập với mục đích:
- Cải thiện độ trễ của hệ thống.
- Giảm số lượng requests đến hệ thống.
Do cache thường được sử dụng để lưu các dữ liệu thường xuyên được sử dụng trong hệ thống, do đó nó giúp giảm lượng truy vấn đến DB.
Các khái niệm trong cache
Cache hit
Là khi truy vấn, ta tìm được dữ liệu cần thiết từ cache.
Cache miss
Là khi truy vấn, ta không thấy dữ liệu từ cache.
Data stale
Dữ liệu bị coi là stale nếu dữ liệu trong primary database được cập nhật mới nhất, trong khi dữ liệu trong cache thì không.
Thế nhưng bản thân việc dữ liệu bị stale không phải là một vấn để quá nghiêm trọng với hệ thống. Ta lấy ví dụ với dữ liệu số lượng viewer trên youtube, con số này không nhất thiết phải giống nhau với mọi người dùng, do đó ta có thể bỏ qua nó. Việc bỏ qua stale data problem sẽ giúp phát huy vai trò của cache.
Client side caching
Ta có thể sử dụng cache ở phía client để client không phải gửi request lên cho server, ngoài ra ta việc không gửi request lên server cũng giúp server không phải trích xuất dữ liệu từ DB.
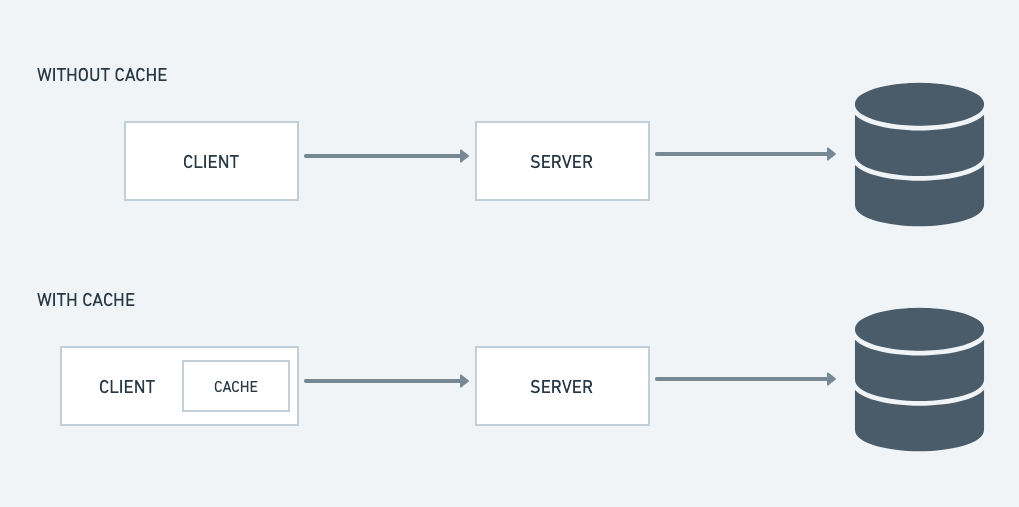
Xử lí các áp lực lên DB
Xét một ví dụ đơn giản, khi một người nổi tiếng trên facebook cập nhật thông tin cá nhân của họ, chắc chắn lượng request gửi đến DB để xem thông tin mới nhất này sẽ tạo một áp lực khá lớn lên DB, trong trường hợp tồi nhất, DB có thể crashed. Do đó để tránh trường hợp như vậy, ta có thể cache lại nhưng thông tin kiểu này để giảm áp lực lên DB.
Hãy thử tưởng tượng trường hợp ta tiến hành viết bài trên medium. Lúc này server sẽ là Medium server, client chính là browser của chúng ta, chúng ta viết bài, submit lên server medium và bài viết được lưu trong DB của Medium. Thế nhưng ta cũng có thể lưu dữ liệu ở 2 nơi: DB và cache, lúc này sẽ có một vấn đề đó là:
- Khi nào ta sẽ ghi lên DB, khi nào sẽ ghi lên cache trong trường hợp chỉnh sửa bài viết.
Nếu xử lí không khéo, sẽ dễ dẫn tới trường hợp stale data, do đó ta cần biết về kĩ thuật cache invalidation để có thể giải quyết vấn đề.
Cache Invalidation
Cache thường được sử dụng như một công cụ để tăng tốc truy vấn dữ liệu, ... Thế nhưng trong trường hợp dữ liệu giữa cache và main DB không thống nhất ta sẽ gặp phải vấn đề như đã nêu ở trên đó là stale data. Dẫn đến việc hiển thị dữ liệu ở phía người dùng và dữ liệu thật sự không có sự đồng nhất.
Do bộ nhớ của cache là hữu hạn nên để giải quyết vấn đề nêu trên, ta cần phải cập nhật dữ liệu trong cạche. Kĩ thuật này được gọi là cache invaidation.
Ta sẽ tiến hành cập nhật dữ liệu mới nhất cho cache hoặc nếu không, request sẽ được gửi tới server, server sẽ quét dữ liệu trong DB và làm tăng độ trễ cho response trả về
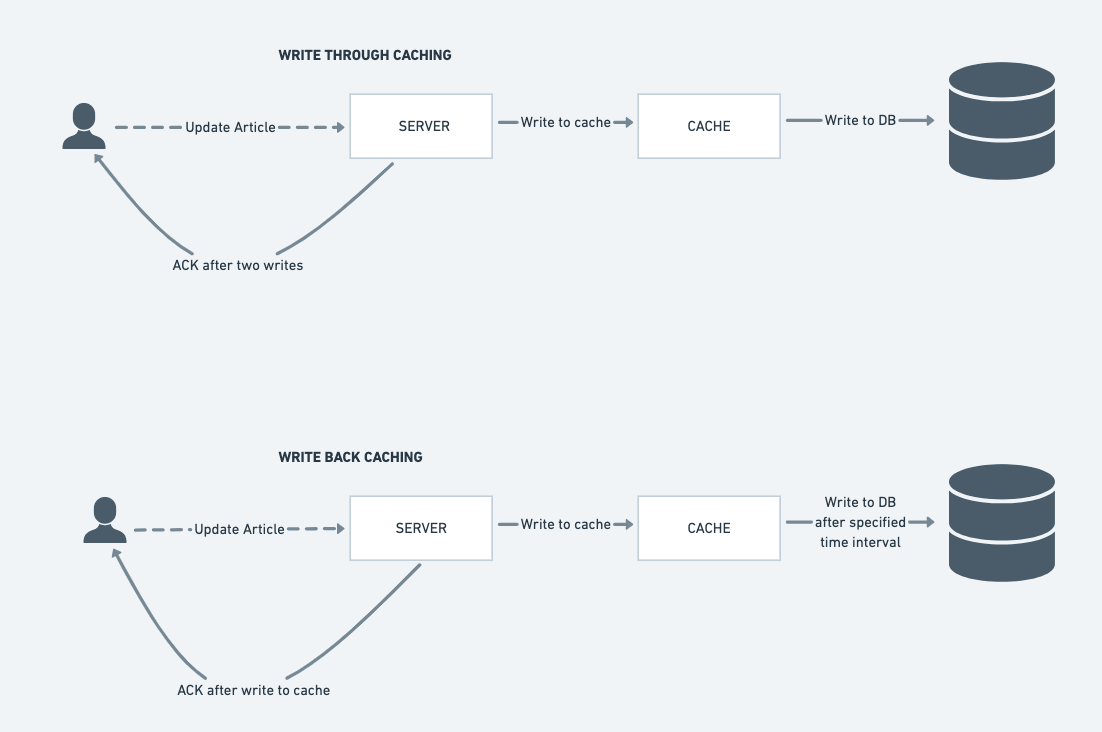
Write-through cache
Với cách làm này ta sẽ trả về response cho phía client sau khi dữ liệu được ghi lên:
- Cache
- DB
điều này sẽ giúp giảm nguy cơ bị mất dữ liệu do dữ liệu luôn được lưu ở cache và DB cũng như tính thống nhất về dữ liệu luôn được đảm bảo, thế nhưng nhược điểm của nó chính là việc ghi lên cả cache và DB sẽ làm tốn nhiều thời gian chờ của phía client.
Write-back cache
Sự khác biệt của giải pháp này là ở chỗ, sau khi ghi vào cache thì thông báo ghi dữ liệu thành công sẽ được trả về luôn cho phía client, sau một khoảng thời gian nhất định thì dữ liệu mới được ghi vào DB.
Cách làm này sẽ phù hợp với các ứng dụng "ghi nhiều" vì nó sẽ làm giảm đáng kể latency. Thế nhưng nguy cơ mất dữ liệu sẽ cao hơn nếu cache bị crash.
Cache aside
Tư tưởng chính ở đây đó là làm giảm lượng request đến DB nhiều nhất có thể. Khi cache hit, dữ liệu sẽ được gửi về từ cache, nếu cache miss thì dữ liệu sẽ được lấy ra từ DB, đưa vào cache rồi trả về cho client. Do đó dữ liệu bị cache miss lần này sẽ có sẵn luôn trong cache ở lần sau.
Cách tiếp cận này phù hợp cho các ứng dụng "đọc nhiều", dữ liệu trong hệ thống không được thường xuyên cập nhật
Thế nhưng một vấn đề của cách tiếp cận này đó là dữ liệu trong cache và trong DB có thể không thống nhất với nhau, để tránh điều này xảy ra ta cần thiết lập TTL cho dữ liệu trong cache để sau một khoảng thời gian nhất định, dữ liệu trong cache sẽ được invalidated.
Read-through cache
Hoàn toàn tương tự như cache-aside, chỉ khác một điều đó là dữ liệu giữa cache và DB luôn được đồng nhất với nhau. Cache library có trách nhiệm làm nhiệm vụ này.
Một vấn đề với cách tiếp cận này đó là ở thời điểm đầu tiên khi user request dữ liệu thì sẽ xảy ra cache-miss. Do đó trước khi trả về response cho phía user, ta cần cập nhật lại cache. Hoặc để tránh tình trạng cache-miss như trên ta có thể "dự đoán" trước những loại dữ liệu mà user sẽ request trong lần đầu để pre-load trước vào cache.
Cache eviction policies
Bộ nhớ của cache là hữu hạn và cũng không được "lớn" như DB, hơn thế nữa việc stale data tồn đọng trong cache là chuyện bình thường, do đó để tránh việc cache bị "đầy", ta cần có một cơ chế để "dọn dẹp" các dữ liệu "thừa" có trong cache.
Dưới đây là một vài cơ chế thường được sử dụng để dọn dẹp dữ liệu thừa trong cache
1. First In First Out (FIFO): tương tự như queue, những dữ liệu được truy xuất đầu tiên sẽ bị dọn dẹp đi đầu tiên (mà không quan tâm đến tần suất dữ liệu được truy xuất). 2. Last In First Out (LIFO): tương tự như stack, dữ liệu được thêm mới nhất sẽ bị dọn dẹp đi đầu tiên (mà không quan tâm đến tần suất dữ liệu được truy xuất). 3. Least Recently Used (LRU): Ở đây ta sẽ loại bỏ đi những dữ liệu không được sử dụng gần đây (những dữ liệu loại này được coi như sẽ hiếm được truy xuất kể cả sau này). 4. Least Frequently Used (LFU): Ở đây ta cần phải đếm tần xuất dữ liệu được truy xuất, những dữ liệu với tần suất truy xuất thấp sẽ bị loại bỏ đi đầu tiên. 5. Random selection: Lựa chọn và loại bỏ đi dữ liệu trong cache một cách ngẫu nhiên, cơ chế này sẽ được sử dụng khi cache đạt đến ngưỡng "đầy".
Tuỳ vào yêu cầu của hệ thống, ta sẽ có những lựa chọn phù hợp cho cơ chế loại bỏ đi những dữ liệu thừa có tron cache.
Tổng kết
Caching là chìa khoá giúp đảm bảo hiệu năng của bất kì hệ thống nào. Nó đảm bảo độ trễ thấp cũng như thông lượng cao cho hệ thống.
Bản thân cache cũng là một bản sao dữ liệu của DB. Việc truy xuất vào cache sẽ nhanh hơn so với việc truy xuất vào DB. Cache có thể được đặt ở bất kì đâu trong hệ thống, thế nhưng ta nên đặt nó ở gần phía front end hơn nhằm giúp client có thể nhận về dữ liệu nhanh nhất có thể.
Với những dữ liệu "tĩnh", cache sẽ phát huy sức mạnh rất tốt, thế nhưng với dữ liệu "hay thay đổi" thì việc triển khai cache lại là một thử thách không hề đơn giản.