Chuẩn bị dữ liệu
Chúng ta sẽ sử dụng dữ liệu Vietnam War Bombing Operations. Bộ dữ liệu này bao gồm các phi vụ của Không lực Hoa Kỳ và đồng minh trong Chiến tranh Việt Nam từ năm 1965 tới năm 1975.
!kaggle datasets download -d usaf/vietnam-war-bombing-operations

Ta thấy bộ dữ liệu này có 4 files.
THOR_Vietnam_Aircraft_Glossary.csv
THOR_Vietnam_Bombing_Operations.csv
THOR_Vietnam_Weapons_Glossary.csv
thor_data_dictionary_2016.pdf
Import một vài package cần thiết
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set() import warnings
warnings.filterwarings('ignore')
Bắt đầu nào
Chúng ta sẽ load dữ liệu, và xem thử vài dòng đầu của chúng.
bo_df = pd.read_csv('THOR_Vietnam_Bombing_Operations.csv')
bo_df.head()
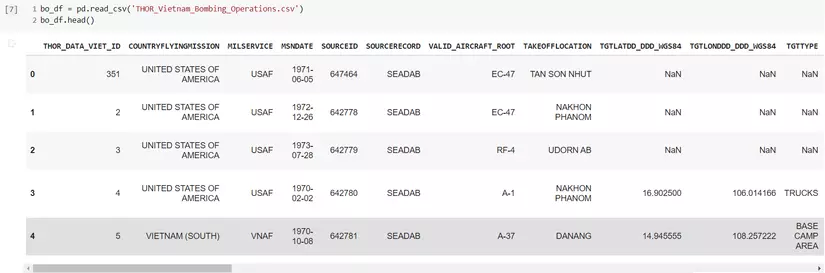
aircraft_df = pd.read_csv('THOR_Vietnam_Aircraft_Glossary.csv', encoding='ISO-8859-1')
aircraft_df.head()

weapon_df = pd.read_csv('THOR_Vietnam_Weapons_Glossary.csv', encoding='ISO-8859-1')
weapon_df.head()
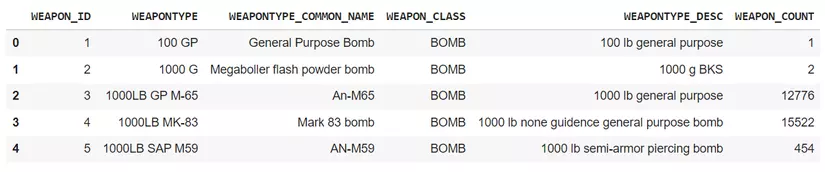
Có thể thấy, thông tin chính của các phi vụ nằm ở file 'THOR_Vietnam_Bombing_Operations.csv', còn 'THOR_Vietnam_Aircraft_Glossary.csv', 'THOR_Vietnam_Weapons_Glossary.csv' chứa thông tin về các máy bay và các loại vũ khí trong các phi vụ. Còn vì sao trừ 'THOR_Vietnam_Bombing_Operations.csv', 2 file còn lại đều phải encoding thì mình sẽ nói tới trong bài viết khác nha.
Do đó ta sẽ phân tích từ file 'THOR_Vietnam_Bombing_Operations.csv'.
Phân tích THOR_Vietnam_Bombing_Operations.csv
Hmm, để xem có bao nhiêu điểm dữ liệu nào:
n_rows, n_cols = bo_df.shape
print('Number of Row:', n_rows)
print('Number of Column:', n_cols)

Hơn 4.6 triệu quý zị ạ. Chỉ trong 10 năm từ 1965 tới 1975 có tới hơn 4.6 triệu lần xuất kích của Không lực phía Hoa Kỳ và đồng minh, tính nhanh thì mỗi ngày có tới 1260 lần.
Cùng xem dataset này có bao nhiêu missing values nào.
pct_mss_values = bo_df.isna().sum() / len(bo_df) * 100
pct_mss_values = pct_mss_values.sort_values(ascending=False)
pct_mss_values
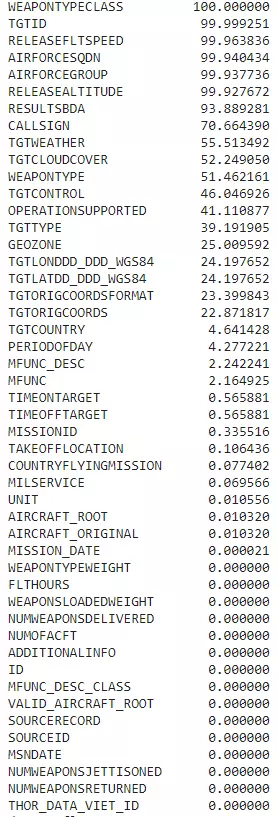
Wào, có vài cột mất rất nhiều dữ liệu, nhưng phần lớn các cột còn lại đều ổn, ta sẽ xử lý chúng sau khi xem 2 datasets còn lại.
Chúng ta cùng xem qua kiểu dữ liệu của các cột.
bo_df.info()

Thấy rằng cột 'MSNDATE' (Mission Date) đang ở kiểu object, ta cần chuyển nó sang datetime để có thể trích xuất tính năng từ nó. Thường thì mình sẽ copy ra một dataframe để xử lý trên đó, tránh động vào dataframe gốc, nhưng vì dataset này to quá, nên mình sẽ tạo ra một cột mới để xử lý trên đó, rồi sau đó xoá cột cũ đi.
bo_df['MISSION_DATE'] = pd.to_datetime(bo_df['MSNDATE'])
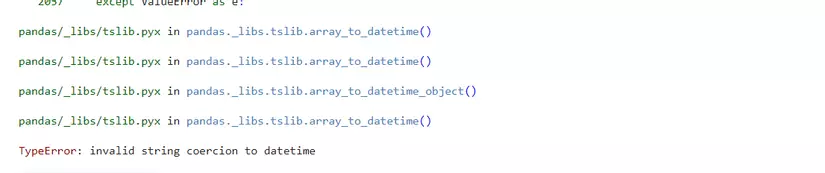
Bùm, có lỗi, có thể do một vài giá trị nào đó không đúng theo định dạng ngày tháng, nên ta sẽ thêm tham số errors='coerce' vào to_datetime()
bo_df['MISSION_DATE'] = pd.to_datetime(bo_df['MSNDATE'], errors='coerce')
Bây giờ quay lại các giá trị vừa gây ra lỗi lúc nãy, xem có thể xử lý chúng hay không.
bo_df[bo_df['MISSION_DATE'].isna()]['MSNDATE']
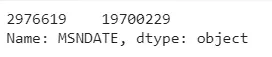 Có thể thấy đó là giá trị tại hàng 2976619, với giá trị là '19700229'. Có thể hiểu rằng đó là 1970-02-29, về lý thuyết có thể đưa nó về kiểu datetime được, nhưng khi search thì năm 1970 lại không phải năm nhuận, nên rõ ràng là có gì đó sai sai ở đây, nên tốt nhất là ta drop dòng này.
Tiện thể drop luôn cả cột 'MSNDATE'.
Có thể thấy đó là giá trị tại hàng 2976619, với giá trị là '19700229'. Có thể hiểu rằng đó là 1970-02-29, về lý thuyết có thể đưa nó về kiểu datetime được, nhưng khi search thì năm 1970 lại không phải năm nhuận, nên rõ ràng là có gì đó sai sai ở đây, nên tốt nhất là ta drop dòng này.
Tiện thể drop luôn cả cột 'MSNDATE'.
bo_df.drop(2976619, inplace=True)
bo_df.drop(['MSNDATE'], axis=1, inplace=True)
Trích xuất tháng và năm từ cột 'MISSION_DATE'
bo_df['MONTH'] = bo_df['MISSION_DATE'].dt.month
bo_df['YEAR'] = bo_df['MISSION_DATE'].dt.year
Vậy là cũng đã được sơ sơ rồi. Giờ chúng ta sẽ visualize bằng thư viện matplotlib và seaborn.
Ta sẽ xem có phía Hoa Kỳ có những thành viên nào.
plt.figure(figsize=(12, 8))
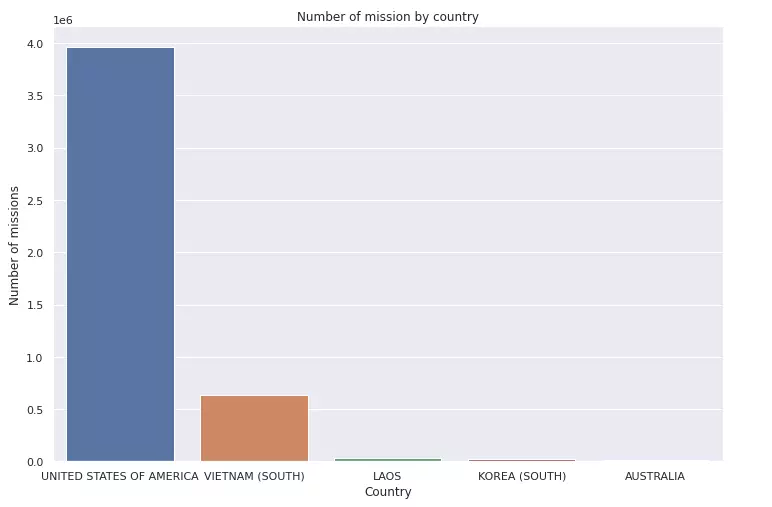
sns.countplot(x='COUNTRYFLYINGMISSION', data=bo_df)
plt.title('Number of mission by country')
plt.xlabel('Country')
plt.ylabel('Number of missions')
plt.show()
def n_missions(country): count = len(bo_df[bo_df['COUNTRYFLYINGMISSION'] == country]) pct = count / len(bo_df) * 100 print(f'\033[1m{country}\033[0m - \033[1m{pct:.2f} %\033[0m') countries = ['UNITED STATES OF AMERICA', 'VIETNAM (SOUTH)', 'LAOS', 'KOREA (SOUTH)', 'AUSTRALIA']
for country in countries: n_missions(country)

Có thể thấy nhà tài trợ kim cương hoạt động nhiều nhất với 84.83% tổng số lần xuất kích thuộc về Hoa Kỳ.
Chúng ta sẽ tiếp tục xem số lần xuất kích qua từng năm.
def msn_of_each_country(country, color): count = [] for year in bo_df['YEAR'].unique(): count.append(len(bo_df[(bo_df['COUNTRYFLYINGMISSION'] == country) & (bo_df['YEAR'] == year)])) sns.lineplot(x=bo_df['YEAR'].unique(), y=count, color=color, label=country) plt.figure(figsize=(12, 8))
colors = ['blue', 'yellow', 'purple', 'red', 'green']
for country, color in zip(countries, colors): msn_of_each_country(country, color)
plt.title('Number of missions by country per year')
plt.xlabel('Year')
plt.ylabel('Number of missions')
plt.legend()
plt.show()
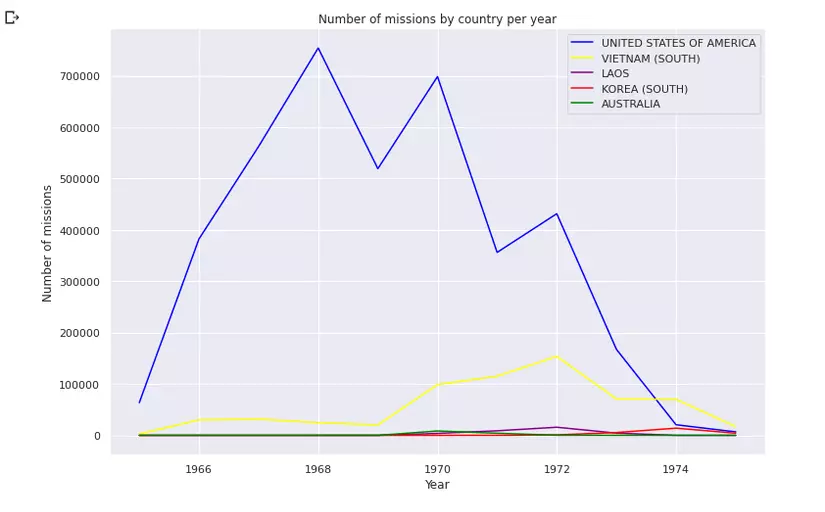
Từ đây ta có thể thấy Hoa Kỳ giảm dần hoạt động theo từng năm từ năm 1968, chuyển dần sang cho Không lực Việt Nam Cộng hoà đảm nhiệm. Phải tới sau năm 1972 tức là sau chiến dịch Linebacker II, cũng là chiến thắng Điện Biên Phủ trên không, Hoa Kỳ ký hiệp định Paris 1973, rút khỏi Việt Nam, các hoạt động quân sự mới bắt đầu giảm mạnh.
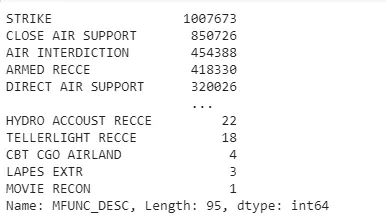
Theo tên của dataset là bombing_operations, nhưng không phải hoạt động nào của Không lực phía Hoa Kỳ cũng là ném bóm, bắn phá, chúng ta hãy cùng xem cột 'MFUNC_DESC' .
unique_mfunc = bo_df['MFUNC_DESC'].value_counts()
sns.barplot(x=unique_mfunc.index, y=unique_mfunc.values)
Úi, có lẽ chỉ cần xem 10 giá trị lớn nhất là đủ.
plt.figure(figsize=(12, 8))
sns.barplot(x=unique_mfunc.index[:10], y=unique_mfunc.values[:10])
plt.title('Number of missions by mission func')
plt.xlabel('Mission Func')
plt.ylabel('Number of missions')
plt.xticks(rotation=90)
plt.show()
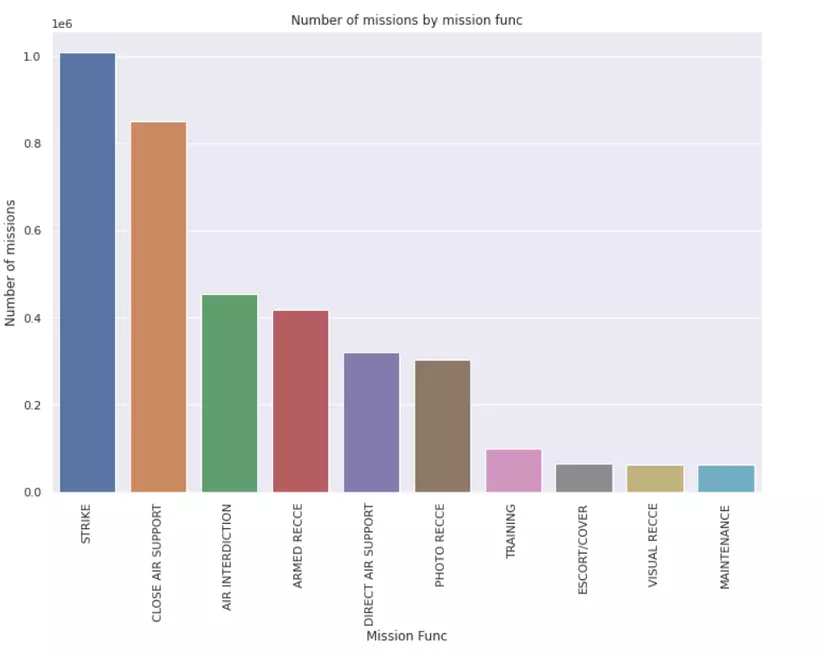
Ta có thể thấy ngoài Strike ra, còn có các hoạt động hỗ trợ không quân khác như CLOSE AIR SUPPORT, AIR INTERDICTION, TRAINING, vân vân...
Đợi một chút đã, mình cảm thấy có gì đó không ổn khi kiểm tra lại cột 'MISSION_DATE'.
bo_df['MISSION_DATE'].max()
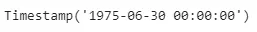
Giải phóng vào 30-4-1975, sao trong dataset lại tới ngày 30-6-1975 ?? Chẳng nhẽ vẫn còn đánh nhau tới tận 2 tháng sau ư? Chúng ta sẽ cùng tìm hiểu tiếp ở phần sau nha 
Kết
Cảm ơn mọi người đã đọc tới đây. Bài này được lấy cảm hứng từ bài viết của chị @Honganh. Đây cũng là bài đầu tiên của em, do tự học nên có thể dẫn tới bị overfit, rất mong các anh chị nhận xét, góp ý, và đặc biệt chỉ ra các lỗi sai để em khắc phục.
Một lần nữa, em xin trân thành cảm ơn  .
.
Tài liệu tham khảo
https://viblo.asia/p/lam-sao-de-trich-xuat-tinh-nang-tu-dates-bang-python-RnB5prR6ZPG