Nếu bạn là một là lập trình viên Back End - Một trong những điều mà bạn quan tâm nhất đó là PERFORMENT. Index là một trong những cách để tăng hiệu năng hiệu quả nhất trong SQL. Cùng mình tìm hiểu về Index trong SQL nhé !
1. Đặt vấn đề
Ví dụ: Mình có 1 table person với 1 triệu record có cấu trúc như sau:

Giả sử mình có 1 câu truy vấn:

Và đây là thời gian để đếm tất cả person có first_name là Emma

Ồ! Bạn tưởng tượng xem một trang web có bao nhiêu câu truy vấn mà mỗi truy vấn tốn vài dây như thế này liệu User nào còn muốn sử dụng không?
Đừng hoảng vội, vỏ quýt dày có móng tay nhọn nhé  Vì vậy Index trong SQL được ra đời để xử lý vấn đề này. Mình quay trở lại ví dụ, và sử dụng Index nhé:
Vì vậy Index trong SQL được ra đời để xử lý vấn đề này. Mình quay trở lại ví dụ, và sử dụng Index nhé:
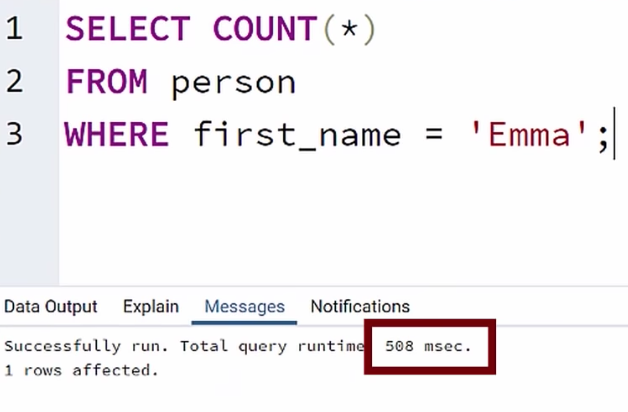
Bạn để ý xem, thời gian thực hiện khi dùng Index giảm 8 lần so với không dùng. Đã thấy sự lợi hại chưa ?
2. Khái niệm
Index trong SQL là bảng tra cứu đặc biệt mà công cụ tìm kiếm cơ sở dữ liệu có thể sử dụng để tăng nhanh thời gian và hiệu suất truy xuất dữ liệu.
Hiểu một cách đơn giản hơn, một Index là một con trỏ chỉ tới từng giá trị xuất hiện trong bảng/cột được đánh chỉ mục. Index trong Database có ý nghĩa tương tự như các mục trong xuất hiện trong mục lục của một cuốn sách. Thay vì bạn phải lật từng trang sách để tim thông tin nào đó, bạn chỉ cần lật mục lục và tìm thông tin mình cần tìm xem ở mục nào. Dễ hiểu quá đúng không ?
Index được tổ chức trong một cấu trúc có tên gọi là B-tree. Ngoài B-tree ra tất nhiên sẽ còn dạng thuật toán phức tạp khác. VD: Bitmap Indexes, Text Indexes. Nhưng trong bài viết này mình sẽ chia sẽ về B-tree nhé.
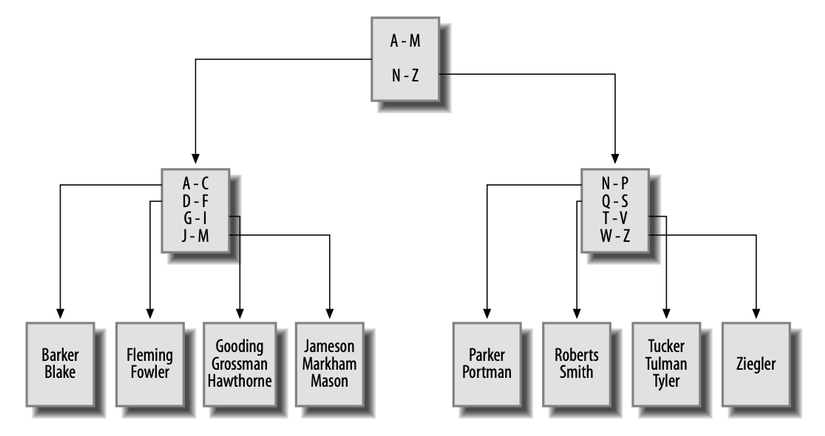
Như bạn có thể mong đợi, các B-tree Index được tổ chức dưới dạng cây, với một hoặc nhiều cấp độ nút nhánh dẫn đến một cấp độ nút lá duy nhất. Các nút nhánh được sử dụng để điều hướng cây, trong khi các nút lá giữ các giá trị thực và thông tin vị trí. Ví dụ: một Index B-tree được xây dựng trên cột employee.lname có thể trông giống như Hình
Nếu bạn đưa ra một truy vấn để truy xuất tất cả employees có họ bắt đầu bằng G, Server sẽ xem xét nút nhánh trên cùng (được gọi là nút gốc) và theo liên kết đến nút nhánh xử lý họ bắt đầu bằng A đến M. Đến lượt nó, nút nhánh này sẽ hướng máy chủ đến một nút lá chứa họ bắt đầu bằng G đến I. Sau đó, máy chủ bắt đầu đọc các giá trị trong nút lá cho đến khi nó gặp giá trị không bắt đầu bằng G ( mà, trong trường hợp này, là 'Hawthorne').
Khi các hàng được chèn, cập nhật và xóa khỏi bảng employee, Server sẽ cố gắng giữ cho cây cân bằng để không có nhiều nút nhánh / lá ở một bên của nút gốc hơn nút khác. có thể thêm hoặc xóa các nút nhánh để phân phối lại các giá trị đồng đều hơn và thậm chí có thể thêm hoặc xóa toàn bộ mức nút nhánh. Bằng cách giữ cho cây cân bằng, Server có thể di chuyển nhanh chóng đến các nút lá để tìm các giá trị mong muốn mà không cần phải điều hướng qua nhiều cấp độ của các nút nhánh.
3. Phân loại Index
Clustered Index : lưu trữ và sắp xếp dữ liệu vật lý trong table hoặc view dựa trên các giá trị khóa của chúng. Các cột khóa này được chỉ định trong định nghĩa index. Ví dụ mình có table như sau:
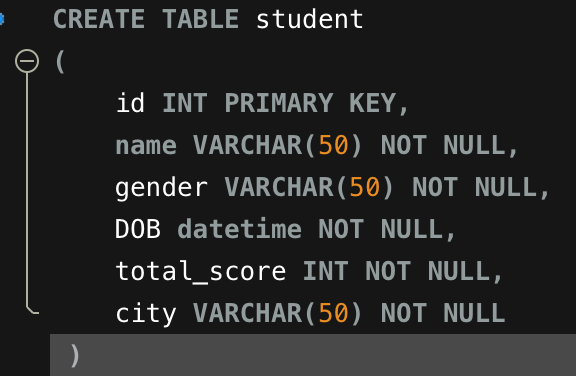
Lưu ý ở đây trong bảng "student", mình đã đặt ràng buộc khóa chính trên cột "id". Điều này tự động tạo một chỉ mục được phân nhóm trên cột "id". Để xem tất cả các chỉ mục trên một bảng cụ thể, hãy thực hiện thủ tục lưu trữ “sp_helpindex”.
EXECUTE sp_helpindex student
Kết quả trả về như sau : 
Trong kết quả trả về, bạn có thể thấy một chỉ mục duy nhất. Đây là chỉ mục được tạo tự động do ràng buộc khóa chính trên cột "id".
Non-Clustered Index : không sắp xếp dữ liệu vật lý bên trong bảng. Trên thực tế, một Index không phân cụm được lưu trữ ở một nơi và dữ liệu bảng được lưu trữ ở một nơi khác. Điều này tương tự như sách giáo khoa mà nội dung sách nằm ở một nơi và mục lục nằm ở nơi khác. Điều này cho phép nhiều hơn một Non-Clustered Index trên mỗi bảng. Cú pháp để tạo Non-Clustered Index đơn giản như sau:
CREATE NONCLUSTERED INDEX IX_TLBSTUDENT_NAME
ON student (name ASC)
Other type index : Theo một số tài liệu , còn có các kiểu Index như sau
- Unique Index : Khi thiết kế Database, điều quan trọng là phải xem xét cột nào được phép chứa dữ liệu trùng lặp và cột nào không. Unique Index được sinh ra để không cho phép chèn bất kỳ giá trị trùng lặp nào được chèn vào bảng. Cú pháp để tạo Unique Index :
CREATE UNIQUE INDEX index_name
ON TABLE(COLUMN 1, COLUMN 2, ...)
- Multicolumn Indexes (Composite Indexes) : là chỉ mục kết hợp dành cho hai hoặc nhiều cột trong một bảng. Cả hai kiểu index cơ sở là Clustered Index và Non Clustered Index cũng có thể đồng thời là là kiểu Composite index. Cú pháp để tạo Multicolumn Index:
CREATE INDEX index_name
ON TABLE(COLUMN 1, COLUMN 2, ...)
4. Mặt trái của Index
Đọc đến đây, chắc hẳn cũng có bạn sẽ thắc mắc rằng: Nếu index tuyệt vời như vậy, tại sao không make tất cả index?
- Chà, chìa khóa để hiểu tại sao nhiều chỉ mục không nhất thiết là một điều tốt là hãy nhớ rằng mọi chỉ mục đều là một bảng (một loại bảng đặc biệt, nhưng vẫn là một bảng). mỗi khi một hàng được thêm vào hoặc xóa khỏi bảng, tất cả các chỉ mục trên bảng đó phải được sửa đổi. Khi một hàng được cập nhật, bất kỳ chỉ mục nào trên cột hoặc các cột bị ảnh hưởng cũng cần được sửa đổi. Do đó, bạn càng có nhiều chỉ mục, máy chủ càng phải làm nhiều việc hơn để giữ cho tất cả các đối tượng lược đồ được cập nhật, điều này có xu hướng làm chậm mọi thứ (Index giúp tăng tốc các truy vấn SELECT chứa các mệnh đề WHERE hoặc ORDER, nhưng nó làm chậm việc dữ liệu nhập vào với các lệnh UPDATE và INSERT)
- Nếu bạn chỉ cần một index cho các mục đích đặc biệt, chẳng hạn như định kỳ bảo trì hàng tháng, bạn luôn có thể thêm chỉ mục, chạy quy trình, rồi giảm chỉ mục cho đến khi bạn cần lại.
5. Một số tip đánh index
- Đảm bảo rằng tất cả các cột khóa chính đều được lập index.
- Không nên sử dụng trong các bảng nhỏ, ít bản ghi.
- Hầu hết các cột ngày là những ứng cử viên tốt, cùng với các cột chuỗi ngắn (3 đến 50 ký tự).
- Không nên sử dụng Index trong bảng mà các hoạt động UPDATE, INSERT xảy ra thường xuyên với tần suất lớn.
- Không nên sử dụng cho các cột mà chứa một số lượng lớn giá trị NULL.
Chốt lại : Sau khi bạn đã xây dựng bộ index ban đầu của mình, hãy cố gắng nắm bắt các truy vấn thực tế dựa trên bảng của bạn và sửa đổi chiến lược lập chỉ mục của bạn để phù hợp với các đường dẫn truy cập phổ biến nhất. Đối với khóa chính nhiều cột, hãy xem xét việc tạo chỉ mục bổ sung trên một tập hợp con của các cột khóa chính hoặc trên tất cả các cột khóa chính nhưng theo thứ tự khác với định nghĩa ràng buộc khóa chính.
Tài liệu tham khảo: Cuốn sách Learning SQL của Alan Beaulieu tái bản lần 2.
Link download : https://www.pdfdrive.com/learning-sql-e17131012.html