Chào các bạn, hôm nay tôi sẽ cùng các bạn tìm hiểu và sử dụng mô hình học máy hết sức phổ biến là Support Vector Machine để giải quyết bài toán phân loại các hạt thóc  .
.
Trước khi đi chi tiết vào nội dung bài thì tôi đố các bạn phân biệt được 3 hạt thóc ở ảnh phía dưới đây thuộc những loại thóc nào 

Vâng nếu bạn nào đoán đây là 3 loại thóc khác nhau thì sai rồi nhé  . Đây là 3 hạt thóc của cùng một loại lúa đó là BQ10. Bạn nào đoán sai thì cũng ko sao. Ta cùng đi vào một ví dụ nữa nhé
. Đây là 3 hạt thóc của cùng một loại lúa đó là BQ10. Bạn nào đoán sai thì cũng ko sao. Ta cùng đi vào một ví dụ nữa nhé 

Hình trên thì có vẻ dễ dàng hơn rồi  . Thôi không để các bạn phải đoán nữa thì đây là 3 hạt thóc của ba giống lúa khác nhau, lần lượt từ trái qua phải là BC15, BQ10 và NH92.
. Thôi không để các bạn phải đoán nữa thì đây là 3 hạt thóc của ba giống lúa khác nhau, lần lượt từ trái qua phải là BC15, BQ10 và NH92.
Trong bài hôm nay tôi sẽ cùng các bạn dùng mô hình SVM để phân loại hạt thóc của 3 giống lúa này nhé 
Lý thuyết về Support Vector Machine
Support Vector Machine là một thuật toán học máy có giám sát (Supervised Learning) dùng để phân chia dữ liệu thành các nhóm riêng biệt.
Trong nội dung bài này chủ yếu là thử nghiệm nên tôi sẽ không đề cập đến lý thuyết của nó nữa. Tuy nhiên tôi highly recommend các bạn nên đọc các bài viết sau đây để có cái nhìn rõ hơn về SVM nhé.
- Support Vector Machine trong học máy - Một cái nhìn đơn giản hơn
- Ứng dụng Support Vector Machine trong bài toán phân loại hoa
Hai bài viết trên là của Tác giả Phạm Văn Toàn, bạn có thể ghé đọc những bài viết hết sức tâm huyết về nhiều các bài toán trong lĩnh vực AI của anh Toàn nhé.
Chuẩn bị dữ liệu
Trong bài viết này tôi sử dụng dữ liệu hạt thóc của 3 giống lúa BC15, BQ10 và NH92 như đã đề cập ở phía trên. Data và code các bạn có thể lấy ở github cá nhân của tôi ở đây.
Để thuận tiện cho việc thống kê số lượng samples của từng class tôi sử dụng hàm dưới đây:
dataDir='./data/'
classes=['BC15', 'BQ10', 'NH92'] def statistic(dataDir): label = [] num_images = [] for lab in os.listdir(dataDir): label.append(lab) files=os.listdir(os.path.join(dataDir, lab)) c=len(files) num_images.append(c) return label, num_images
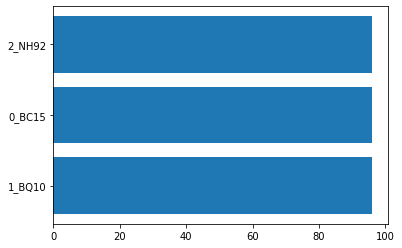
Sau khi chạy qua hàm tôi thu được kết quả thống kê như sau:
labels, num_images = statistic(dataDir)
print(labels)
print(num_images)
['1_BQ10', '0_BC15', '2_NH92']
[96, 96, 96]
Tập dữ liệu mà tôi sử dụng gồm 3 class, số lượng samples của mỗi class là 96 ảnh.
Để có cái nhìn trực quan hơn về số lượng tôi sử dụng matplotlib để
y_pos = np.arange(len(labels))
plt.barh(y_pos, num_images, align='center')
plt.yticks(y_pos, labels)
plt.show()
Phân chia thành tập train và tập test
Sau quá trình thống kê dữ liệu, tôi sẽ chia dữ liệu thành 2 tập Train và Test theo tỉ lệ quen thuộc 70% cho train và 30% cho test. Để chia dữ liệu thành 2 tập thì tôi định nghĩa hàm dưới đây:
def LoadData(dataDir,new_size=None): if not new_size is None: img_rows, img_cols = new_size classes=[] for _,dirs,_ in os.walk(dataDir): classes=dirs break num_classes=len(classes) ValidPercent=30 X_tr=[] Y_tr=[] X_te=[] Y_te=[] for idx,cl in enumerate(classes): for _,_,files in os.walk(dataDir+cl+'/'): l=len(files) for f in files: r=np.random.randint(100) img_path=dataDir+cl+'/'+f img=cv.imread(img_path) img = cv.cvtColor(img, cv.COLOR_BGR2RGB) if not new_size is None: img=cv.resize(img,(img_rows,img_cols)) if (r>ValidPercent): X_tr.append(img) Y_tr.append(int(cl[0])) else: X_te.append(img) Y_te.append(int(cl[0])) return X_tr, Y_tr, X_te, Y_te
Sau khi chia train test qua hàm trên thì số lượng dữ liệu cho mỗi tập là:
- Train: 201 ảnh
- Tetst: 87 ảnh
Dưới đây là một số ảnh trong tập train: các nhãn 0, 1, 2 tương ứng với giống lúa BC15, BQ10, NH92.

Huấn luyện và đánh giá
Quá trình huấn luyện cũng như phân loại khi sử dụng SVM về cơ bản sẽ có các bước như hình dưới đây:

- Bước 1: Tiền xử lý ảnh đầu vào.
- Bước 2: Trích xuất đặc trưng của ảnh.
- Bước 3: Đưa đặc trưng vừa trích xuất qua SVM để tiến hành phân loại.
Ở trong bước 2 có rất nhiều các phương pháp dùng để trích xuất đặc trưng của ảnh đầu vào. Nghe đến trích xuất đặc trưng thì các bạn có thể liên tưởng đến việc sử dụng một mô hình CNN để trích xuất ra những đặc trưng (deep features), và rồi dùng các đặc trưng đã trích xuất dựa trên CNN để đưa vào SVM nhằm mục đích phân loại thì kỹ thuật này gọi là Transfer Learning.
Ngoài việc sử dụng đặc trưng trích xuất từ CNN thì còn rất nhiều các kỹ thuật khác như trích xuất đặc trưng HOG(Histogram of Oriented Gradients) , đặc trưng về màu sắc của đối tượng ....
Trong bài hôm nay tôi sẽ sử dụng 2 đặc trưng là HOG và Color histogram
Sử dụng đặc trưng HOG
Sơ qua chút lý thuyết về HOG, HOG hay Histogram of Oriented Gradients là một thuật toán để trích xuất thuộc tính hình ảnh.Bản chất của phương pháp HOG là sử dụng thông tin về sự phân bố của các cường độ gradient (intensity gradient) hoặc của hướng biên (edge directions) để mô tả các đối tượng cục bộ trong ảnh.
Để biết thêm chi tiết về HOG và cách tính toán ra đặc trưng HOG thì các bạn đọc bài này nhé Tìm hiểu về phương pháp mô tả đặc trưng HOG (Histogram of Oriented Gradients)
Trích xuất đặc trưng
Sau khi đã hình dung được HOG là gì thì sau đây tôi sẽ định nghĩa 1 hàm dùng để trích xuất đặc trưng HOG từ ảnh đầu vào
from skimage.feature import hog
# Định nghĩa hàm trích đặc trưng cho từng ảnh
def get_hog_features(img, orient=8, pix_per_cell=16, cell_per_block=4,vis=False, feature_vec=True): if vis == True: features, hog_image = hog(img, orientations=orient, pixels_per_cell=(pix_per_cell, pix_per_cell), cells_per_block=(cell_per_block, cell_per_block), transform_sqrt=True, visualize=vis, feature_vector=feature_vec,multichannel=True) return features, hog_image else: # Otherwise call with one output features = hog(img, orientations=orient, pixels_per_cell=(pix_per_cell, pix_per_cell), cells_per_block=(cell_per_block, cell_per_block), transform_sqrt=True, visualize=vis, feature_vector=feature_vec, multichannel=True) return features
Giải thích qua một chút về hàm trích xuất đặc trưng HOG ở trên thì trong hàm này tôi sử dụng luôn hàm hog của thư viện skimage, chi tiết về hàm này thì các bạn xem docs ở đây.
Các bạn có thể để ý trong hàm này tôi sủ dụng biến bool vis để lựa chọn trả về ảnh đặc trưng HOG cùng với vector đặc trưng hoặc chỉ trả về vector đặc trưng.
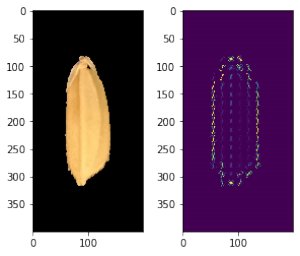
Nếu vis=True thì sẽ nhận được cái ảnh HOG kiểu như hinh dưới đây (bên trái là ảnh gốc, bên phải là ảnh HOG)
Rồi ok, sau khi đã định nghĩa hàm trích xuất đặc trưng, tôi sẽ sử dụng hàm này để trích xuất và lưu lại đặc trưng của tập train và test bằng đoạn code dưới đây
#trích đặc trưng cho tập train và test
feat_train=[]
for img in img_train: gray = cv.cvtColor(img, cv.COLOR_RGB2GRAY) feat_HOG=get_hog_features(gray) feat_train.append(feat_HOG) feat_test=[]
for img in img_test: gray = cv.cvtColor(img, cv.COLOR_RGB2GRAY) feat_HOG=get_hog_features(gray) feat_test.append(feat_HOG) # chuyên qua kiểu numpy
X_hog_tr=np.array(feat_train)
Y_tr=np.array(label_train)
X_hog_te=np.array(feat_test)
Y_te=np.array(label_test) Huấn luyện và phân loại bằng SVM
Đến bước này thì việc của chúng ta khá là đơn giản, chỉ cần định nghĩa ra mô hình SVM và sau đó đưa dữ liệu vào để huấn luyện thôi. Sử dụng đoạn code dưới đây để huấn luyện nhé các bạn.
from sklearn.svm import SVC, LinearSVC
model_svm = SVC(kernel="linear", C=1.0)
model_svm.fit(X_hog_tr,Y_tr)
Quá trình huấn luyện SVM cũng rất nhanh chỉ trong vài giây thôi là bạn đã có được mô hình SVM rồi. Trong thử nghiệm lần này thì tôi dùng SVM với kernel là linear.
Sau quá trình huấn luyện, tôi test thử độ chính xác trên tập test và thu được kết quả
y_predict = model_svm.predict(X_hog_te)
print ('Độ chính xác: ',model_svm.score(X_hog_te,Y_te))
Độ chính xác: 0.7528089887640449
Độ chính xác phân loại khi sử dụng đặc trưng HOG đạt đc là 75% cũng ko quá cao phải không nào. Vậy tiếp theo ta sẽ sử dụng một đặc trưng khác xem thế nào nhé.
Sử dụng đặc trưng Color Histogram
Đối với xử lý ảnh số nói chung thì Color Histogram là biểu đồ thể hiện số lượng các pixel trong các dải màu khác nhau của ảnh.
Lấy một ví dụ như hai hình dưới đây biểu đồ màu đen ở hình dưới chính là sự thể hiện Color Histogram của hình con mèo ở trên

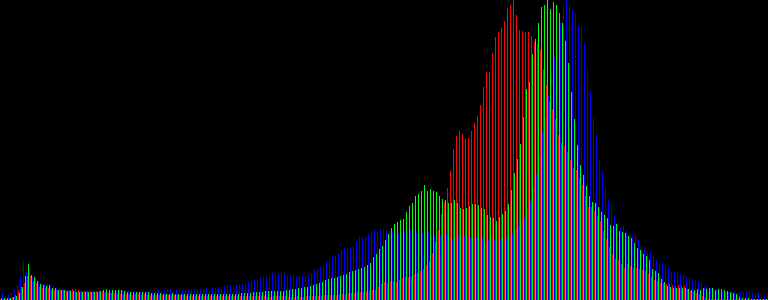
Biểu đồ này là sự thể hiện số lượng các pixel trong ảnh của ba kênh màu RGB trong các mức xám khác nhau của ảnh (đối với ảnh số thì thường các mức xám nằm từ 0-255 tương đương với 8 bits)
Trích xuất đặc trưng
Cũng giống như HOG, với đặc trưng Color Histogram tôi cũng định nghĩa ra một hàm trích xuất như sau:
def fd_histogram(image,bins=16, mask=None): # convert the image to HSV color-space img_hsv = cv.cvtColor(image, cv.COLOR_RGB2HSV) # compute the color histogram hist = cv.calcHist([img_hsv], [0, 1, 2], None, [bins, bins, bins], [0, 256, 0, 256, 0, 256]) # normalize the histogram cv.normalize(hist, hist) # return the histogram return hist.flatten()
Từng bước hoạt động của quá trình trích xuất đặc trưng này cũng đã được tôi comment ở đoạn code trên.
Sau đó ta dùng hàm trên để trích xuất đặc trưng từ các tập dữ liệu train và test thông qua hàm:
#trích đặc trưng cho tập train và test
bins=16
feat_train=[]
for img in img_train: feat_chis=fd_histogram(img,bins) feat_train.append(feat_chis) feat_test=[]
for img in img_test: feat_chis=fd_histogram(img,bins) feat_test.append(feat_chis) # chuyên qua kiểu numpy
X_his_tr=np.array(feat_train)
X_his_te=np.array(feat_test)
Y_tr=np.array(label_train)
Y_te=np.array(label_test)
Huấn luyện và phân loại bằng SVM
Phần này cũng tương tự như phần huấn luyện bằng đặc trưng HOG:
from sklearn.svm import SVC
model_svm = SVC(kernel="linear", C=1.0)
model_svm.fit(X_his_tr,Y_tr)
Sau đó test thử độ chính xác trên tập Test
y_predict = model_svm.predict(X_his_te)
print ('Độ chính xác: ',model_svm.score(X_his_te,Y_te))
Độ chính xác: 0.29591836734693877
 Độ chính xác khi phân loại sử dụng đặc trưng Color Histogram khá tệ so với khi sử dụng đặc trưng HOG. Nguyên nhân có thể do ba loại hạt thóc đều có màu chủ đạo là màu vàng cho nên đặc trưng khi trích xuất ra cũng sẽ gần gần giống nhau do vậy mô hình SVM sẽ khó học được trên tập dữ liệu với những đặc trưng như vậy
Độ chính xác khi phân loại sử dụng đặc trưng Color Histogram khá tệ so với khi sử dụng đặc trưng HOG. Nguyên nhân có thể do ba loại hạt thóc đều có màu chủ đạo là màu vàng cho nên đặc trưng khi trích xuất ra cũng sẽ gần gần giống nhau do vậy mô hình SVM sẽ khó học được trên tập dữ liệu với những đặc trưng như vậy  .
.
Kết luận
Đến đây là hết rồi . Qua bài này tôi đã cùng các bạn sử dụng SVM để giải quyết một bài toán khá thú vị là phân loại hạt thóc. Các bạn có thể thấy việc lựa chọn đặc trưng cho các thuật toán học máy có giám sát (Unsupervised learning) là khá quan trọng, nó ảnh hưởng rất lớn đến chất lượng mô hình (như trong bài này là sự khác biệt khi lựa chọn giữa đặc trưng HOG và đặc trưng Color Histogram).
Và tất nhiên bài toán phân loại thóc trong bài này chỉ mang tính chất thử nghiệm, dữ liệu cho bài toán khá đẹp với những hạt thóc được đặt trong nền đen tránh được các ảnh hưởng do nền khi trích xuất đặc trưng. Và trong thực tế thì chả ai làm như thế này cả mang vài hạt thóc đến hỏi các bác nông dân sẽ nhanh hơn .
Hi vọng với thử nghiệm vui vui này các bạn sẽ học được một chút gì đó!
Và không còn gì chia sẻ cả, hy vọng các bạn đã đọc bài viết này và thấy thú vị thì đừng ngại ngần đề lại cho tôi một Upvote hoặc Comment góp ý nhé  .
.